



首先装环境
先装scrapegraphai
在Terminal窗口输入如下命令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn scrapegraphai
上面的装完以后到装下面的,同样也是在Terminal 窗口输入如下命令
playwright install
装好后,新建一个py文件,敲图上的代码
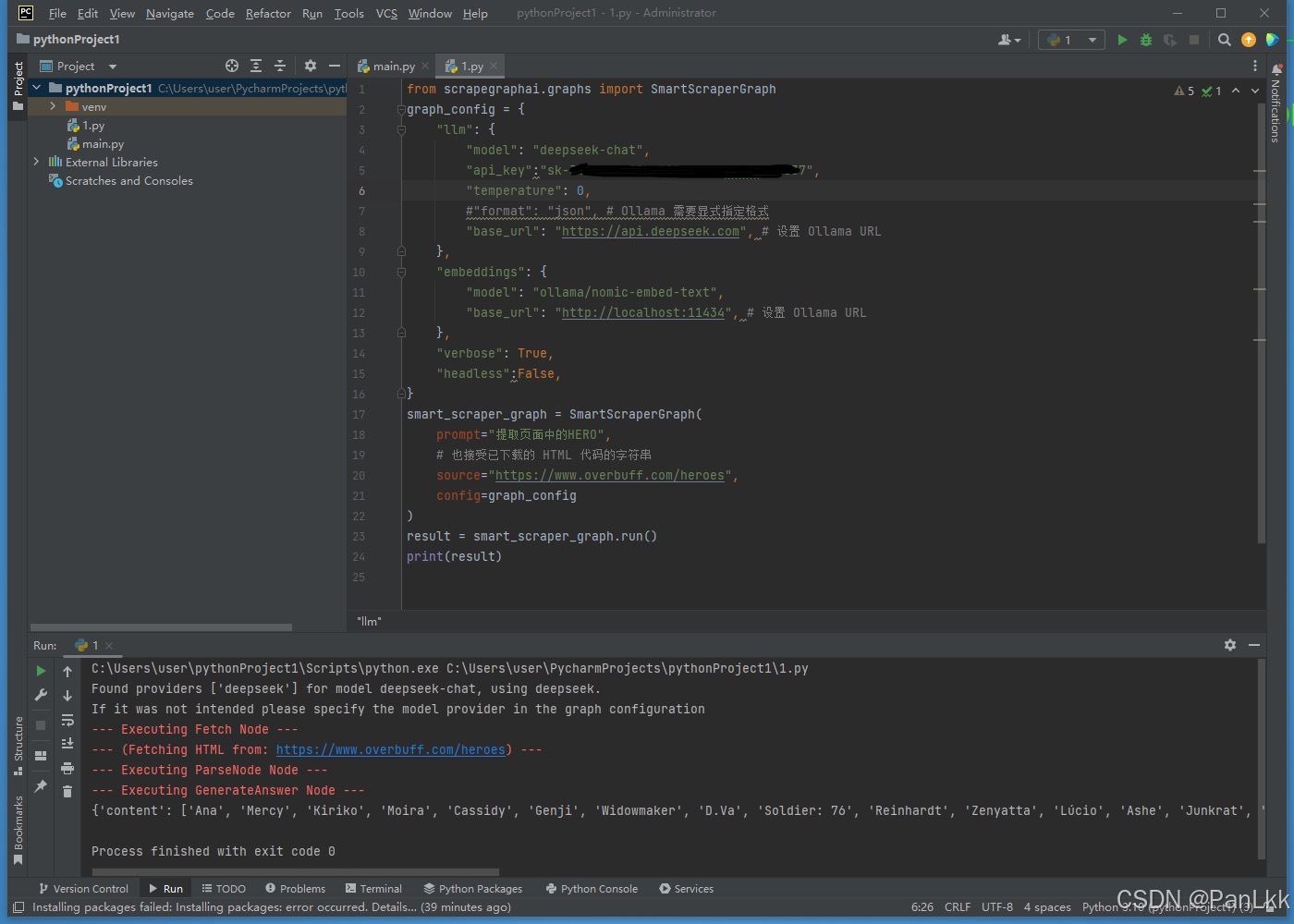
说一下几个需要改的参数
api_key:这个要去买才行,我买的是deepseek的,买了直接复制就行
第一个base_url:用deepseek的
第二个base_url:在Ollama 上复制的一个模型的url
prompt:你想要哪个内容就告诉它,比如说我要的是下面这个页面的hero
source :就是你要爬取的目标页面的链接
都改好参数了以后直接运行就好,运行成功后会输出一串content ,核对一下就是我需要的hero名字

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









