




综述
ControlNet
-
https://arxiv.org/pdf/2302.05543
-
控制模块的公式

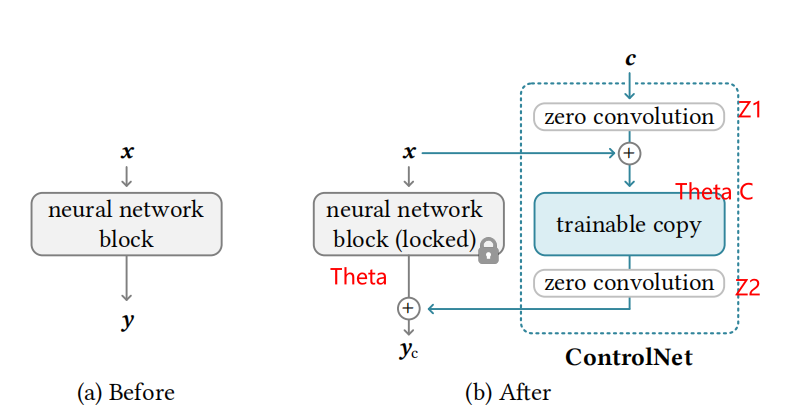
Zero Convlution
- 在初始阶段,去除梯度的噪音的影响

- 问题:没有学习控制条件,反而学习输入的图像学的很好 -》 突然收敛现象
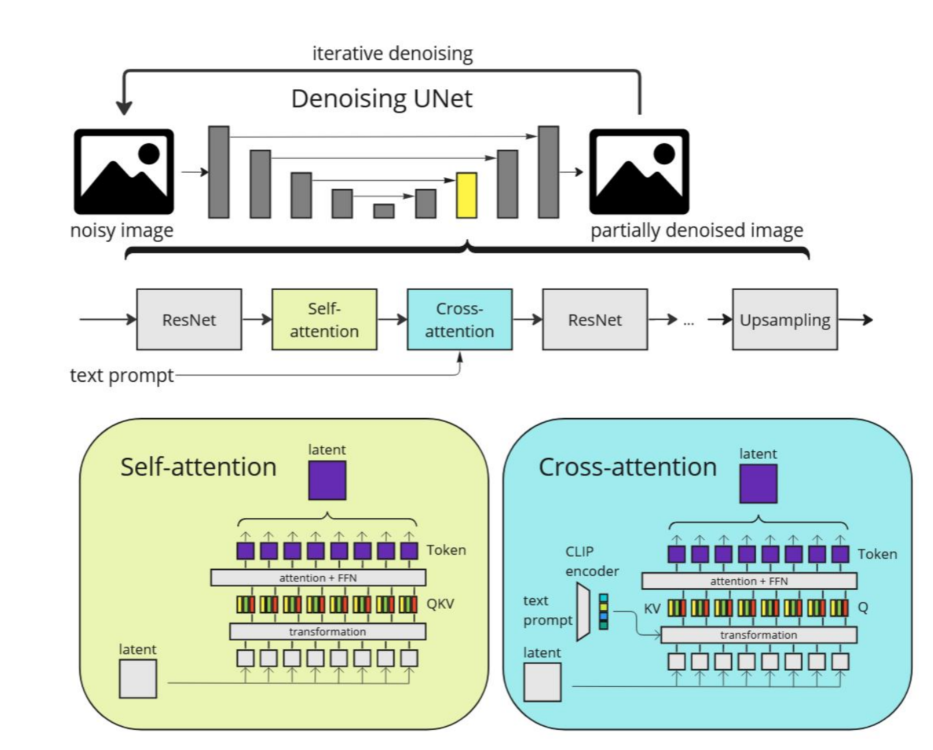
U-Net结构
- a U-Net with an encoder, a middle block, and a skip-connected decoder.
- Both the encoder and decoder contain 12 blocks, and the full model contains 25 blocks, including the middle block. (文本用Clip encoder,时间步用timestep position embeding encoder)
- Of the 25 blocks, 8 blocks are down-sampling or up-sampling convolution layers, while the other 17 blocks are main blocks that each contain 4 resnet layers and 2 Vision Transformers (ViTs).
- Each ViT contains several cross attention and self-attention mechanisms
animatediff
- https://arxiv.org/pdf/2302.05543
LVDM
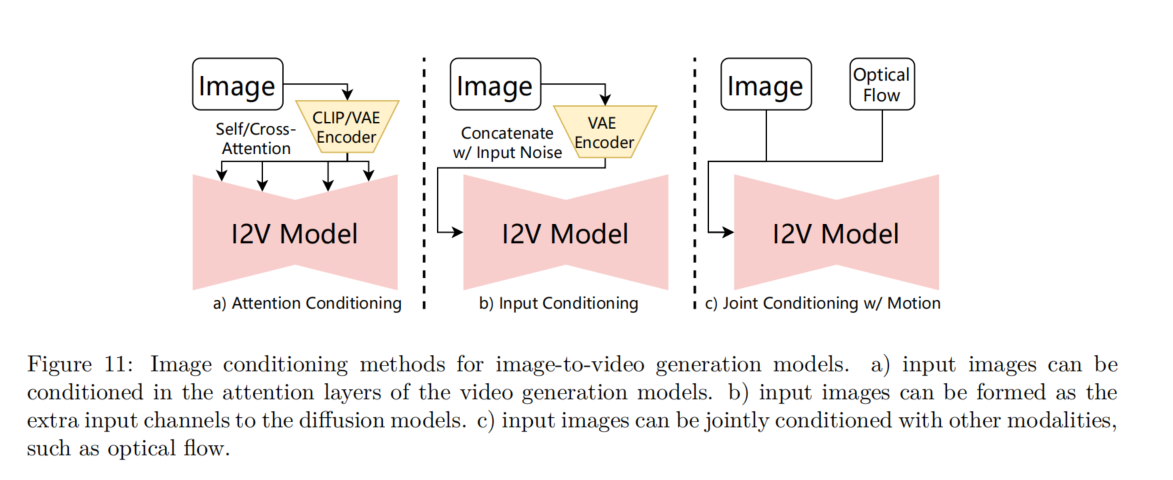
MagicDance
主要工作:
提出了一种两阶段训练策略来解开人类动作和外观(例如面部表情、肤色和着装)
(1)外观控制块的预训练, 通过Multi-Source Attention Module提供从参考图像到 SD 的外观指导
(2)学习外观分离的姿势控制, Pose ControlNet,根据条件图像提供姿势/表情指导
任务目标:在保持身份不变的情况下,通过控制姿势和面部表情来生成一个人的新图像
任务定义:给定一张图像
当其中有一个人时,MagicPose 的目标是将给定图像中的人重新调整为目标姿势 {P,F}
(1)从参考图像中保留和传输人类个体和背景的外观
(2)外观控制模型来进行姿势和表情控制生成的图像
模块详细设计
- 多源注意力的设计

