







 本文深入探讨了Prometheus(特别是使用GO SDK)和Grafana的基本应用。通过Prometheus SDK,可以轻松监控服务指标,如CPU使用率、内存等。Prometheus支持灵活的pull方式和多种服务发现机制,而Grafana则提供了直观的图表展示。文章介绍了Prometheus的Counter、Gauge、Histogram和Summary等指标类型,以及如何使用PromQL进行查询。同时,分享了最佳实践和Grafana面板的配置技巧,包括监控告警的设置。
本文深入探讨了Prometheus(特别是使用GO SDK)和Grafana的基本应用。通过Prometheus SDK,可以轻松监控服务指标,如CPU使用率、内存等。Prometheus支持灵活的pull方式和多种服务发现机制,而Grafana则提供了直观的图表展示。文章介绍了Prometheus的Counter、Gauge、Histogram和Summary等指标类型,以及如何使用PromQL进行查询。同时,分享了最佳实践和Grafana面板的配置技巧,包括监控告警的设置。
最近我对Prometheus刮目相看了, 服务加一行代码就能轻轻松松地监控起来服务的CPU使用率、内存、协程数、线程数、打开的文件描述符数量及软限制、重启次数等重要的基本指标, 配合Grafana建立了直观的图表, 对查问题很有帮助, 故想写写折腾Prometheus和Grafana后得到的值得一讲的实践与理解.
 GO服务几个重要的基本指标Dashboard
GO服务几个重要的基本指标Dashboard
介绍
Prometheus是CNCF 的项目之一(ps.CNCF的项目代码都值得研究), 而且还是Graduated Projects. 同时因为其主要是方便灵活的pull方式, 暴露出个http接口出来给prometheusd拉取就行了, 而push方式客户端要做更多的事情, 如果要改push的地址的话就很麻烦, 所以很多著名的项目都在用它, 比如k8s, tidb, etcd, 甚至是时序数据库influxdb都在用它.
我体会到, 很多场景很适合使用Prometheus sdk去加一些指标, 比如logger包, Error级别的消息数是一个很有用的指标; 对于消息队列的SDK, 可以用Prometheus收集客户端侧的发送时延、消费时延、消费处理耗时、消费处理出错等指标; 封装DB操作的SDK, 连接池打开的DB连接数与最大连接数是个很重要的指标; 写个HTTP Middleware, http handler的调用次数、处理时间和responseCode是感兴趣的指标.
安装
Prometheus是Go写的, 故部署方便且跨平台, 一个二进制文件加配置文件就能跑起来.
GitHub release页面有各个平台的编译好的二进制文件,通常配合supervisor等进程管理工具来服务化, 也可以用docker.
文档上有基础的配置文件示例, 复制为prometheus.yml即可.

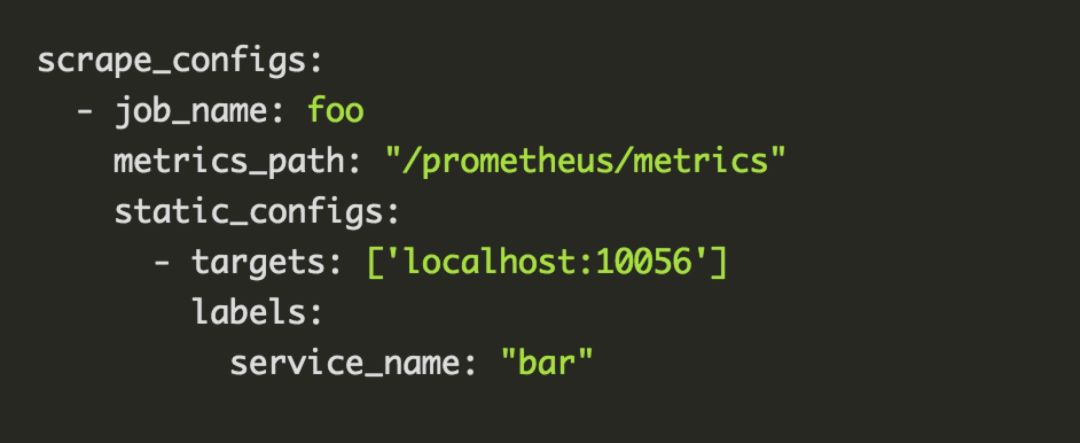
prometheus.yml主要是定义一些全局的抓取间隔等参数以及抓取的job, 抓取的job可以指定名字、抓取间隔、抓取目标的IP端口号列表, 目标的路由路径, 额外的label等参数.
抓取指标时会自动加上job="<job_name>"和instance="<target ip port>"两个label, 如果想给job添加额外的固定label, 则可以在配置文件中按如下语法添加.
服务发现
前面说到, Prometheus的配置文件主要就是定义要抓取的job配置, 显然新加服务要改配置文件是比较麻烦的, Prometheus的一大重要的功能点就是原生支持多种服务发现方式, 支持consul etcd等服务发现组件, 还支持非常通用的基于文件的服务发现, 即你可以定义一个写好target的IP端口号等配置的配置文件路径, 由外部程序定期去更新这个文件, prometheus会定期加载它, 更新抓取的目标, 非常灵活.
数据描述
Prometheus的时序指标数据由timestamp、metric name、label、value组成:
timestamp是毫秒级的时间戳.
metric name是符合正则<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5629
5629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









