




青稞社区:https://qingkeai.online/
原文:https://mp.weixin.qq.com/s/65OdHT9P6HGu16F1l_zj-Q
训练与人类意图对齐的多模态大模型是一个长期挑战。传统的基于分数的奖励模型在强化学习(RLHF)中存在准确性低、泛化性弱和可解释性差等问题。
11月15日(周六)上午10点,青稞社区和减论平台将联合组织青稞Talk 第89期,并邀请到北京大学博士生周嘉懿,直播分享《Generative RLHF-V:面向多模态 RLHF 的人类意图对齐框架》。
论文:Generative RLHF-V: Learning Principles from Multi-modal Human Preference
链接:https://arxiv.org/pdf/2505.18531
代码:https://generative-rlhf-v.github.io/
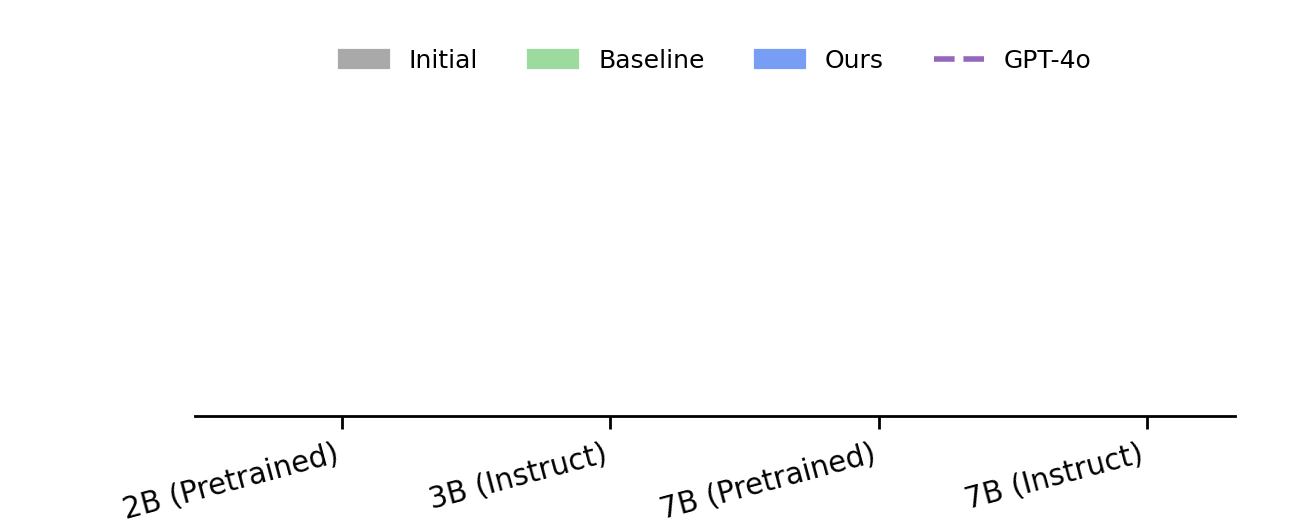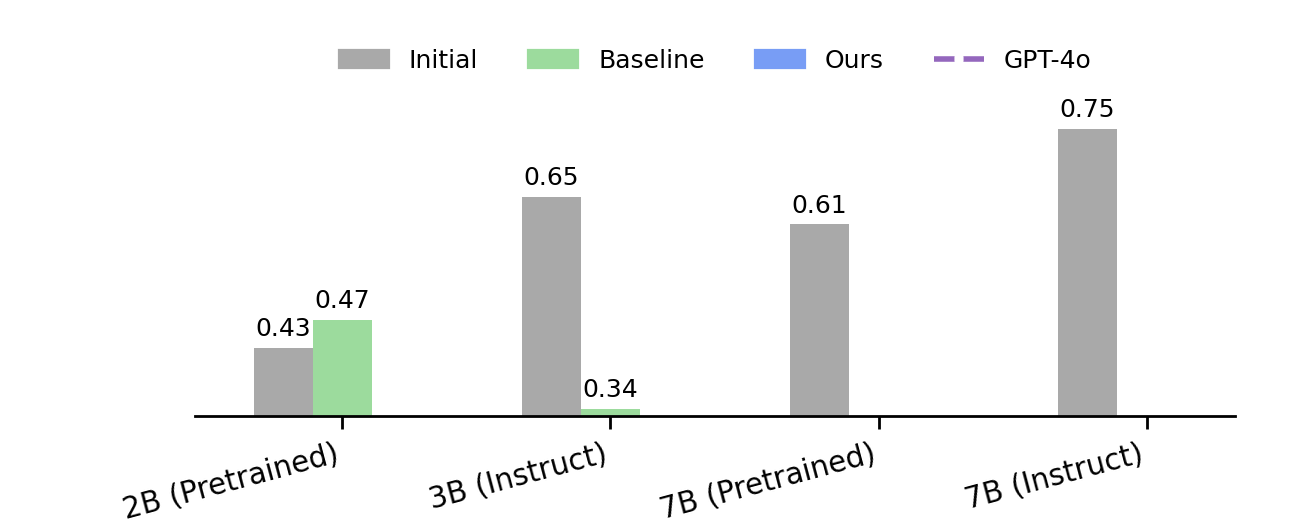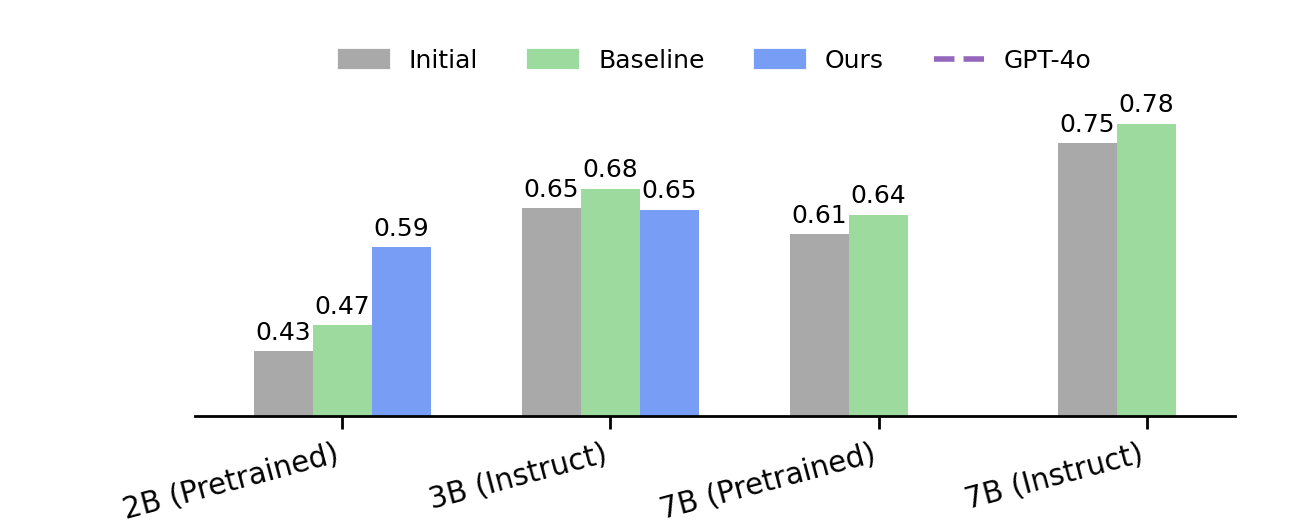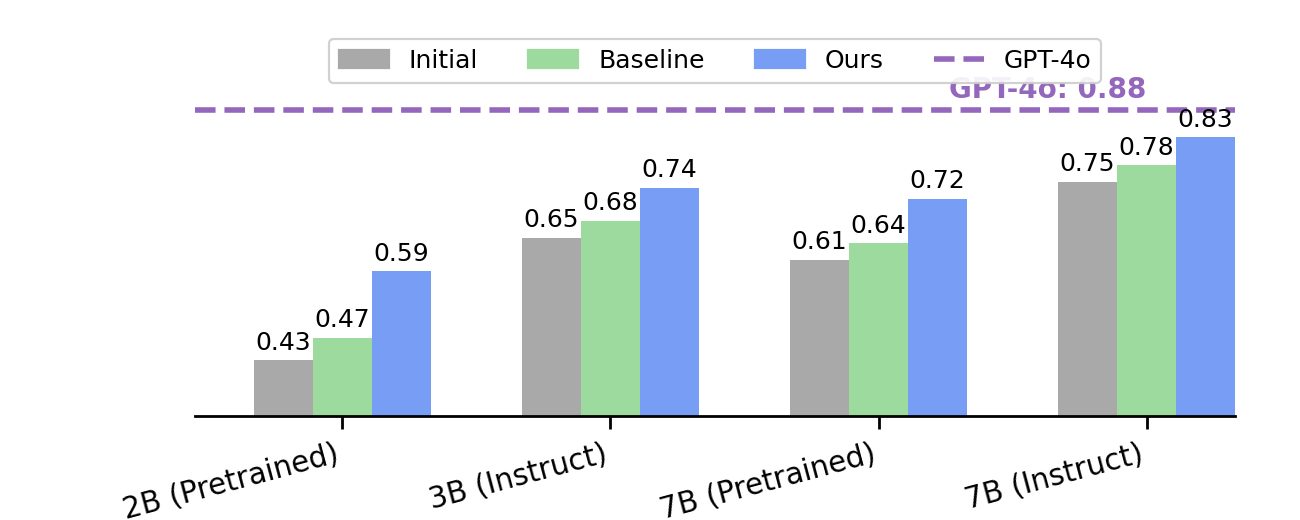
本期Talk将介绍Generative RLHF-V,一个用于多模态RLHF的对齐框架。该框架包含一个两阶段流程:

