




👉目录
1 模型效果全面提升
2 更多额外的提升
3 网友测试
4 写在最后
GPT Image 1.5正式发布了,它是 OpenAI 最新一代图像生成与编辑模型,对比之前的 GPT-Image-1,实现了全面升级。它不仅用于生成图像,也强化了编辑、保真与创意控制能力,并开放了 API 接入。
关注腾讯云开发者,一手技术干货提前解锁👇
新的图像生成模型发布之后,所有的ChatGPT用户都可以免费使用,同时也开放了API接口进行调用。
从官方的介绍来看,它的优点很明显:
生成速度显著提升:与之前版本相比,GPT Image 1.5 图像生成和编辑速度高达 4 倍提升。这意味着从提出提示词到最终图像输出,更快、更流畅,特别适合高频交互或产品级场景。
更强的指令理解与遵循:模型对用户指令的执行精度显著增强,能更准确地按照提示调整细节、光线、元素位置等,这对复杂场景生成和编辑表现尤为重要。
图像编辑能力大幅升级:GPT Image 1.5 对已有图片的编辑也更加先进,可以对用户上传的图片进行“添加/移除特定对象”、“调整背景、风格与布局”等,这种编辑控制能力提升,使其不仅是“生成工具”,更像是 智能创意工作室。
细节保留与真实感增强:输出图像在细节表现、光影一致性、人物、纹理和小文本渲染方面都有明显提升,生成的写实照片或艺术风格图像在自然度与真实感上更高。
GPT-Image-1.5一经发布,就登上了各大榜单的第一名。在LMArena竞技场上,GPT-Image-1.5刷新了最新的SOTA效果。其中在文生图领域,以1264 Elo分数荣登榜首,直接超越谷歌的Nano Banana Pro等地榜首。而在图像编辑领域,chatgpt-image-latest以3分优势获得冠军,而GPT Image 1.5位列第四。
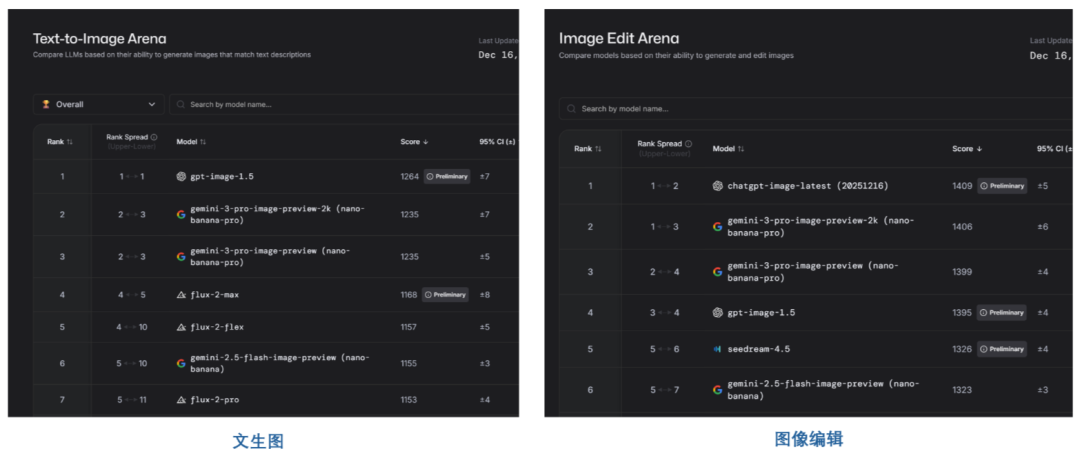
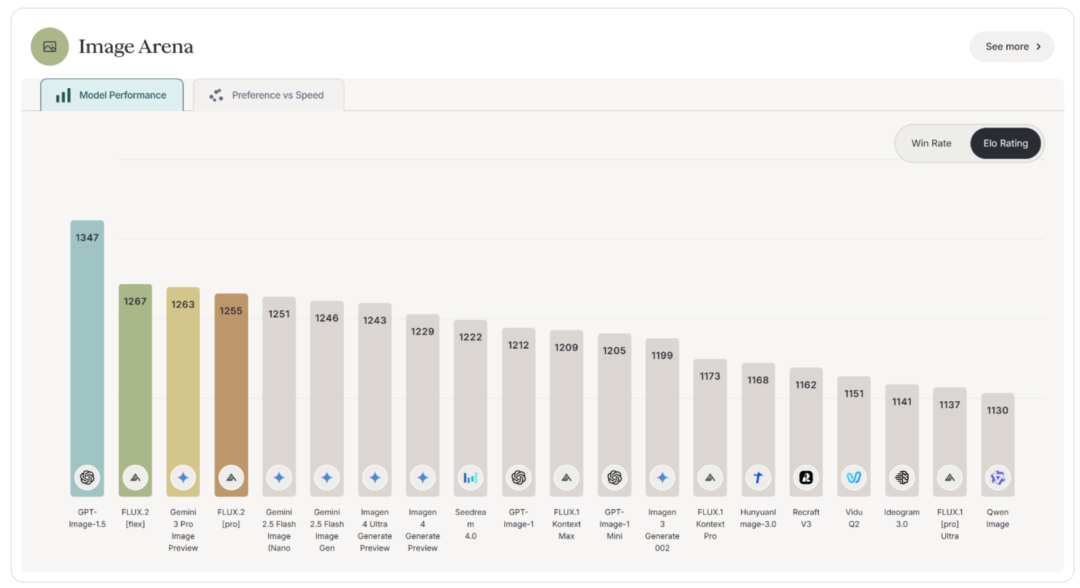
在DesignArena的图像领域榜单上,GPT-Image-1.5拿到了最高的1347分数,直接领先nano banana pro一个身位。
01
模型效果全面提升
这次模型在针对图像的编辑上,效果更为精准,比如可以通过不断变换提示词语,去修改同一张图片的不同效果。

