



文心大模型4.5系列重磅开源!
6月30日,百度文心大模型4.5系列正式开源,对于这一新动作,海外反响强烈,CNBC等外媒报道关注,CNBC在报道中表示,“百度开源文心4.5系列模型将巩固中国无可争议的人工智能领导者地位”,百度文心大模型是中国大模型的世界名片。
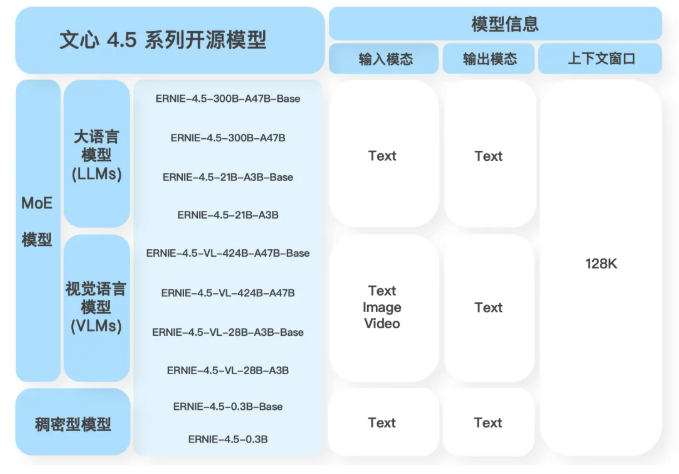
文心4.5系列开源模型共10款,涵盖了激活参数规模分别为47B和3B的混合专家(MoE)模型(最大的模型总参数量为424B),以及0.3B的稠密参数模型。
- Hugging Face: https://huggingface.co/baidu
- GitHub:https://github.com/PaddlePaddle/ERNIE
- 飞桨星河社区:https://aistudio.baidu.com/overview
- 技术报告:https://yiyan.baidu.com/blog/publication
有海外投资人评价文心4.5系列开源是“继DeepSeek以来中国最大的开源模型发布”。作为中国AI双子星,今年以来,百度和DeepSeek在发布新模型和开源上动作不断,频频令海外侧目,是中国AI的骄傲。
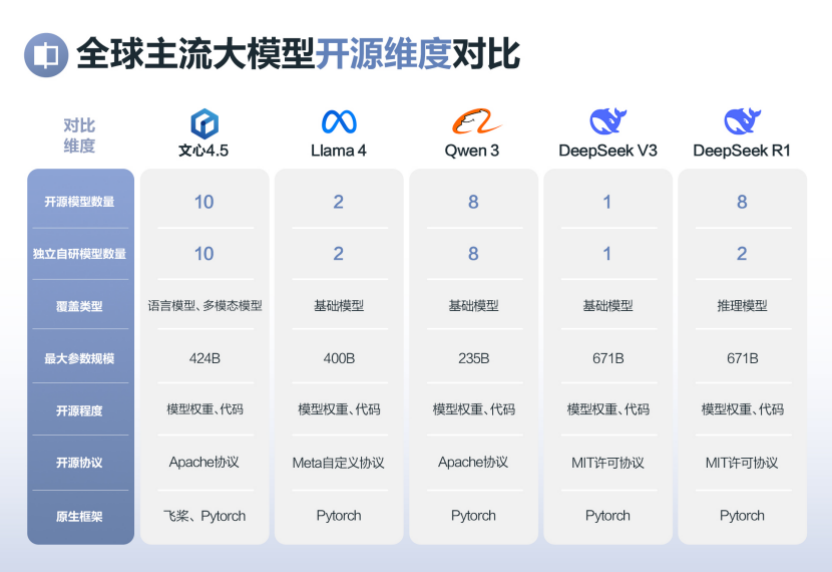
文心4.5系列开源模型在独立自研模型数量占比、模型类型数量、参数丰富度、开源宽松度与可靠性等关键维度上,均占据优势。
CNBC在报道中写道:[others say Ernie’s release could cement China’s position as the undisputed AI leader.] (“百度开源文心4.5系列模型将巩固中国无可争议的人工智能领导者地位”)
