




👉目录
1 失败点 1:背景缺失——缺少项目级指导原则的 SPEC
2 失败点 2:评审缺位——对 AI 生成的 SPEC 缺乏严格审查
3 查失败点 3: 过度设计——在 SPEC 阶段陷入“分析瘫痪”
4 失败点 4:规约与实现解耦——在“意外”产生时绕过 SPEC 直接修改代码
5 失败点 5:流程形式化——为赶进度而牺牲 SPEC 流程
6 小结
AI 辅助编码正在改变我们的工作方式,开发者的重心也随之转移——从逐行实现代码,到更高层次的设计与指导。SPEC 驱动开发,正是将我们的设计意图精确传达给 AI 的关键方法。然而,要将这种新范式成功落地并非易事,实践中充满了常见的误区和挑战。本文聚焦于五个典型的失败场景,剖析了从思维到流程上的关键问题,并提供具体的应对策略,旨在帮助开发者真正掌握与 AI 协作的新方法,让它成为提升工程质量与效率的可靠伙伴。
关注腾讯云开发者,一手技术干货提前解锁👇
01
失败点 1:背景缺失——缺少项目级指导原则的 SPEC
失败场景
项目刚开始时,一个常见的错误是直接去编写具体功能的 SPEC。团队可能只给 AI 一个简单的指令,比如 "/speckit.specify Help me refactor the project..." ,然后期望 AI 能像人一样,自动理解项目的所有背景并给出好的设计。这种做法把 AI 当成了什么都懂的顾问,而不是一个需要清晰指令的工具。
