







青稞社区主页:https://qingkeai.online/
gzh原文:本周六上午!和项目作者朱子霖:一起聊聊 RL 训练框架slime
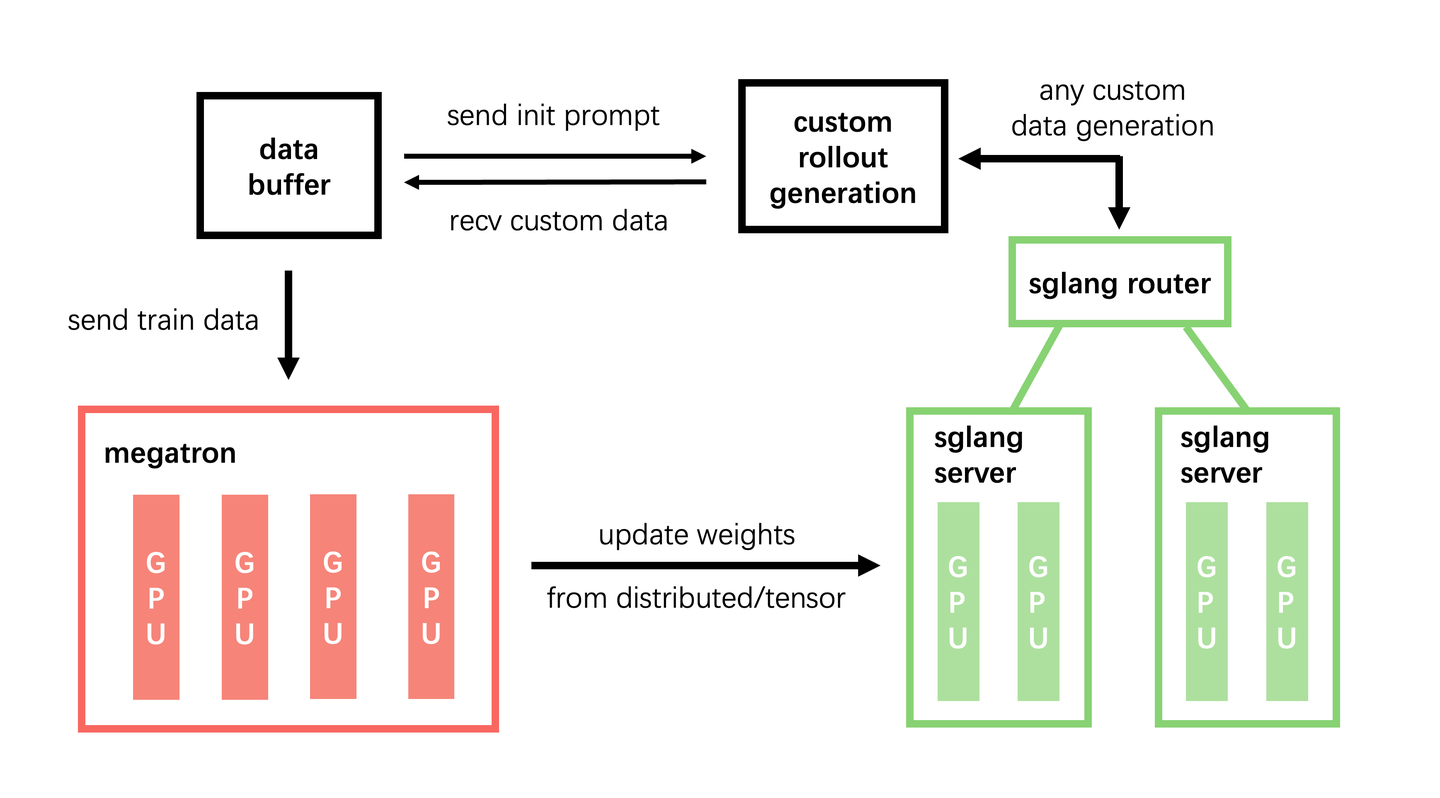
slime是一个在灵活性、效率和可扩展性方面都表现卓越的 RL 框架,旨在解决强化学习中的常见瓶颈,并针对复杂的智能体任务做了优化。
- 灵活的混合训练架构: slime 的核心优势在于其多功能的混合架构。它既支持同步、集中式训练(适合推理和通用强化学习训练),也支持分布式、异步训练模式。这种异步模式对于 Agentic RL 至关重要,因为在这类场景中,数据生成往往是一个缓慢的外部过程。通过将训练与数据收集解耦,我们可以确保训练 GPU 始终保持满负荷运行,最大化硬件利用率。
- 面向智能体的解耦设计:Agentic RL 经常面临环境交互时延迟高且分布长尾的问题,这严重限制了训练吞吐量。为此,slime 实现了完全解耦的基础架构,将环境交互引擎与训练引擎分离。这两个组件在不同的硬件上独立运行,将数据生成的瓶颈转化为可并行化的非阻塞过程。这种设计是加速长序列智能体任务的关键。
- 混合精度加速数据生成: 为了进一步提升吞吐量,slime 采用混合精度推理来加速环境交互。它使用 FP8 格式进行数据生成(Rollout),同时在模型训练中保留 BF16 以确保训练稳定性。这种技术在不影响训练质量的前提下,大幅提升了数据生成速度。
这种整体化的设计使得 slime 能够无缝集成多个智能体框架,支持各种任务类型,并通过统一而强大的接口高效管理长序列环境交互。
8月2日(周六)上午10点,青稞Talk 第68期,智谱 AI RL Infra 工程师、slime 开源项目作者朱子霖,将直播分享《slime:专为 RL Scaling 设计的大规模 RL 训练框架及实践》。
https://github.com/THUDM/slime
关于slime的分析可以看以下两篇文章:
分享嘉宾
朱子霖,智谱 AI RL Infra 工程师,slime、ring_flash_attention 等开源项目作者,SGLang、OpenRLHF collaborator,长期参与训练框架优化,目前专注于大规模 RL 训练中的系统优化需求。
主题提纲
slime:专为 RL Scaling 设计的大规模 RL 训练框架及实践
- 当我们在设计训练框架时,我们在设计什么?
- RL 框架的相同与不同
- slime 框架设计的主要思路与结构
- 下一步 RL 框架的一些潜在优化点
直播时间
8月2日10:00 - 11:00


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