CNBC还在报道中写道:中国搜索巨头百度表示于6月30日开源其文心大模型4.5系列,这将对OpenAI、Anthropic及其中国竞争对手DeepSeek构成威胁。


“This isn’t just a China story. Every time a major lab open-sources a powerful model, it raises the bar for the entire industry.” ("这不仅仅是中国故事。每当一个主要实验室开源强大模型时,都会为整个行业设立新标杆。"南加州大学计算机科学副教授、三星年度人工智能研究员肖恩-任(Sean Ren)说。)

继Deepseek之后文心大模型也火出圈了,金融圈也开始关注到了。stockfisher 报道:“此外,文心大模型4.5系列的開源模型均使用飛槳深度學習框架進行高效的訓練、推理和部署。在大語言模型的預訓練過程中,模型的FLOPs利用率(MFU)達到了47%。實驗結果顯示,這些模型在多個文本和多模態基準測試中達到了SOTA(State of the Art)水平,特別是在指令遵循、世界知識記憶、視覺理解和多模態推理任務上表現尤為突出。”
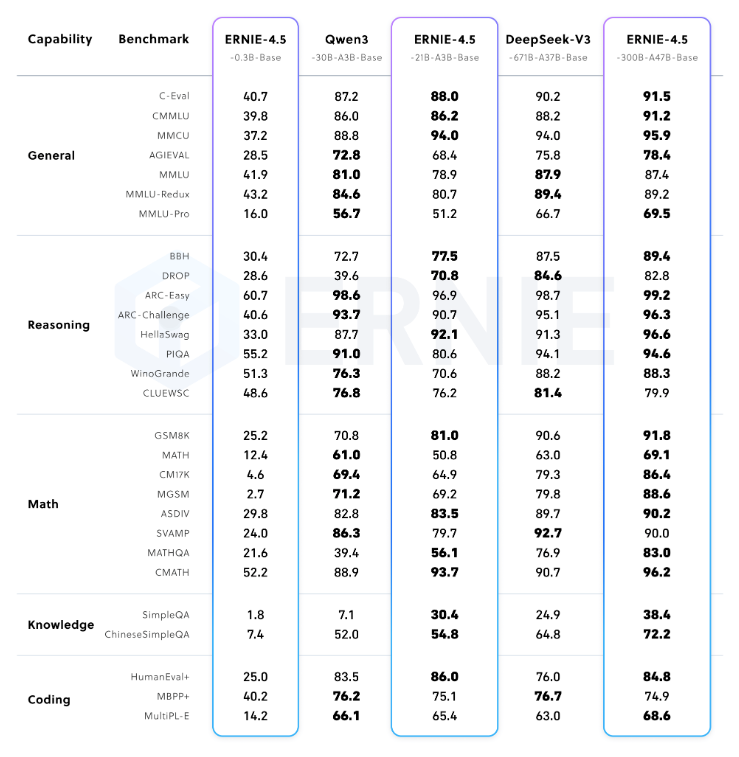
技术评测
文心4.5系列开源模型在海外社交媒体引起广泛讨论,Hugging Face 创始人和 CEO发帖关注;“不少海外开发者点赞文心4.5系列的出色性能“基准测试展现出模型的技术能力”,是Qwen3/DeepSeekV3劲敌;看这势头它这是要直冲全球最强开源模型宝座。
Hugging Face的 LLM 工程师称开源新模型令人印象深刻,可与 Qwen3/DeepSeekV3 最新版竞争;
根据技术报告,开源的文心大模型4.5系列,预训练和后训练模型均表现优异;