- 外观控制的Loss设计

- 外观和姿势一起微调的Loss

使用的工具
- OpenPose 实现人体骨骼检测
- 逐帧 FID 、SSIM 、LPIPS 、PSNR 、L1、Face-Cos(脸部余弦相似度)
VideoCrafter2
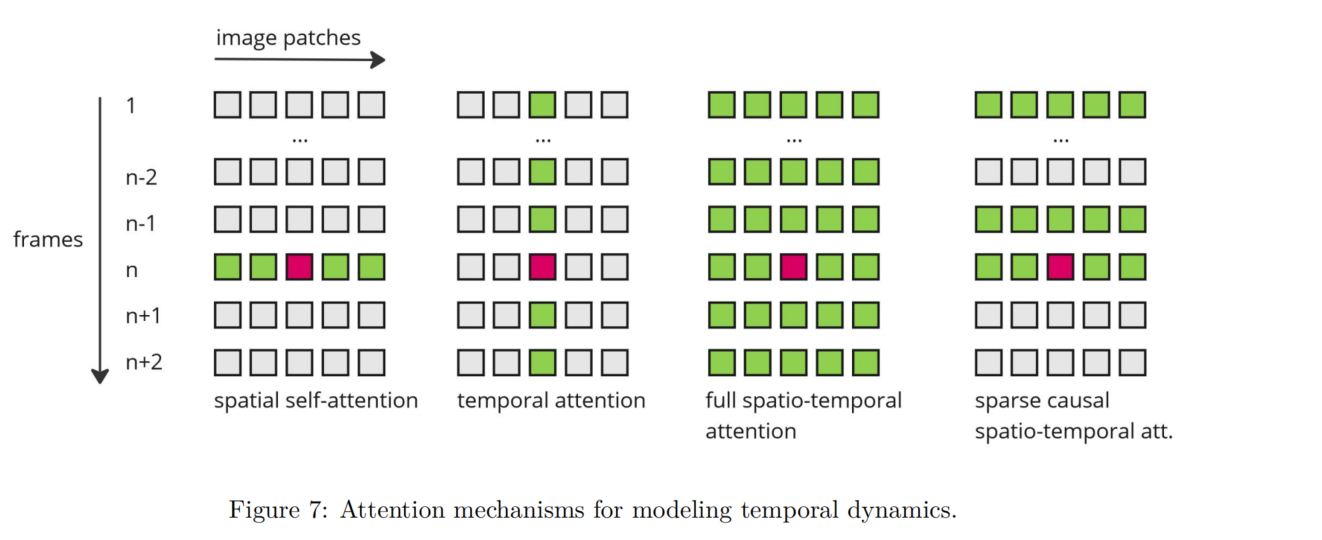
时空模块的训练结论:
- 完全训练模型的空间模块和时间模块之间的耦合强度强于部分训练模型。因为部分训练模型的时空耦合很容易被打破,导致快速的运动退化和图像质量的变化。较强的连接比较弱的连接更能容忍参数的扰动。我们的观察可以用来解释动物差异的质量改善和运动退化。
- 动画差异不是一个通用的模型,只适用于选定的个性化SD模型。其原因是其运动模块是通过部分训练策略获得的,且不能容忍较大的参数扰动。当个性化模型与时间模块不匹配时,图像和运动质量都会退化。
- 时间模块不仅负责运动,而且负责图像质量。
数据侧面解决外观和运动:
- 在数据层面上将运动与外观分离,即从低质量的视频中学习运动,同时从高质量的图像中学习图像质量和美学。我们可以首先用视频训练一个视频模型,然后用图像对视频模型进行微调。
关键在于如何训练一个视频模型,以及如何用图像来调整它。
- 在空间和时间的扰动中,图像质量可以提高,但不是很显著。
为了获得更大的质量改进,我们评估了两种策略。
- 一是涉及更多的参数,即用图像来微调空间和时间模块。
- 另一种是改变微调方法,即使用不使用LORA的直接微调。
用高质量的图像直接微调空间模块是在不边际损失运动质量的情况下提高图像质量的最佳方法。
结论:首先用低质量视频完全训练视频模型,然后用高质量图像直接进
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5375
5375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