给定上面三个图片和具体的提示词:将这两名男子和那只狗合成到一张 2000 年代胶片相机风格的照片中,画面是他们在儿童生日派对上看起来百无聊赖。

然后基于这个图片,进行精准编辑。比如让它添加更多的背景信息:在背景中加入混乱的小孩,他们一边尖叫一边乱扔东西。

又或者:把左边男子变成动漫脸,小狗改成毛绒公仔。

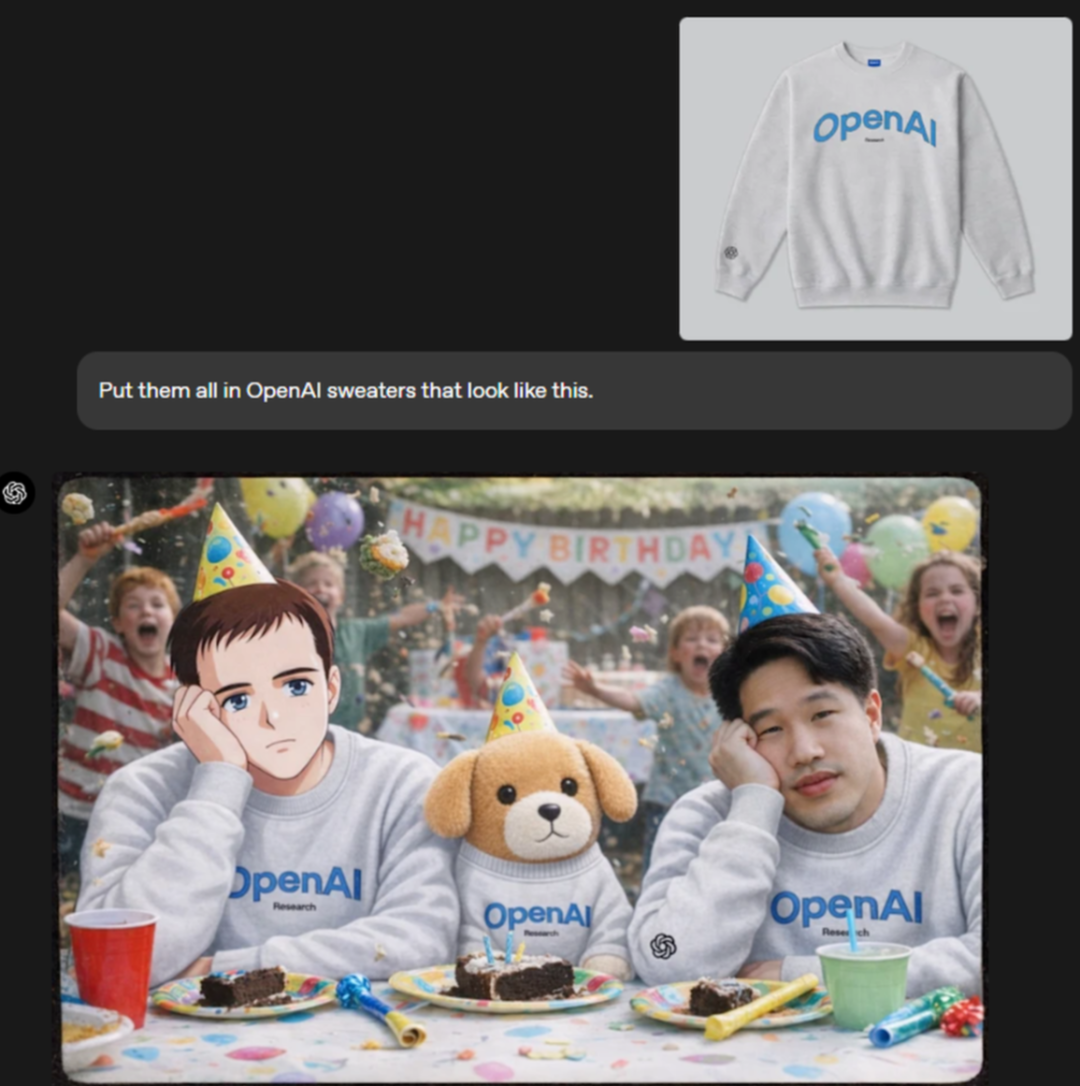
然后还可以继续在之前生成的图片之上,再添加更多的图片元素:左边那男的改成手绘复古日漫风,狗改成毛绒公仔,右边那男的和背景都别动。再让他们全部穿上OpenAI定制衣服。
另外还可以把所有的背景进行更换,只需要一个命令就可以切换:现在把那两名男子移除,只保留那只狗,并把它放到一个类似所附图片风格的 OpenAI 直播画面中。
也可以通过变换不同的细节,融合多种元素进行创作,比如把给定的人物图像,让它创造一个超风格化的3D漂浮头部。