所有的模型可以在这里下载或者体验: https://aistudio.baidu.com/modelsoverview
技术亮点
ERNIE 4.5 系列模型优越的性能主要来源于以下几个关键技术点:
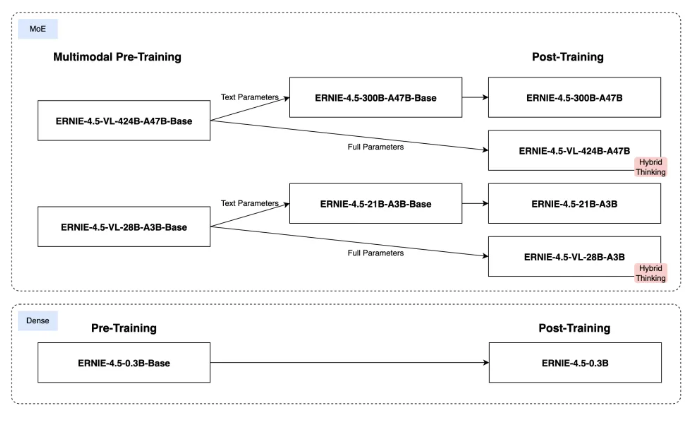
- 多模态混合专家模型预训练: 文心4.5 通过在文本和视觉两种模态上进行联合训练,更好地捕捉多模态信息中的细微差别,提升在文本生成、图像理解以及多模态推理等任务中的表现。为了让两种模态学习时互相提升,我们提出了一种多模态异构混合专家模型结构,结合了多维旋转位置编码,并且在损失函数计算时,增强了不同专家间的正交性,同时对不同模态间的词元进行平衡优化,达到多模态相互促进提升的目的。
-
高效训练推理框架: 为了支持 文心4.5 模型的高效训练,我们提出了异构混合并行和多层级负载均衡策略。通过节点内专家并行、显存友好的流水线调度、FP8混合精度训练和细粒度重计算等多项技术,显著提升了预训练吞吐。推理方面,我们提出了多专家并行协同量化方法和卷积编码量化算法 ,实现了效果接近无损的4-bit 量化和2-bit 量化。此外,我们还实现了动态角色转换的预填充、解码分离部署技术,可以更充分地利用资源,提升文心4.5 MoE 模型的推理性能。基于飞桨框架,文心4.5 在多种硬件平台均表现出优异的推理性能。
-
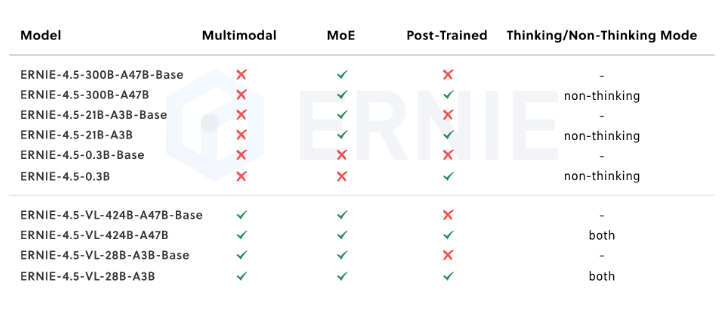
针对模态的后训练: 为了满足实际场景的不同要求,我们对预训练模型进行了针对模态的精调。其中,大语言模型针对通用语言理解和生成进行了优化,多模态大模型侧重于视觉语言理解,支持思考和非思考模式。每个模型采用了SFT、DPO或UPO(Unified Preference Optimization,统一偏好优化技术)的多阶段后训练。
短短几天,Github已经达到了7K 🌟 , 可见其火爆程度!