1、基于RL的生成式奖励建模,引导生成式奖励模型(GRM)主动捕捉人类意图,从偏好中学习“原则”;
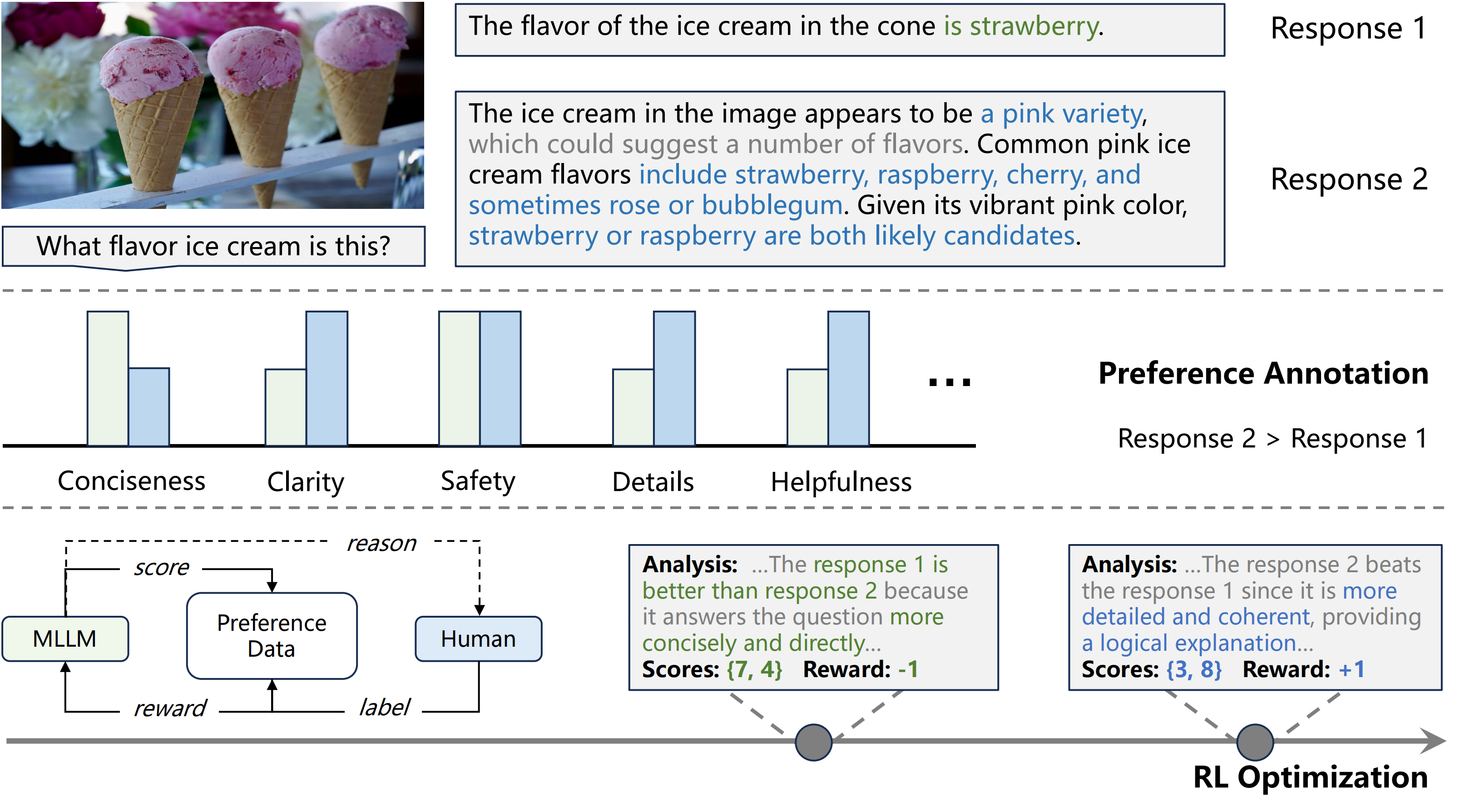
2、基于“分组比较” 的RL优化,通过比较一组响应来增强评分的精确性。
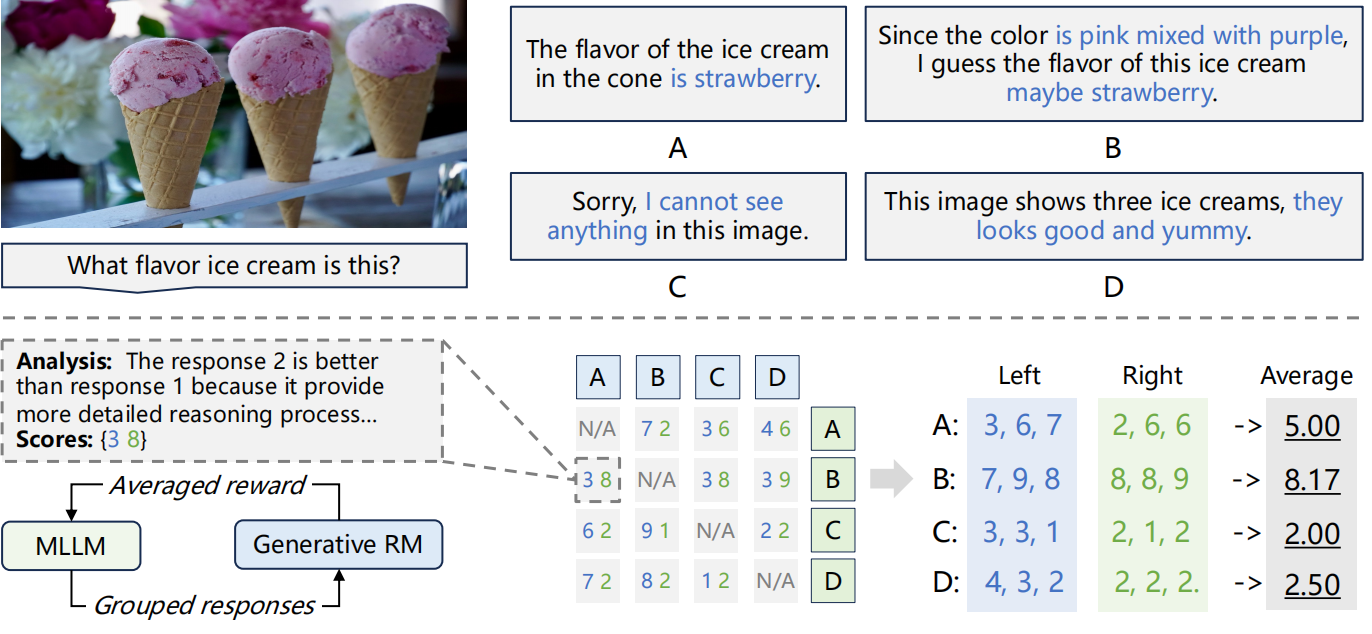
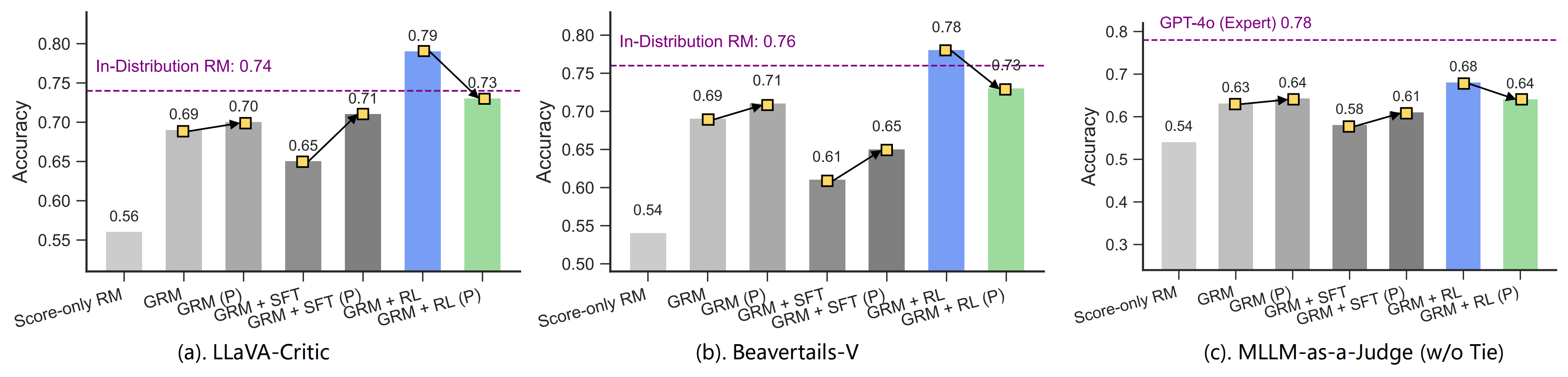
实验证明,Generative RLHF-V在7个基准测试中平均提升了18.1%的性能。本次演讲还将讨论在过训练中发现的一种 “自夸” 的奖励黑客行为。
分享嘉宾
