




当下的大语言模型已经能够在解题、编程与工具使用上表现优异,但读懂人心远比解题更加复杂:用户的目标往往模糊,在交互中逐步显露,且常以间接方式表达。
真正的智能体不仅要完成任务,更需要主动澄清、持续适配,并在多重约束中做出明智权衡。
10月18日(周六)上午10点,青稞Talk 第79期,伊利诺伊大学香槟分校 (UIUC) 博士生钱成,将直播分享《“知人者智”:以用户为中心的智能体交互与训练》。
本期 Talk 将介绍一套围绕“用户意图对齐”构建的系统化方案:
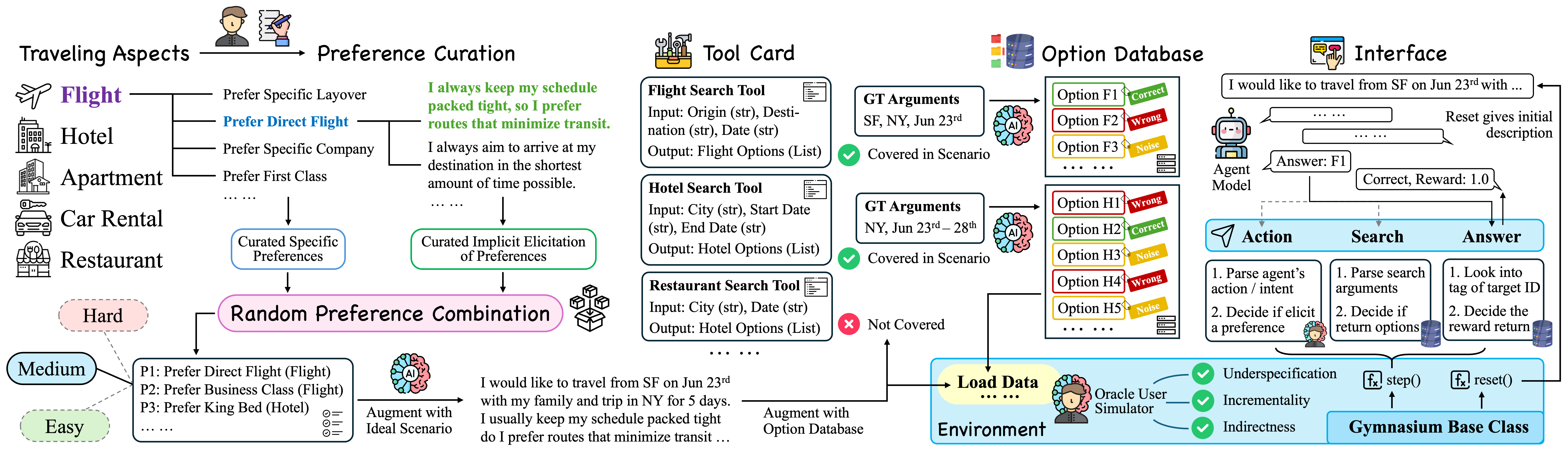
一方面,通过交互式环境刻画模糊性、渐进性与间接性,将“是否懂人”转化为可量化的评测指标;
论文:UserBench: An Interactive Gym Environment for User-Centric Agents
链接: https://arxiv.org/pdf/2507.22034
代码:https://github.com/SalesforceAIResearch/UserBench
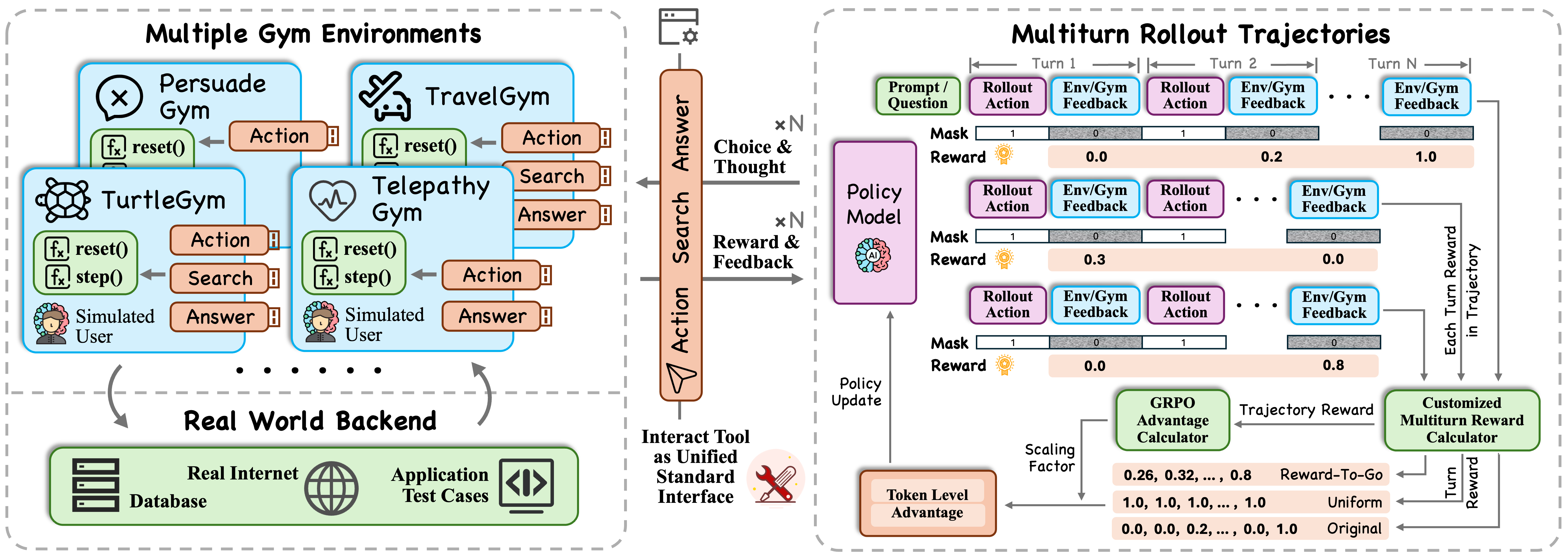
另一方面,在统一的强化学习框架下,以可拓展环境支持多轮交互训练,使模型能够在过程中不断积累进展并逐步对齐用户偏好。评测与训练相辅相成,推动智能体从“会解题”真正迈向“懂用户”。
论文:UserRL: Training Proactive User-Centric Agent via Reinforcement Learning