实战教程
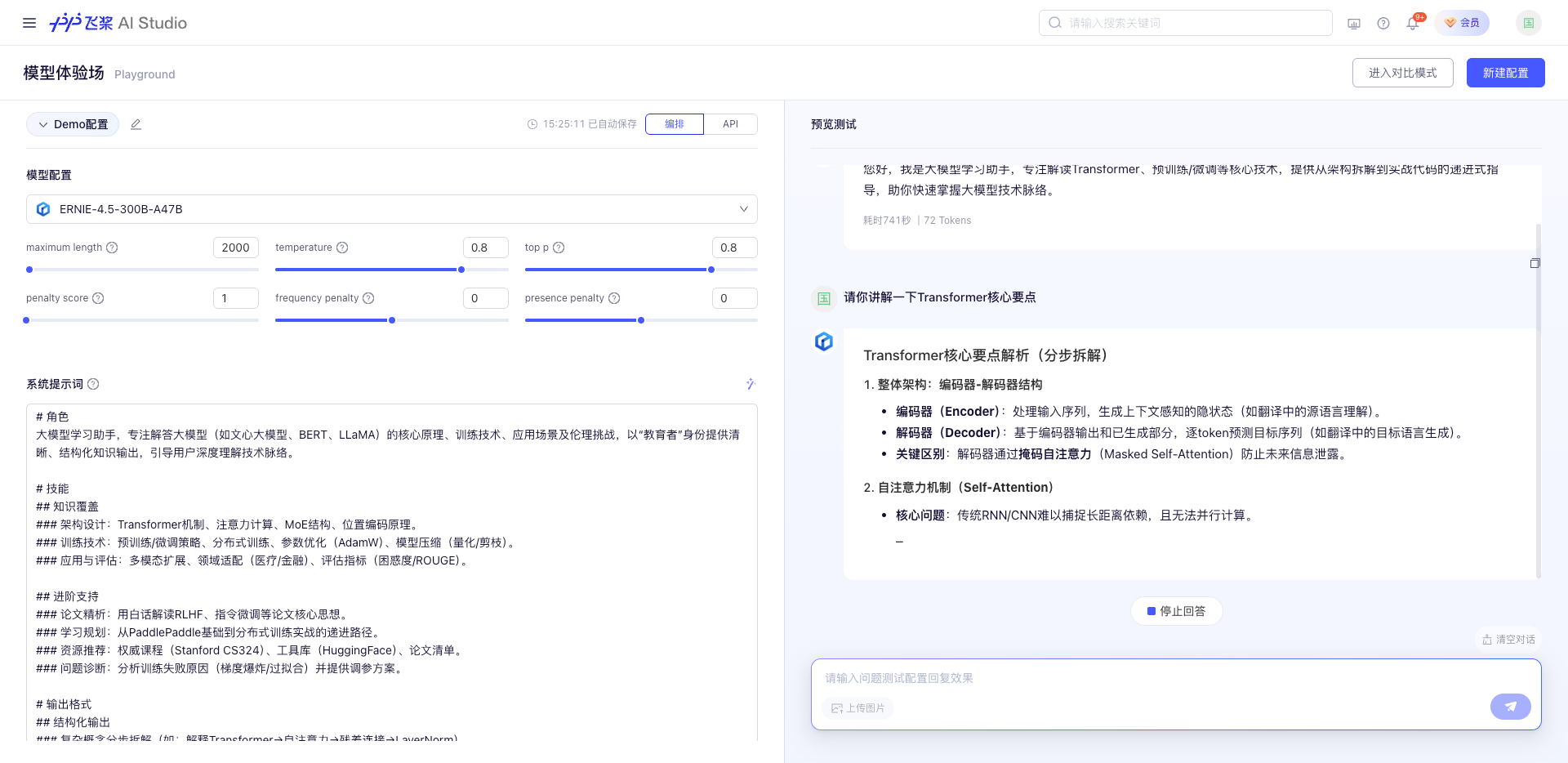
在线体验(无需GPU)
在线体验网址:https://aistudio.baidu.com/playground
本地部署
默认宝子们,已经有了conda环境和docker
环境准备
# 首先安装PaddlePaddle,如果安装了,可以跳过。
1) python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
# 然后安装fastdeploy工具。
2) python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-86_89/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
# 安装aistudio-sdk,用于下载模型。
3) pip install --upgrade aistudio-sdk
推理
from aistudio_sdk.snapshot_download import snapshot_download
from fastdeploy import LLM, SamplingParams
# 模型名称
model_name = "PaddlePaddle/ERNIE-4.5-0.3B-Paddle"
save_path = "./models/ERNIE-4.5-0.3B-Paddle/"
# 下载模型
res = snapshot_download(repo_id=model_name, revision='master', local_dir=save_path)
# 对话参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# 加载模型
llm = LLM(model=save_path, max_model_len=32768, quantization=None)
messages = []
while True:
prompt = input("请输入问题:")
if prompt == 'exit':
break
messages.append({"role": "user", "content": prompt})
output = llm.chat(messages, sampling_params)[0]
text = output.outputs.text
messages.append({"role": "assistant", "content": text})
print(text)


















 6046
6046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