prompt:创造一个超风格化的3D漂浮头部,呈现一个任性、魅力十足的主角,表情不满且不满:半睁的眼睛、拱起的眉毛和微妙的嘴角翘起,展现出经典的“恶毒女孩”态度。她们光滑的皮肤呈现光泽乙烯基表面,颧骨和鼻梁上有强烈的高光,能在柔和的摄影棚灯光下闪耀。涂抹全息虹彩眼影,从紫色变换到青绿色,并带有清晰的镜面光泽。将浓密的头发造型为光滑、光泽、雕塑般的波浪或光滑的盘发,反射光线如抛光的丙烯。加一个小型金属镀铬鼻环(钉或环形),带有细微的拉丝金属反光。头部悬浮在一个纯白色中性背景上,倾斜15度,就像高级产品渲染图一样。使用明亮、柔和的摄影棚灯光,避免刺眼阴影,强调光泽、塑性和次表面散射,营造真实的深度。氛围是任性、时尚、冷静疏离。摄像角度为近景肖像,正视,使用85毫米镜头。质地是超光滑、高光泽、卡通风格的塑料皮肤、嘴唇和头发。

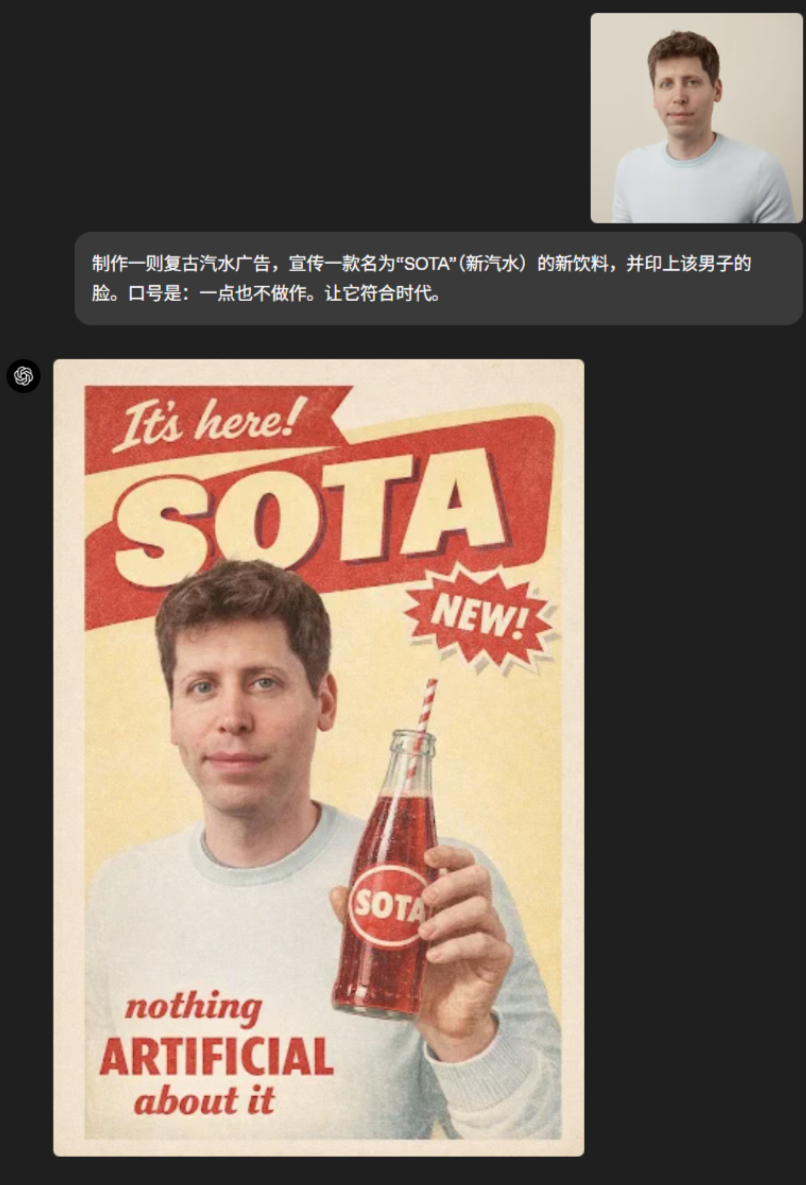
饮品广告的制作:
