







 本文深入探讨了LeetCode第60题——求解第K个排列的有效算法,对比了全排列方法与优化后的解决方案,分析了时间复杂度。同时,介绍了基于物品的协同过滤推荐算法,讨论了其在电商领域的应用及改进。
本文深入探讨了LeetCode第60题——求解第K个排列的有效算法,对比了全排列方法与优化后的解决方案,分析了时间复杂度。同时,介绍了基于物品的协同过滤推荐算法,讨论了其在电商领域的应用及改进。
Algorithm:60. 第k个排列
Review: Item-Based Collaborative Filtering RecommendationAlgorithms
Tip/Tech:快速排序的非递归实现
Share:
Algorithm
https://leetcode-cn.com/problems/permutation-sequence/
60. 第k个排列

这题,真的,原来还想着简单了,我结合46. 全排列 我还把所有的结果放到一个list里面,然后来了个排序,自以为如此的高效就得出了结果,美滋滋居然。。。但是心里却有种不好的预感,为啥?因为时间复杂度真的太高了。全排列走的时间复杂度就是
O
(
n
!
)
O(n!)
O(n!), 这种级别的时间复杂度,如果题目的意思是要你找出什么规律之类的,那这个时间复杂度估计是要超时,怀着忐忑的心情提交了,果不其然啊,超时,但是没关系,我们先来看看 超时的代码,起码我们可以复习一下子,全排列的代码。。。
class Solution {
private ArrayList<Integer> list = new ArrayList<>();
public String getPermutation(int n, int k) {
StringBuilder initString = new StringBuilder();
for (int i = 1; i <= n; i++) {
initString.append(i);
}
char[] arr = initString.toString().toCharArray();
dfs(0, arr, arr.length);
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
return list.get(k - 1) + "";
}
public void dfs(int index, char[] arr, int len) {
if (index == len) {
list.add(Integer.parseInt(new String(arr)));
}
for (int i = index; i < len; ++i) {
swap(arr, i, index);
dfs(index+1, arr, len);
swap(arr, i, index);
}
}
private void swap(char[] chars, int left, int right) {
char temp = chars[left];
chars[left] = chars[right];
chars[right] = temp;
}
}
以上超时的代码,那么这题真正是思路是啥?
我们先来看一张图片
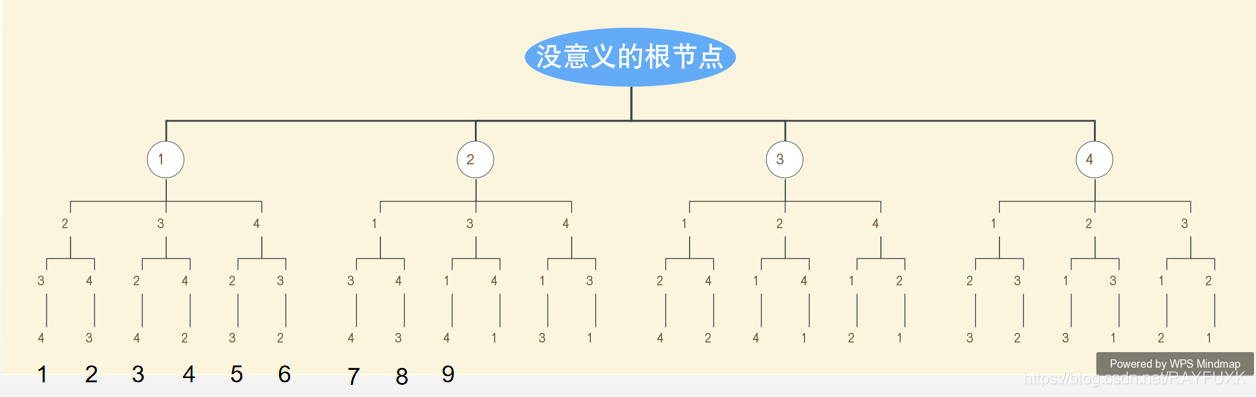
这站图片就是每个位置上的数字的全排列了,我们以题目汇中的例子,输入(4, 9)来举例,首先,其实这里从左到右的每个由顶到底的节点组成的数字都是已经按照从小到大的顺序拍好了的。所以,我们可以知道,前六个数字是以1开头的,第7个到第12个是由2开头的,其实看到这里,我相信你肯定有点思路了,当我们知道第9个数字的首位数是2,那么我们就要去寻找他的第二数字是什么,那么第二个数字的候选就是1, 3, 4这几个,那么,第一位是2、第二位是1的排列数字有几个?2个呗,所以,前两个肯定没法累加到9,第九个数字是在第一位是2,第二位是3的数字里的。
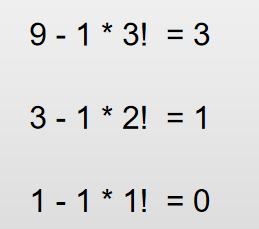
上面这个就是计算在第几个满足第9位数的一个推算过程。其实到了这里,基本就明白大概的思路了
首先,我们寻找的是每个位置上的数字,那么就要满足,K是在合理的排列区间内的。
其次,我们要保证,每个位置上用掉的数字不会重复出现。
Show the code
class Solution {
public String getPermutation(int n, int k) {
StringBuilder ans = new StringBuilder();
// 我们用list来保存每个数字,这样可以
ArrayList<Integer> list = new ArrayList<>();
for (int i = 1; i <= n; ++i) {
list.add(i);
}
for (int i = 0; i < n; ++i) {
int size = list.size();
// 根据还剩下的数字的数量来知道还剩下多少种排列组合。
int factorialNum = getNumMinOneFactorial(size);
for (int j = 0; j < size; ++j) {
// 说明符合当前的那个数找到了。
if (j * factorialNum < k && k <= (j+1) * factorialNum) {
ans.append(list.get(j) + "");
k -= j * factorialNum;
// 保证用过的数字不在出现
list.remove(j);
break;
}
}
}
return ans.toString();
}
// 获取 (n-1)!的值
public int getNumMinOneFactorial(int n) {