周嘉懿,北京大学人工智能研究院2024级博士生,导师为杨耀东助理教授,主要研究方向为强化学习、大模型对齐,致力于大模型在交叉领域的应用落地,累积在人工智能顶级会议与期刊发表论文10余篇,代表性论文获ACL 2025最佳论文奖(唯一大陆机构独立完成),AAAI口头汇报等,谷歌学术引用800余次;在开源方面,作为项目负责人开源大模型全模态训练框架align-anything与分布式安全强化学习框架OmniSafe,累积获得6000+star。相关成果与模型被部署于香港政府、北医三院、武汉同济等,并被OpenAI和图灵奖得主Yoshua Bengio引用。
主题提纲
Generative RLHF-V:面向多模态 RLHF 的人类意图对齐框架
1、多模态大模型+RL 偏好对齐方法概述与挑战
2、多模态 RLHF 的对齐框架
- 基于 RL 的生成式奖励模型(GRM)
- 基于“分组比较” 的 RL 优化
3、“自夸” 的奖励黑客行为及未来研究的探讨
4、AMA (Ask Me Anything)环节
直播时间
11月15日(周六)10:00 - 11:00
如何观看
Talk 将在青稞社区【视频号:青稞AI、Bilibili:青稞AI】上进行直播,欢迎预约!

















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