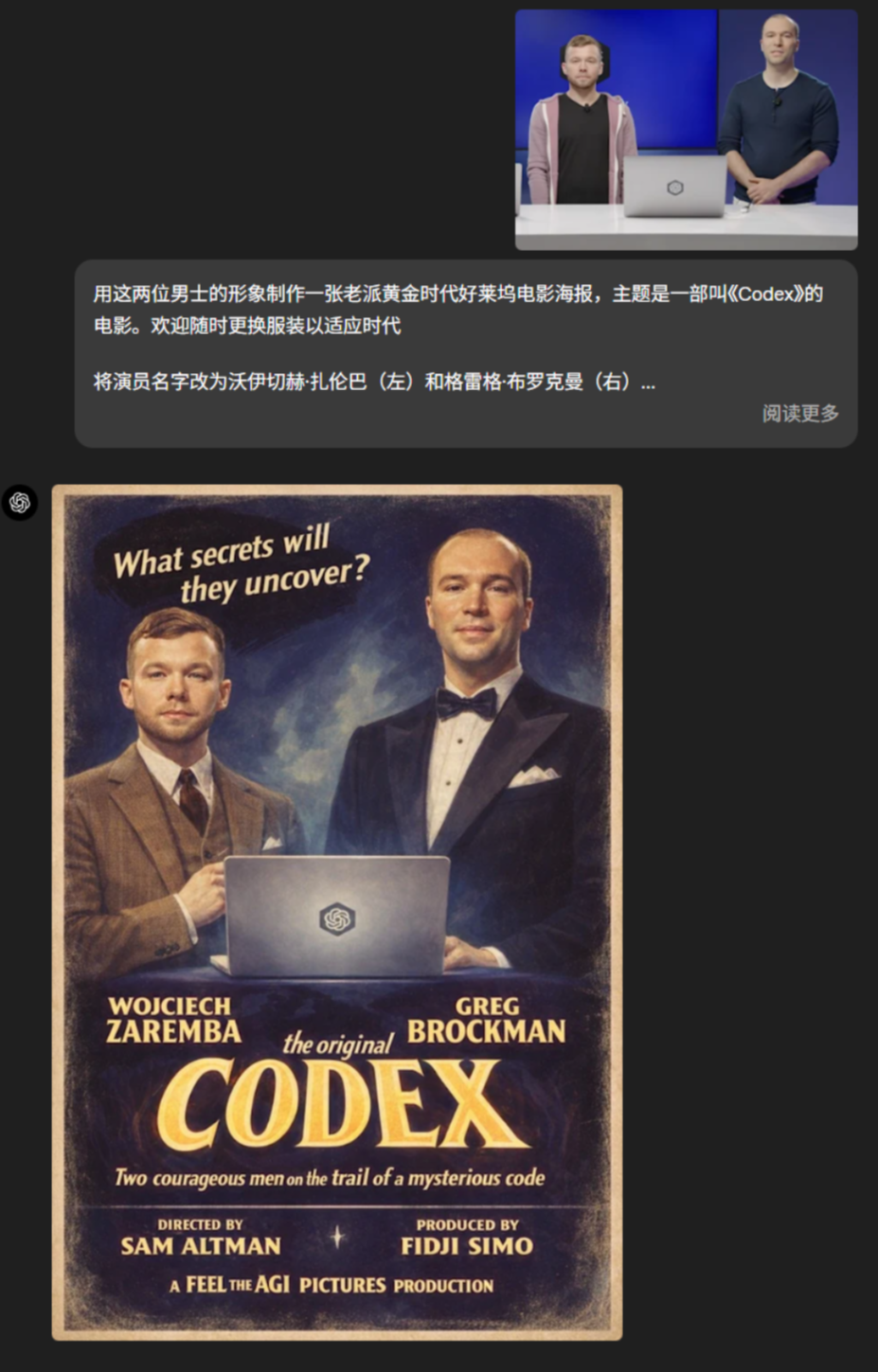
电影海报快速构建:
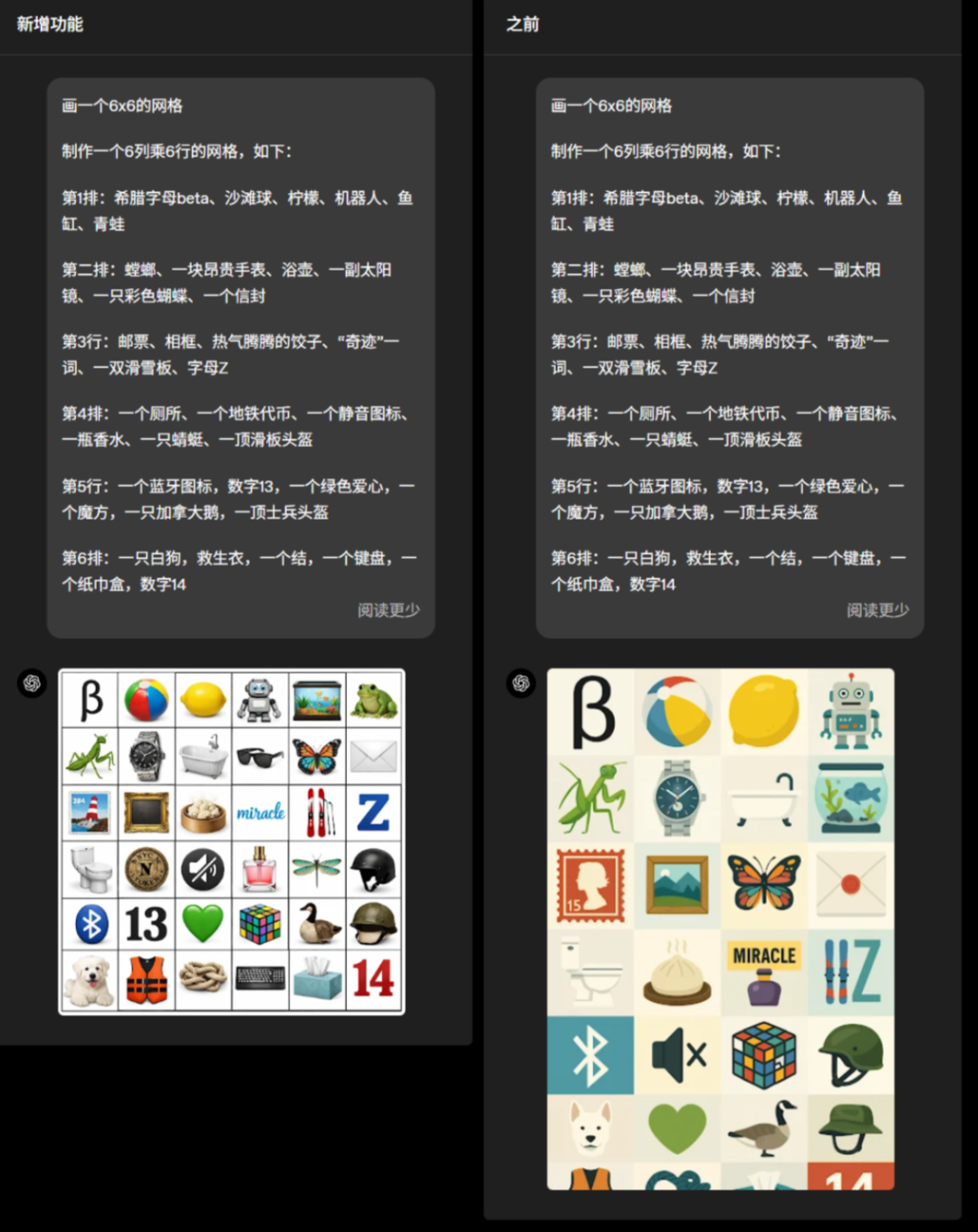
这一次,新模型在指令跟随上相比上一个版本效果会更强。比如同样让模型画出一个6*6的网格,而且网格中需要填入用户给定的信息。在最新模型的效果上生成很好,较好的遵循了指令。
此外,模型在文本渲染方面更进一步,能够处理更密集和更小的文本。比如,让它在一张图上介绍一下GPT-5.2的内容。

