





Python对象比较与拷贝深度解析:is vs == + 深浅拷贝陷阱实战(含mermaid图解)
前言
在Python开发中,你是否遇到过这些困惑:a == b为True但a is b为False?拷贝对象后修改却意外影响原对象?这些问题本质是对Python对象的"身份、值、内存"三者关系的误解。
本文从底层原理出发,拆解is与==的核心差异、赋值/浅拷贝/深拷贝的本质区别,结合mermaid图解和实战代码,帮你彻底避开拷贝陷阱,写出健壮代码!
一、对象比较:is 与 == 的本质区别
Python中比较对象有两个核心操作符,看似相似,实则底层逻辑完全不同——is比身份,==比价值。
1. 核心定义与关键代码
(1)is:身份标识比较(内存地址对比)
is判断两个变量是否指向同一个对象,等价于比较id()返回的内存地址:
a = 10
b = 10
c = 257
d = 257
print(a == b) # True(值相等)
print(a is b) # True(小整数缓存,同一对象)
print(c == d) # True(值相等)
print(c is d) # False(超出缓存范围,不同对象)
# is 等价于 id()比较
print(id(a) == id(b)) # True
print(id(c) == id(d)) # False
(2)==:值相等比较(调用__eq__方法)
==判断两个对象的值是否等价,通过调用对象的__eq__方法实现,支持自定义逻辑:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
# 自定义相等规则:姓名和年龄相同即相等
return isinstance(other, Person) and self.name == other.name and self.age == other.age
p1 = Person("Alice", 25)
p2 = Person("Alice", 25)
print(p1 == p2) # True(值相等)
print(p1 is p2) # False(不同对象)
2. 核心差异mermaid图解

3. 特殊场景:小整数缓存与字符串驻留
Python对常用对象做了缓存优化,减少内存分配:
- 小整数缓存:
-5~256范围内的整数复用同一对象; - 字符串驻留:纯字母数字的短字符串自动驻留(复用对象)。
# 字符串驻留示例
s1 = "hello_python"
s2 = "hello_python"
print(s1 is s2) # True(驻留机制)
s3 = "hello-python" # 含特殊字符,不驻留
s4 = "hello-python"
print(s3 is s4) # False
4. 最佳实践
- 检查
