 大数据基础与平台架构解析
大数据基础与平台架构解析





 本文介绍了大数据的基础,重点讲解了Hadoop及其组件,包括HDFS、MapReduce/Spark和Pig/Hive。探讨了大数据平台的层级结构,如ODS层、数据仓库和数据应用层,并详细阐述了数据埋点、指标字典和数据管理系统的重要性。内容涵盖了数据存储、处理、分析和质量管理等多个方面。
本文介绍了大数据的基础,重点讲解了Hadoop及其组件,包括HDFS、MapReduce/Spark和Pig/Hive。探讨了大数据平台的层级结构,如ODS层、数据仓库和数据应用层,并详细阐述了数据埋点、指标字典和数据管理系统的重要性。内容涵盖了数据存储、处理、分析和质量管理等多个方面。
日期:2022年7月24日
内容:第四章数据仓库理论与应用(p77-p104)
4.1 了解大数据基础Hadoop
一、Hadoop及三驾马车
01.什么是hadoop?
Hadoop是一个分布式系统基础架构,现在被广泛地应用于大数据平台的开发,对处理海量数据有着其他技术无可匹敌的优势。

[可以简单认为Hadoop=HDFS+MapReduce/spark+Pig/Hive]
02.三驾马车

二.HDFS:数据的存储
1.前提数据需要被储存起来,例如储存在成千上万台机器存储
2.用户在前端,看到的只是一个"文件系统",而非多个
3.
HDFS
会集中管理数据,用户
只需要把精力花费在如何使用和处理数据上,不需要了解"数据储存在哪里"
[那么有效、快速地处理数据呢?]——>MapReduce/Spark
三.MapReduce/Spark:数据的处理
01.扮演的角色:
1.任务的分配者丨给并行处理任务的计算机分配的任务更加合理
2.跑路的通信员丨并负责任务之间的通信
3.数据的交换者丨以及数据交换等工作
02.处理数据的基本逻辑
MapReduce
会把所有的函数都分为两类,即
Map
和
Reduce
。
Map
会将数据分成很多份,然后分配给不同的机器处理;
Reduce
把计算的结果合并,得到最终的结果。
三、Pig/Hive数据的封装
01.什么是封装?
02.pig和hive

四、补充
01.现在的发展:现在的Hadoop已经从上面提到的Hadoop三驾马车逐渐发展为60多个相关组件构成的庞大生态家族,其中在各大发行版中就包含30多个组件,包含了数据框架、数据存储和执行引擎等。
02.现今流行的,两个“大数据处理框架”Hadoop 和Spark:
1.Spark、Spark MLib、Spark GraphX和Spark Streaming组成了Spark 生态圈,其余部分组成了Hadoop生态圈组。
2.这两个框架之间的关系并不是互斥的,它们之间既有合作、补充,同时又存在竞争。
例如,Spark提供的实时内存计算,会比Hadoop中的MapReduce速度更快。但是由于 Hadoop更加广泛地应用于存储,Spark也会依赖HDFS
存储数据。
3.虽然Spark可以基于其他系统搭建实现,但也正是因为它与Hadoop之间的这种互相补充的关系,所以Spark
和
Hadoop
经常搭配在一起使用。
五、其他基础工具介绍:
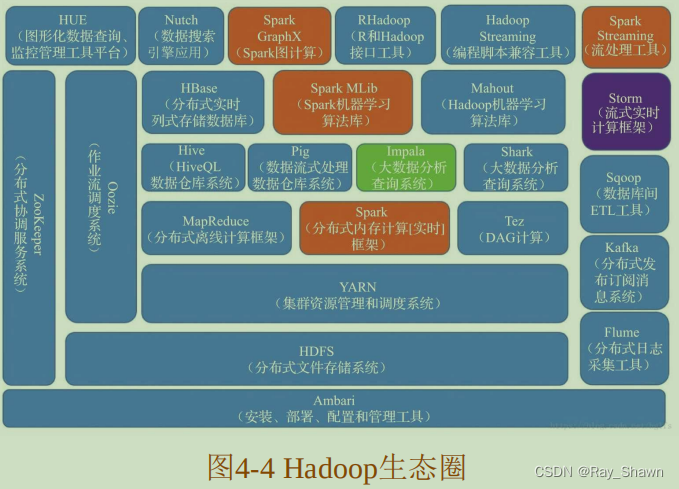
(1)
Spark
。
Spark
是一个开源的集群计算环境,上文也讲了,
Spark
与
Hadoop
之间既相互补充,又相互竞争。
Spark
启用了内存分布数
据集,在处理某些工作负载方面表现得更加优越,交互也会更加友好。
(2)
Kafka
。
Kafka
是一种高吞吐量的分布式发布订阅消息系统,
它可以处理各大网站或者
App
中用户的动作流数据。用户行为数据是后
续进行业务分析和优化的重要数据资产,这些数据通常以处理日志和日
志聚合的方式解决。
Kafka集群上的消息是有时效性的,可以对发布上来的消息设置一
个过期时间,不管有没有被消费,超过过期时间的消息都会被清空。例
如,如果过期时间设置为一周,那么消息发布上来一周内,它们都是可
以被消费的,如果过了过期时间,这条消息就会被丢弃以释放更多空
间。
(3)
Storm
。
Storm
主要应用于分布式数据处理,包括实时分析、
在线机器学习、信息流处理、连续性的计算、
ETL
等。
Storm
还可以应
用于实时处理,被称为实时版的
Hadoop
,每秒可以处理百万级的消息,
并且
Storm
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