链接: https://arxiv.org/pdf/2509.19736
代码:https://github.com/SalesforceAIResearch/UserRL
分享嘉宾
钱成,伊利诺伊大学香槟分校 (UIUC) 二年级博士生,导师为季姮教授。本科就读于清华大学计算机系,导师为刘知远教授。目前工作集中在大语言模型工具使用与推理,以及人工智能体方向。
曾在 ACL,EMNLP,COLM,COLING,NAACL,ICLR 等多个学术会议发表论文十余篇,一作及共一论文十余篇,谷歌学术引用超 1000,现担任 ACL, EMNLP Area Chair,以及 AAAI,EMNLP,Neurips,COLM 等多个会议 Reviewer。
谷歌学术主页: https://scholar.google.com/citations?user=p2bY7oAAAAAJ。
主题提纲
“知人者智”:以用户为中心的智能体交互与训练
1、大语言模型实现交互智能的核心难点
2、围绕“用户意图对齐”构建的系统化方案
- UserBench:可量化的评测指标
- UserRL:统一的多轮交互强化学习框架
3、未来的研究方向探讨
直播时间
10月18日10:00 - 11:00
参与方式
Talk 将在青稞社区【视频号:青稞AI、Bilibili:青稞AI】上进行,欢迎预约!
同时,嘉宾已经入驻青稞社区·知识星球,想要提问交流的朋友可以加入星球!


















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









