




 这篇博客介绍了如何利用Python的Pandas库检查数据集中的缺失值。通过`df.isnull()`进行元素级别判断,`df.isnull().any()`进行列级别检查,`df[df.isnull().values==True]`定位缺失值位置,以及`isnull().sum()`统计缺失值数量。同时提到了计算缺失率的方法,并给出了相关资源链接。
这篇博客介绍了如何利用Python的Pandas库检查数据集中的缺失值。通过`df.isnull()`进行元素级别判断,`df.isnull().any()`进行列级别检查,`df[df.isnull().values==True]`定位缺失值位置,以及`isnull().sum()`统计缺失值数量。同时提到了计算缺失率的方法,并给出了相关资源链接。
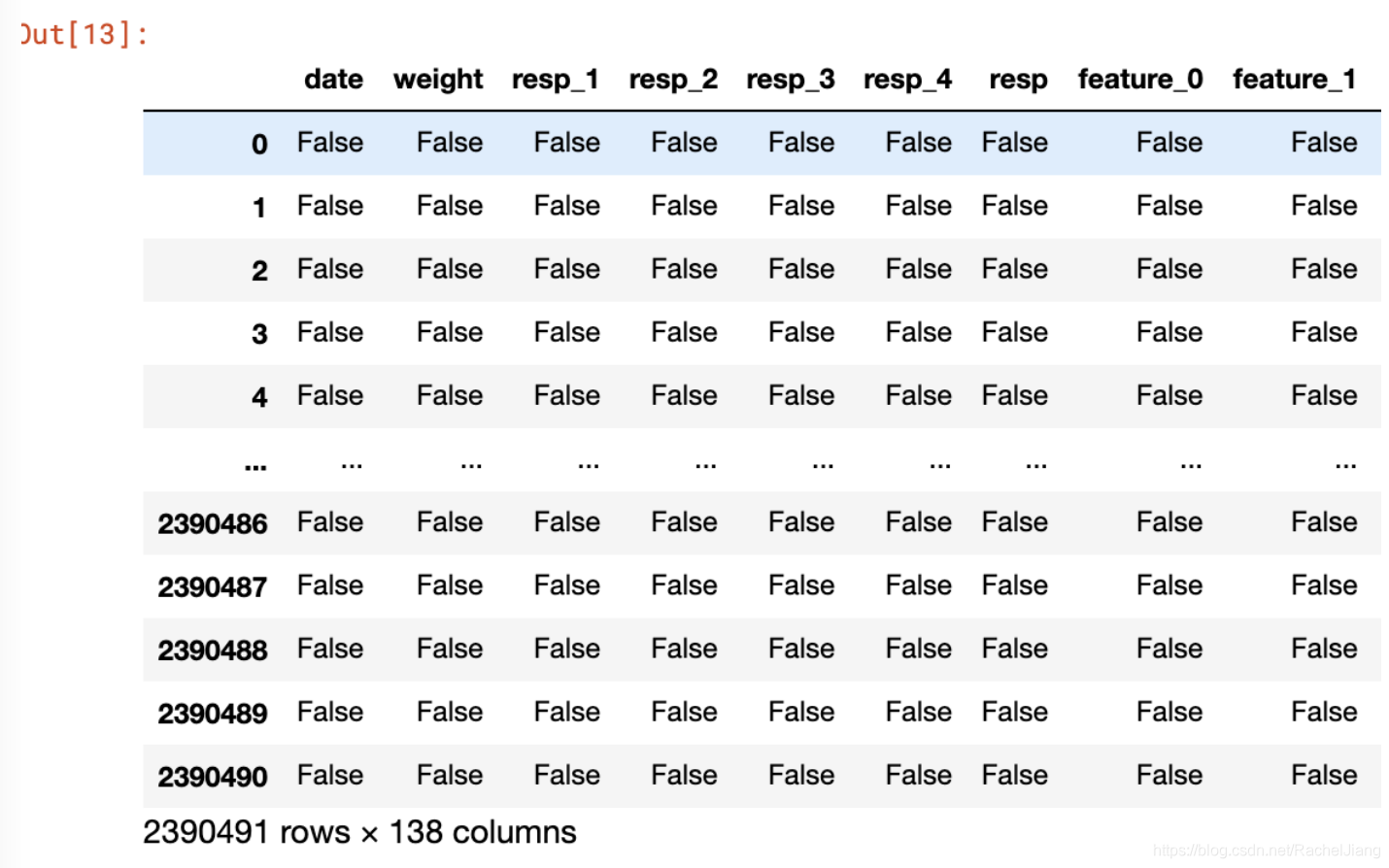
1.df.isnull()
元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True,否则就是False
train.isnull()
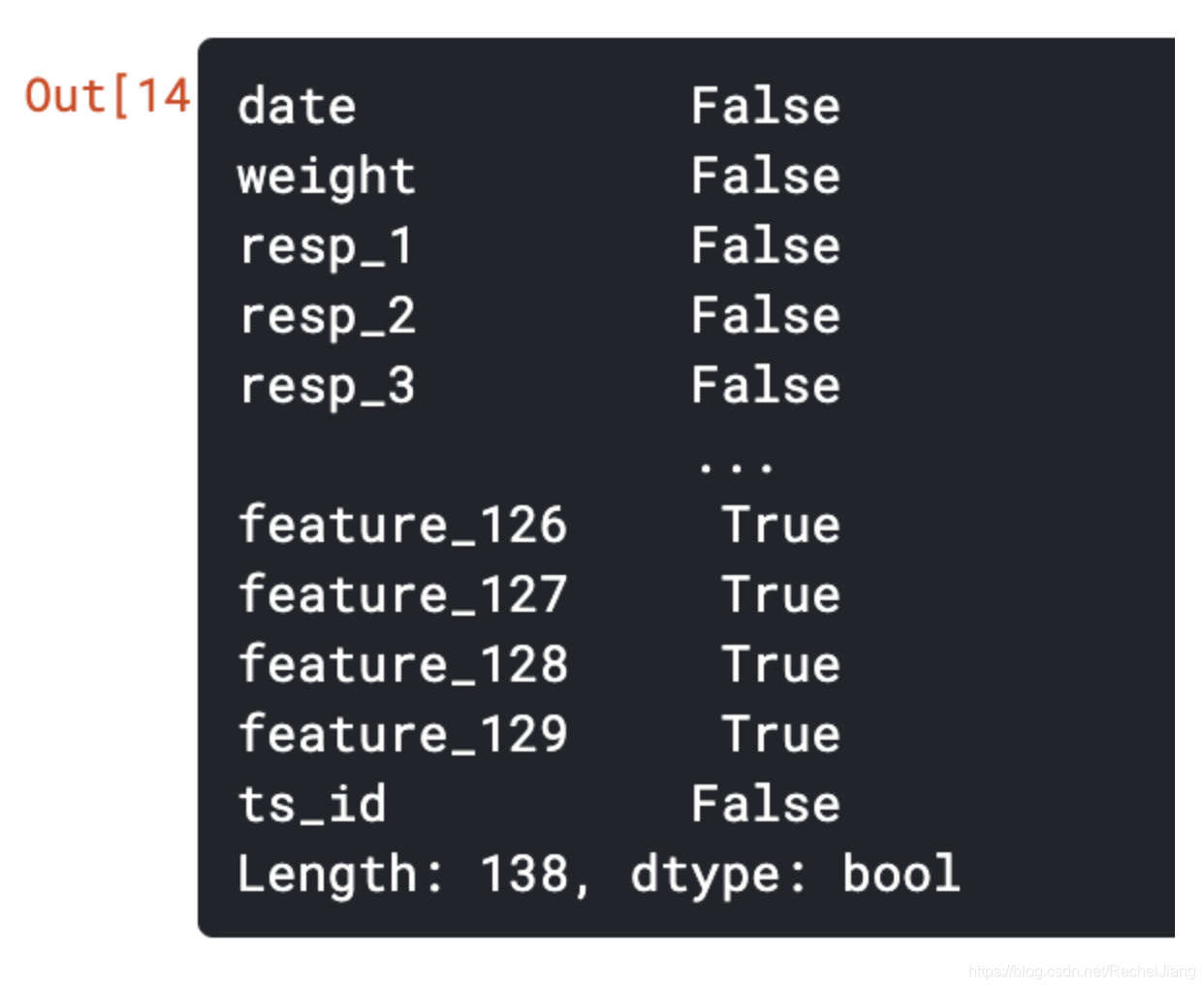