None必须用is:if x is None(None是单例对象); - 比较值相等用
==:if user_input == "quit"; - 避免用
is比较可变对象:列表、字典等可变对象无缓存机制,is比较无意义。
二、对象拷贝:赋值、浅拷贝、深拷贝的本质
拷贝是创建对象副本的过程,但Python中"拷贝"并非都能实现"完全独立"——赋值是引用,浅拷贝只拷贝外层,深拷贝才是彻底独立。
1. 赋值(不是拷贝):共享同一对象
赋值只是给原对象起"别名",新变量与原变量指向同一内存地址,修改任一都会影响对方。
关键代码与内存图解
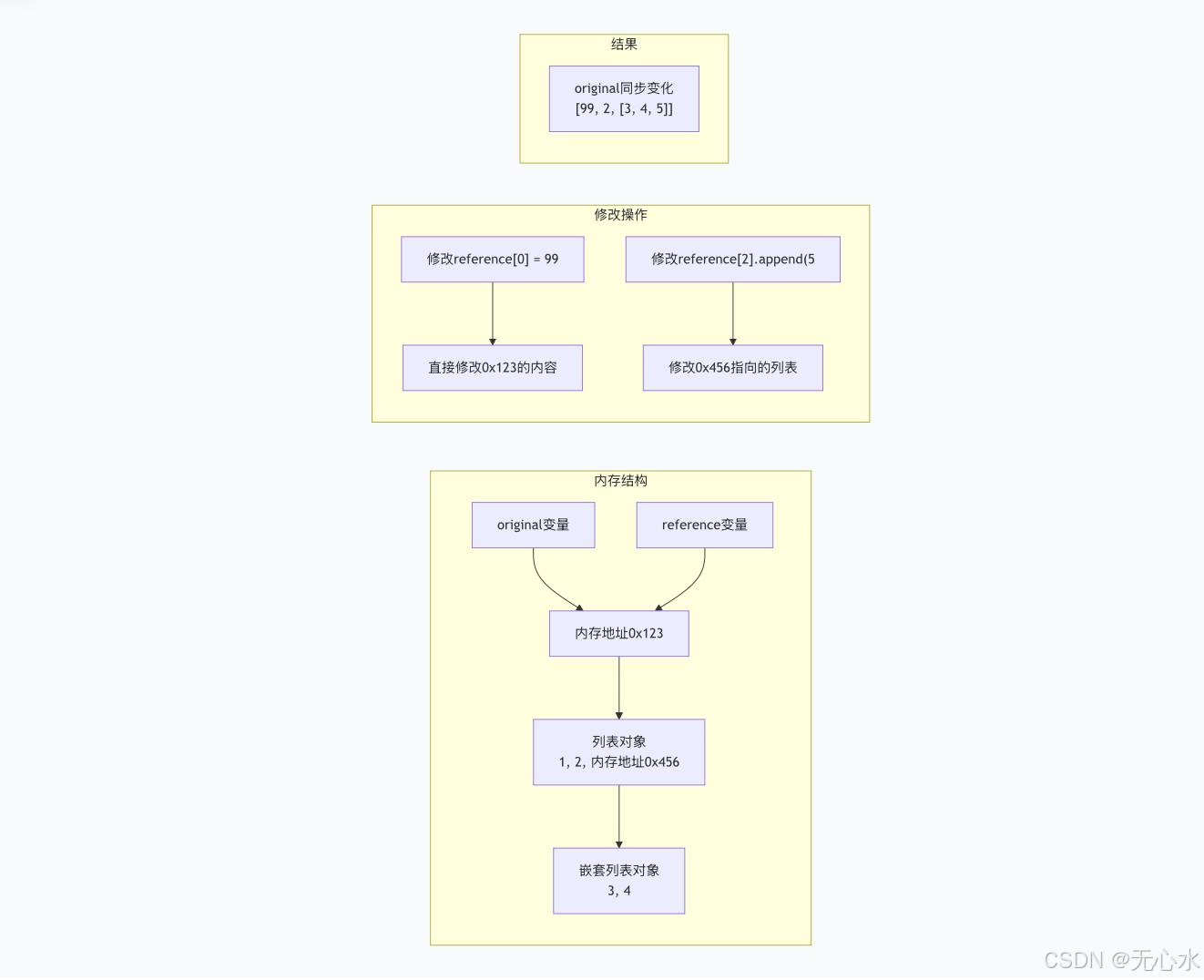
original = [1, 2, [3, 4]]
reference = original # 赋值=引用,非拷贝
reference[0] = 99
reference[2].append(5)
print(original) # [99, 2, [3, 4, 5]](原对象被修改)
2. 浅拷贝(Shallow Copy):拷贝外层,共享内层
浅拷贝创建新的容器对象,但容器内的元素仍引用原对象——修改顶层元素不影响原对象,修改嵌套元素会影响原对象。
关键代码与内存图解
import copy
original = [1, 2, [3, 4]]
# 常见浅拷贝方式:copy.copy()、切片、构造函数
shallow = copy.copy(original) # 或 original[:]、list(original)
# 修改顶层元素(不影响原对象)
shallow[0] = 99
print(original) # [1, 2, [3, 4]](无变化)
# 修改嵌套元素(影响原对象)
shallow[2].append(5)
print(original) # [1, 2, [3, 4, 5]](被修改)

3. 深拷贝(Deep Copy):完全独立的副本
深拷贝递归拷贝所有层级的对象,新对象与原对象彻底独立,任何修改都不会相互影响,还能处理循环引用。
关键代码与内存图解
import copy
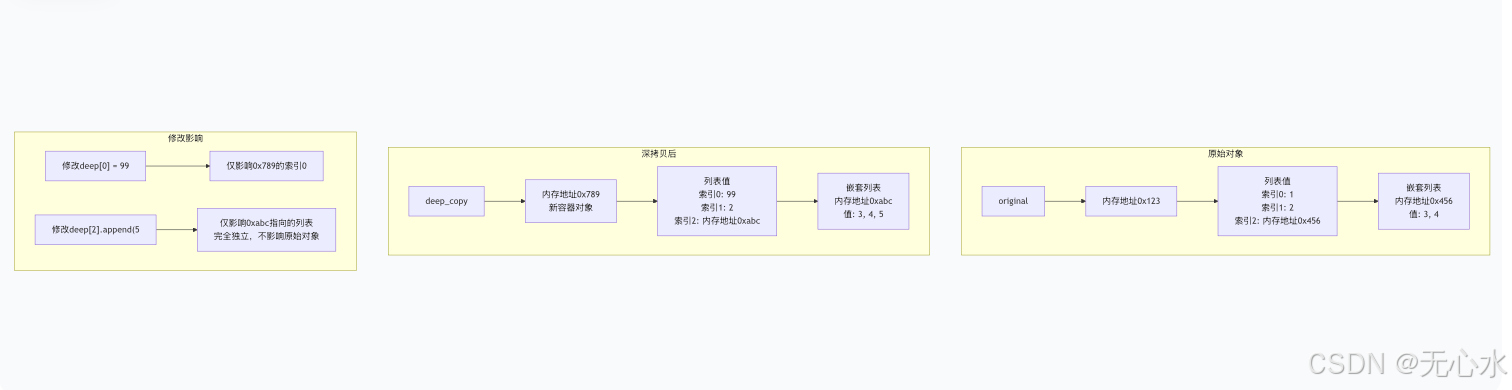
original = [1, 2, [3, 4]]
deep = copy.deepcopy(original)
# 修改顶层和嵌套元素(均不影响原对象)
deep[0] = 99
deep[2].append(5)
print(original) # [1, 2, [3, 4]](无变化)
print(deep) # [99, 2, [3, 4, 5]](独立变化)
# 处理循环引用(深拷贝专属优化)
x = [1]
x.append(x) # 循环引用:x = [1, [1, [1, ...]]]