int res = 1;
for (int i = 1; i <= n - 1; ++i) {
res *= i;
}
return res;
}
}
以上就是可以通过的答案了:时间复杂度
O
(
n
2
)
O(n^2)
O(n2)
Review
Item-Based Collaborative Filtering RecommendationAlgorithms
http://wwwconference.org/proceedings/www10/papers/pdf/p519.pdf
这篇论文主要介绍了基于物品的协同过滤算法,里面说到,因为像亚马逊那种的公司,原来基于用户的协同过滤的算法因为太稀疏,很多用户只买了不到1%的物品,还有需要维护大量的数据,可靠性不行,所以就换成了现在的基于物品的协同过滤算法,也是一种紧邻算法。
里面参考了三种相似度计算的公式:
Cosine-based Similarity 余弦相似度
Correlation-based Similarity
Adjusted Cosine Similarity
预测分析:
Weighted Sum 有加权综合
Regression 逻辑回归
Tip/Tech
快速排序的非递归实现
其实一点都不好理解,就是让你明白一个道理:递归就栈。
public static void quickSort(int[] arr, int startIndex, int endIndex) {
Stack<Map<String, Integer>> quickSortStack = new Stack<Map<String, Integer>>();
Map<String, Integer> rootParam = new HashMap<>();
rootParam.put("startIndex", startIndex);
rootParam.put("endIndex", endIndex);
quickSortStack.push(rootParam);
while (!quickSortStack.isEmpty()) {
// 弹出在栈顶的map,
Map<String, Integer> tempParam = quickSortStack.pop();
//
int pivotIndex = partition(arr, tempParam.get("startIndex"), tempParam.get("endIndex"));
// 如果区分点已经是中点了,那么就不入栈了,如果不是
if (tempParam.get("startIndex") < pivotIndex - 1) {
Map<String, Integer> leftPart = new HashMap<>();
leftPart.put("startIndex", tempParam.get("startIndex"));
leftPart.put("endIndex", pivotIndex - 1);
quickSortStack.push(leftPart);
}
// 如果区分点已经是中点了,那么就不入栈了,
if (pivotIndex + 1 < tempParam.get("endIndex")) {
Map<String, Integer> rightPart = new HashMap<>();
rightPart.put("startIndex" , pivotIndex + 1);
rightPart.put("endIndex", tempParam.get("endIndex"));
quickSortStack.push(rightPart);
}
}
}
private static int partition(int[] arr, int startIndex, int endIndex) {
int pivot = arr[startIndex];
int mark = startIndex;
for (int i = startIndex+1; i <= endIndex; ++i) {
if (arr[i] < pivot) {
mark ++;
// swap
int temp = arr[mark];
arr[mark] = arr[i];
arr[i] = temp;
}
}
arr[startIndex] = arr[mark];
arr[mark] = pivot;
return mark;
}
Share
How much bandwidth does the spinal cord have?
脊髓有多少带宽?
https://www.reddit.com/r/askscience/comments/7l56sb/how_much_bandwidth_does_the_spinal_cord_have/
这让我思考,考虑到信号速度的一些粗略参数以及神经在一秒钟内可以发射多少次,可以计算出脊髓的带宽并表示为Mb / s?
下面有人得出了回答,当然只是一个费米估算,这玩意个每个人都不同:
所以我们有大约200,000,000个神经元每0.0015秒以最大1次射击速率射击。那是每秒约133,000,000,000个信号。
让我们假设我们可以将神经元射击模拟为“开启”或“关闭”(就像1或者0),就像二进制一样。这意味着这种模型脊髓每秒可传输1330亿比特,千兆比特= 10亿比特,这使我们的脊髓最大数据吞吐量达到每秒133千兆位。
将它除以8以得到GB,并且每秒16.625 GB的数据能够沿着脊髓传输。或者每两秒钟拍一部4K电影。

















 1912
1912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