2,df.isnull().any()
列级别的判断,只要该列有为空或者NA的元素,就为True,否则False
train.isnull().any()
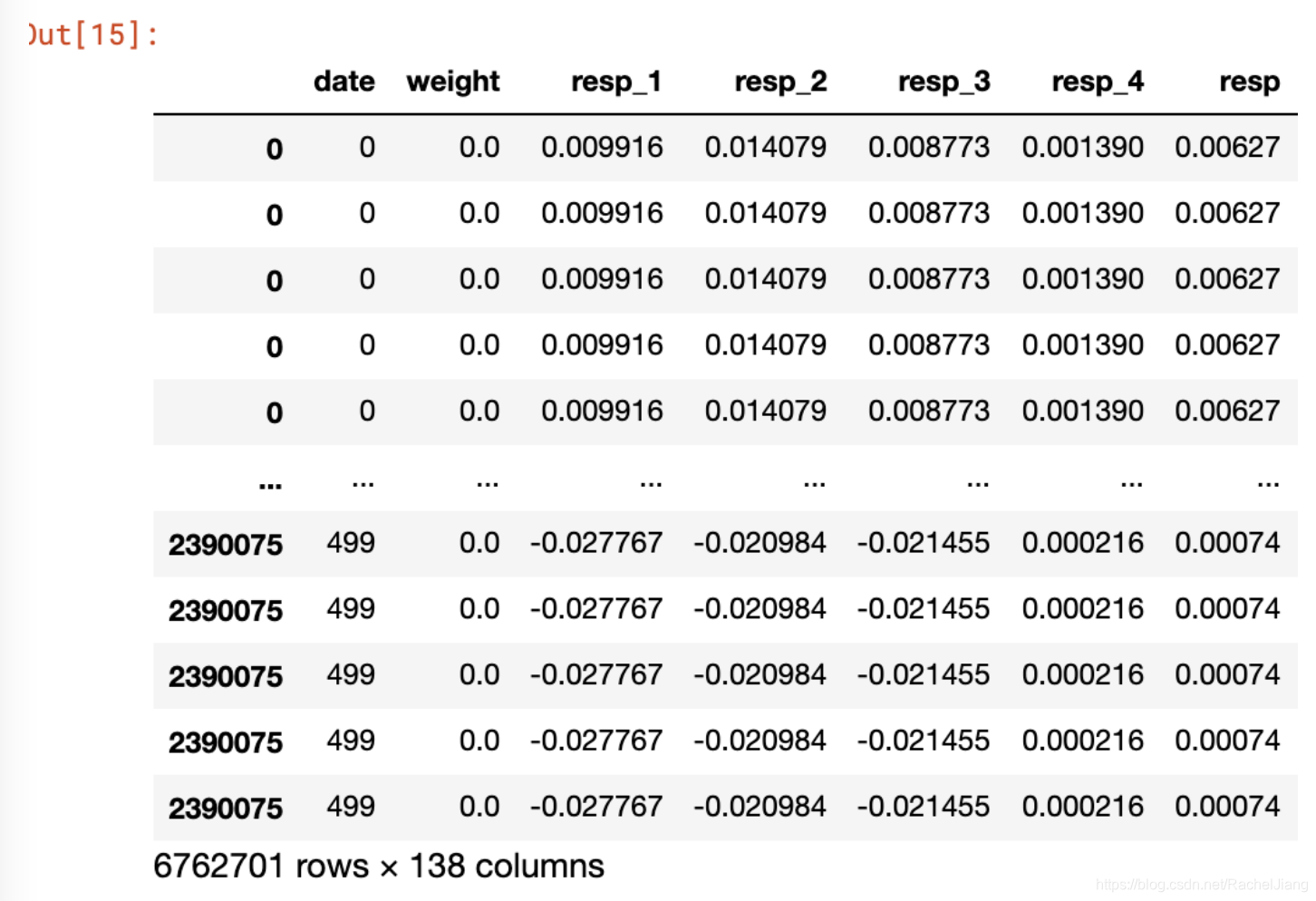
3.df[df.isnull().values==True]
可以只显示存在缺失值的行列,清楚的确定缺失值的位置。
train[train.isnull().values==True]
导出到excel里看 dataframe.to_excel()
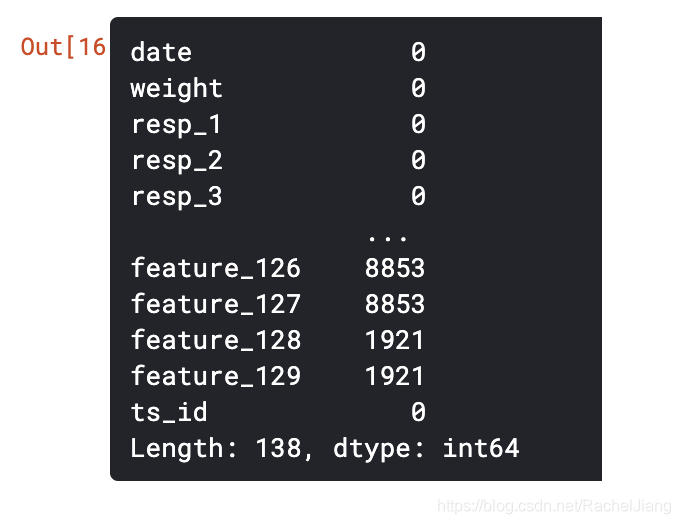
4.isnull().sum()
将列中为空的个数统计出来
train.isnull().sum()
5.计算变量缺失率
df=pd.read_csv('titanic_train.csv')
def missing_cal(df):
"""
df :数据集
return:每个变量的缺失率
"""
missing_series = df.isnull().sum()/df.shape[0]
missing_df = pd.DataFrame(missing_series).reset_index()
missing_df = missing_df.rename(columns={'index':'col',
0:'missing_pct'})
missing_df = missing_df.sort_values('missing_pct',ascending=False).reset_index(drop=True)
return missing_df
missing_cal(df)如果需要计算样本的缺失率分布,只要加上参数axis=1.
缺失观测的行数data3.isnull().any(axis = 1).sum()
缺失观测的比例data3.isnull().any(axis = 1).sum()/data3.shape[0]
Reference
1.xiaoxiaosuwy https://blog.youkuaiyun.com/xiaoxiaosuwy/article/details/81187694
2.Python与数据挖掘 https://zhuanlan.zhihu.com/p/187315467
3.刘顺祥 https://zhuanlan.zhihu.com/p/93179647

















 1178
1178




 到【灌水乐园】发言
到【灌水乐园】发言