y = copy.deepcopy(x) # 正常执行,无递归溢出
print(y) # [1, [...]]
4. 三种方式核心对比表
| 拷贝方式 | 对象本身 | 嵌套对象 | 适用场景 | 实现方式 |
|---|---|---|---|---|
| 赋值 | 共享 | 共享 | 需修改原对象(如函数传参) | a = b |
| 浅拷贝 | 新建 | 共享 | 顶层修改,嵌套不变 | copy.copy()、切片、构造函数 |
| 深拷贝 | 新建 | 新建 | 完全独立(如防御性编程) | copy.deepcopy() |
三、不可变对象的拷贝特殊性
元组、字符串、数字等不可变对象,拷贝行为与可变对象不同——浅拷贝和深拷贝都会返回原对象(无需复制,共享安全)。
关键代码
import copy
# 元组(不可变对象)
t = (1, 2, [3, 4]) # 含可变嵌套元素
shallow_t = copy.copy(t)
deep_t = copy.deepcopy(t)
print(shallow_t is t) # True(浅拷贝返回原对象)
print(deep_t is t) # False(深拷贝创建新元组,嵌套元素也新建)
# 修改嵌套列表(深拷贝不影响原对象)
deep_t[2].append(5)
print(t) # (1, 2, [3, 4])(无变化)
核心原因:不可变对象无法修改顶层结构,共享不会有安全问题,拷贝反而浪费内存——Python优化为直接返回原对象。
四、实战陷阱与最佳实践
1. 常见陷阱
(1)浅拷贝嵌套对象修改陷阱
# 陷阱:浅拷贝后修改嵌套字典,影响原对象
config = {"debug": True, "db": {"host": "localhost"}}
shallow_config = config.copy()
shallow_config["db"]["host"] = "dev-server"
print(config["db"]["host"]) # "dev-server"(原配置被意外修改)
# 解决方案:用深拷贝
import copy
deep_config = copy.deepcopy(config)
deep_config["db"]["host"] = "prod-server"
print(config["db"]["host"]) # "dev-server"(无影响)
(2)循环中深拷贝性能陷阱
# 陷阱:循环中频繁深拷贝大对象,性能极差
big_data = {"data": [i for i in range(1000)]}
for _ in range(1000):
copy.deepcopy(big_data) # 重复深拷贝,耗时严重
# 解决方案:提前深拷贝一次,或用浅拷贝(若无需修改嵌套)
2. 最佳实践清单
- 优先用浅拷贝:大多数场景下,浅拷贝性能更高,满足需求;
- 深拷贝用于嵌套可变对象:如字典套字典、列表套列表,需完全独立时使用;
- 不可变对象无需拷贝:直接引用,无需
copy(); - 函数传参防修改:若函数内要修改参数,先浅拷贝/深拷贝,避免影响外部数据;
- 缓存场景用深拷贝:存储数据到缓存时,深拷贝避免原始数据修改导致缓存失效。
五、总结:拷贝选择决策树

Python对象的比较与拷贝,核心是理清"身份、值、内存"的关系:is比身份,==比价值;赋值是共享,浅拷贝半独立,深拷贝全独立。掌握这些原理,就能避开90%的开发陷阱,写出更高效、健壮的Python代码。
如果在实际开发中遇到拷贝导致的"灵异问题",欢迎在评论区留言交流!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