介绍一下卡路里的信息:

让它生成一张解析“斐波那契数列是如何工作的”:
02
更多额外的提升
在多个维度上,新模型均实现了显著优化,有效提升了输出结果的直接可用性。例如,在人脸生成方面,新模型能够产出更高质量且外观更自然的图像。
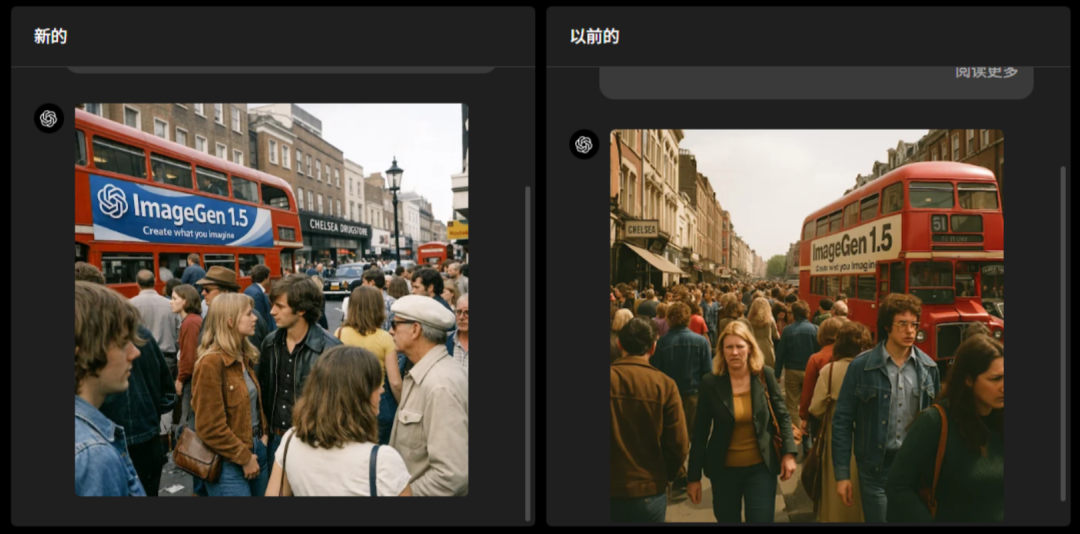
以ChatGPT Image生成1970年代伦敦场景为例,新版(左侧)与旧版(右侧)的对比图像差异尤为明显。在人脸细节处理上,1.5版本展现出更强的能力,所生成的图像更具逼真度。
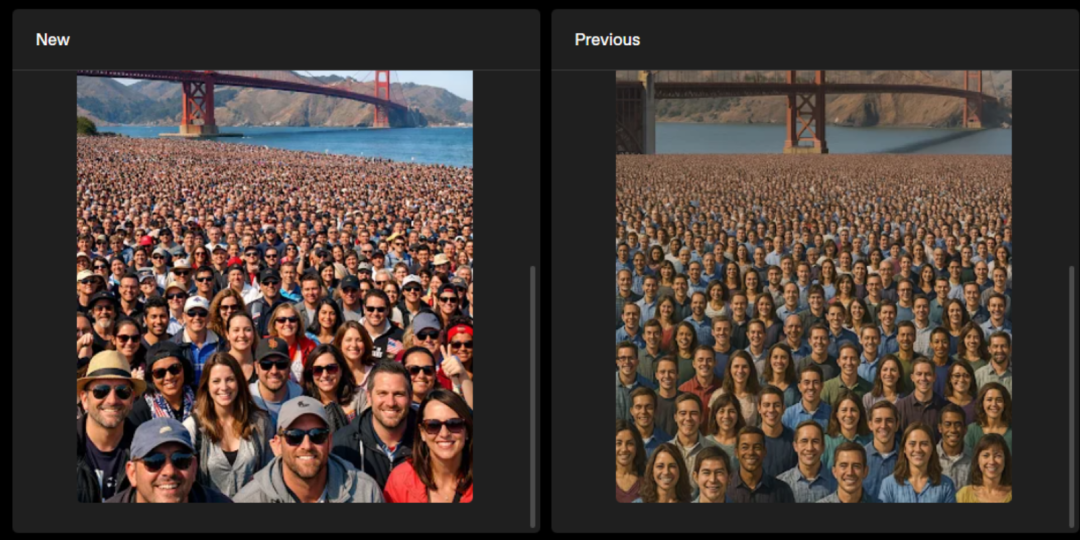
在测试新模型生成“人山人海”的场面的时候,效果提升很大,而且更加逼真和自然。
prompt:金门大桥前成千上万的人群。人群中每个人的面孔都必须清晰可见。
新模型对于在海底的场景还原更加真实
prompt:一个潜水员在水下弹钢琴,美人鱼们在旁边观看。超写实业余摄影