这样做之所以会失败,是因为混淆了 AI “搜索信息”和“理解知识”这两种能力。SPEC 工具能通过 codebase_search 告诉你“代码里有什么”,但它没法告诉你“当初为什么要这么设计”。如果你给它的 SPEC 是基于不完整信息写的,那它只会忠实地把这个有问题的 SPEC 变成同样有问题的代码。
更重要的是,大量隐性知识——比如业务目标、过去的技术选型原因、重要的设计决策(比如为何用软删除)、团队内部的开发规范(比如日志格式)等——是无法直接从代码里看出来的。缺少这些信息,AI 的工作会变得低效且不可靠,最终让开发者误以为“SPEC 模式没用”。
正确策略
正确的做法是先定好规则,再开始干活。在为任何功能编写 SPEC 之前,应该先建立项目的“指导原则” (spec-guide)。这个文档,类似于 spekit 里的 constitution.md,应该成为团队的共识,用来记录那些代码本身无法表达的信息,至少要包括:
产品与业务背景:项目是做什么的,核心功能是什么。
技术设计原则:用什么技术栈,架构是怎样的,以及过去的关键决策。
结构与开发规范:代码目录怎么组织,文件怎么命名,API 风格,测试要求等。
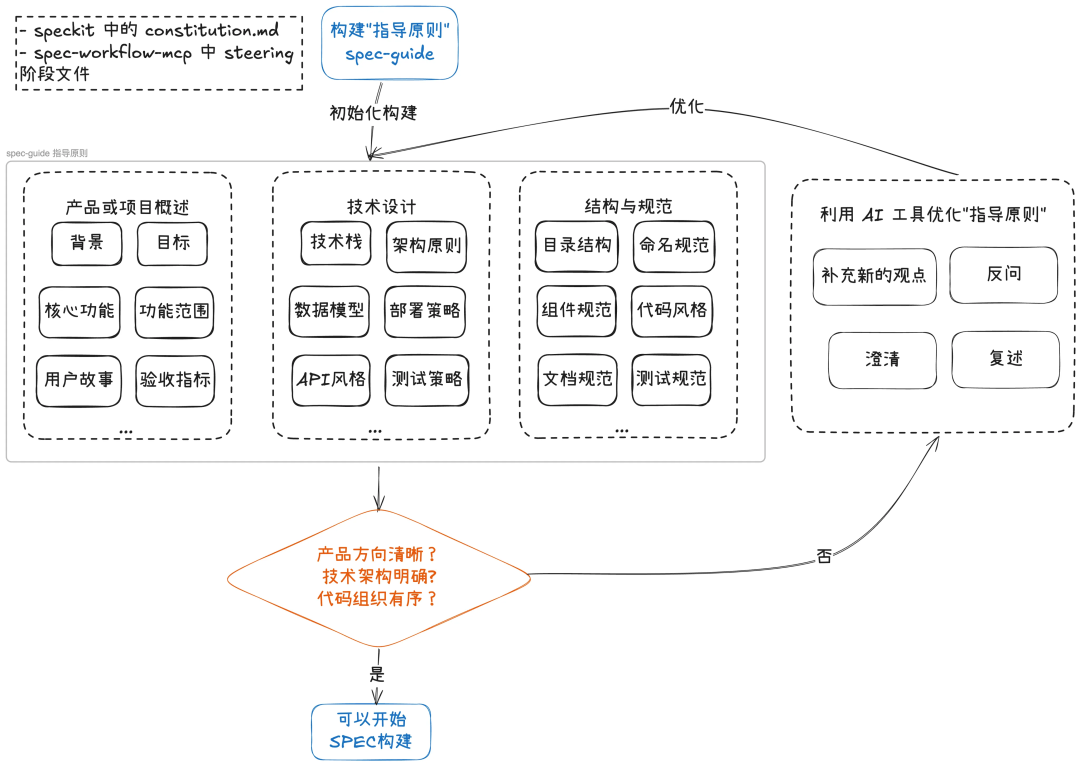
编写这份文档本身就是一个系统学习的过程。你可以让 AI 扮演提问和补充的角色,帮助你完善这份指导原则。只有当这份基础文档足够清楚,为 AI 提供了稳定的上下文之后,才能真正开始高效、可靠地编写 SPEC。
例如: 在使用 speckit 重构我们某项目时,可以从多个角度,反复优化生成 constitution.md 文件,形成对后续 SPEC 的指导。
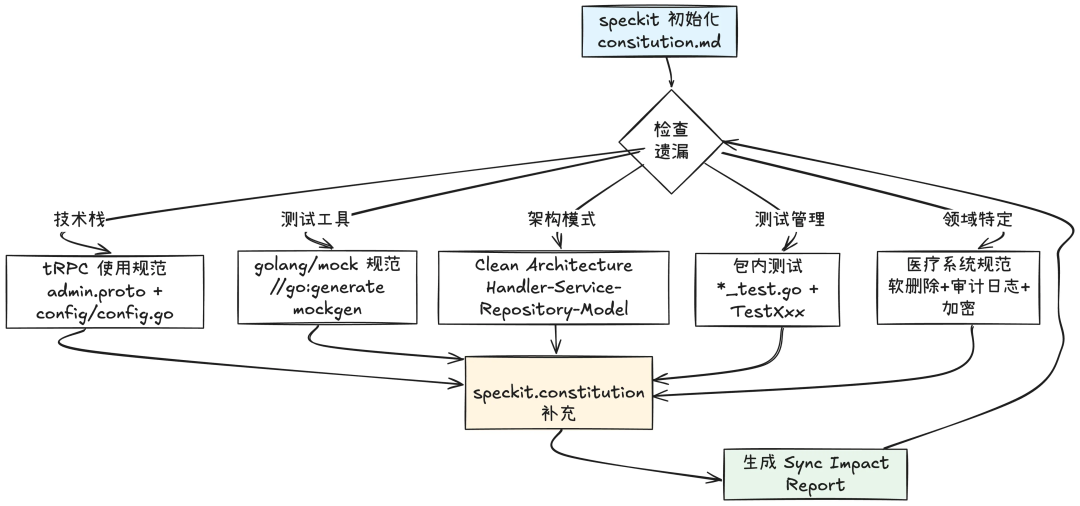