让它生成一张带眩光的照片,下面对比图,一眼就能看出右边效果更假。
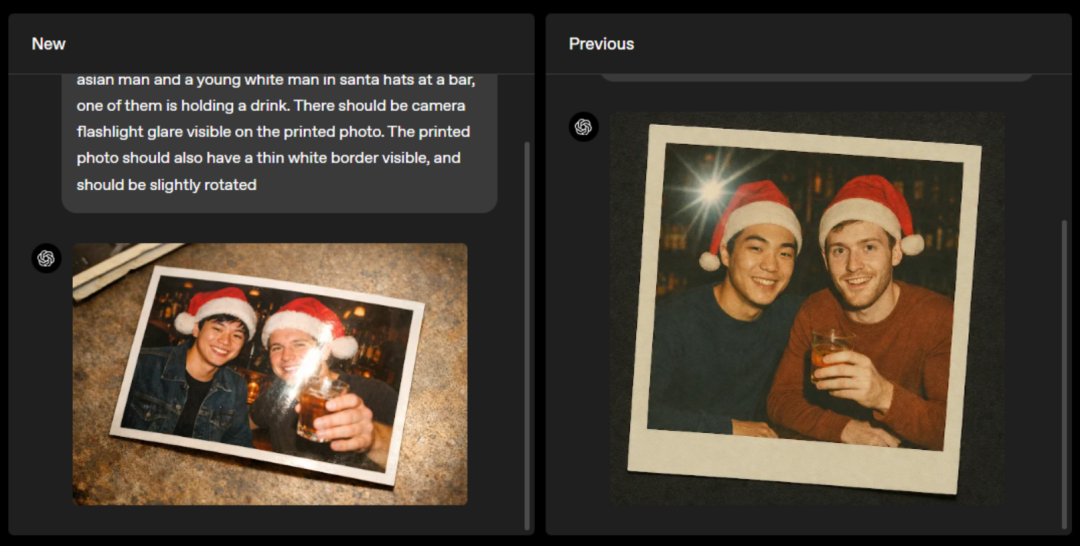
生成一张复古印刷照片,照片中一位年轻亚洲男子和一位戴圣诞老人帽的白人年轻男子在酒吧,其中一人手里拿着饮料。打印出来的照片上应该会有相机手电筒的反光。打印出来的照片还应有一条细细的白色边框,并且应略微旋转
03
网友测试
Q1:人物生成
左图GPT VS 右图Nano Banana Pro。看起来两个模型生成的都非常真实,但是Nano Banana Pro生成的雪更加干净。

Q2:巨型人物生成
提示:一张照片级的广角无人机镜头,拍摄一个庞然大物(与参考中完全相同的面孔/身体)悠闲地坐在伦敦街道对面,一膝抬起,手放在手上。他穿着藏青色大衣、针织毛衣、深色裤子、靴子和极简毛线帽。小车、公交车、自行车和行人在他周围穿梭,经典的伦敦红砖建筑、黑色灯泡和鹅卵石街道,在他的身形下显得渺小。柔和的阴天伦敦白天映衬着湿润的路面。

左图GPT VS 右图Nano Banana Pro。GPT生成的效果会偏暗色调一点
Q3:人物表情对比
网友测试了两个模型对于人类感情的表现。

Q4:广告风格创建
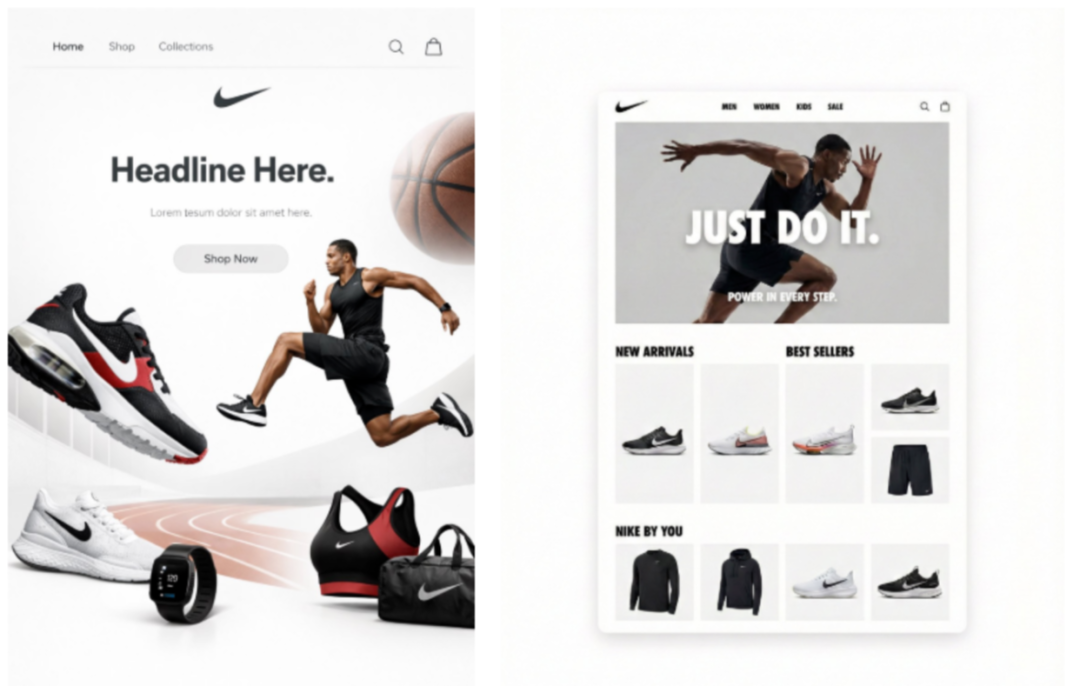
prompt:为耐克打造一个简洁的苹果风格网站,并以4:5宽高比搭配强有力的元素
左图GPT VS 右图Nano Banana Pro。GPT赢在界面美学和对提示理解方面。
Q5:多个物品组合
让图片中的物品进行有效组合

Q6:动漫人物替换

Q7:人物风格转变
04
写在最后
这一次GPT-Image-1.5的发布明显是为了狙击谷歌的Nano Banana,效果怎么样只能说见仁见智。
如果说 GPT-Image-1 还停留在“更好看的图像生成器”,那么 GPT-Image-1.5 已经明显跨过了一条分水岭——从生成工具,走向可控、可复用、可落地的创意生产系统。
从横向对比来看,Nano Banana Pro 依然在某些风格和局部细节上很强,但 GPT-Image-1.5 的优势更偏向“通用性 + 指令稳定性 + 编辑闭环”。这恰恰是 OpenAI 一贯的路线:不追单点最强,而是构建可规模化使用的能力平台。
更值得注意的是——这次模型是免费开放给所有 ChatGPT 用户,同时 API 直接可用。这意味着它并不是一个“展示型发布”,而是明确冲着生态和落地去的。
往前看,GPT-Image-1.5 可能只是一个开始。当图像生成具备稳定编辑能力、文本渲染能力和结构理解能力之后,下一步自然会走向:
设计 → 自动化
创意 → 模板化
内容生产 → 系统化流水线
AI 最后不再只是“帮你画一张图”,而是逐步接管从构思、生成、修改到交付的整个视觉生产过程。
-End-
原创作者|李洛勤

📢📢来抢开发者限席名额!点击下方图片直达👇

感谢你读到这里,不如关注一下?👇























 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