AI工具实践范例
利用 speckit.constitution 初始化项目“宪法”,可以直接运行初始化constitution.md 文档。随后,可以重复运行补充所需要的内容。如:
/speckit.constitution 增加测试规范: mock 文件通过 go:generate mockgen 生成,并于与测试代码放在同一个包package文件夹下面02
失败点 2:评审缺位——对 AI 生成的 SPEC 缺乏严格审查
失败场景
当开发者对业务或技术不熟时,容易搞错自己的角色:把自己当成提需求的,把 AI 当成解决所有问题的架构师,希望 AI 能自动补上自己不懂的地方。在这种情况下,AI 可能会生成一份看起来很详细的 SPEC,但里面可能充满逻辑漏洞。由于开发者没有严格审查,这个有问题的方案就被直接采纳了。AI 会精确地把错误的方案变成错误的代码,最终让开发者得出“SPEC 不可靠”的结论。

正确策略
正确的做法正好相反:开发者必须承担“架构师”的责任,把 AI 当作一个高效的辅助工具。这意味着,AI 生成的初版 SPEC 只是讨论的起点,而不是最终的指令。
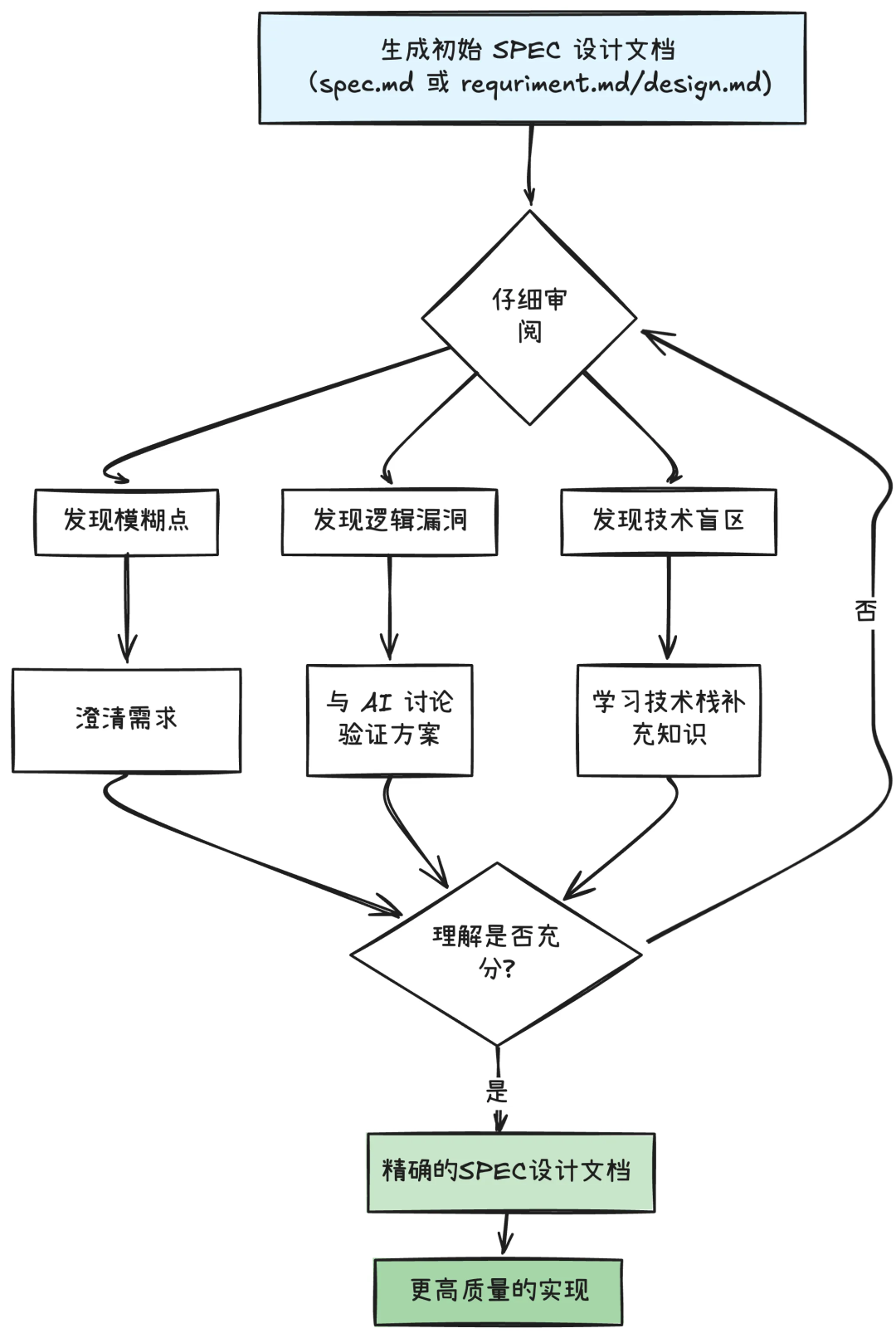
整个过程应该遵循一个“审阅-挑战-修正”的循环:
仔细审阅:把 AI 生成的初版 SPEC 当作一份需要严格检查的草稿。
发现问题:主动从中找出描述模糊的地方、逻辑上的漏洞和自己不懂的技术点。
交互式学习:
针对模糊点,通过追问来明确需求。
针对逻辑漏洞,和 AI 讨论其他方案,看哪个更可靠。
针对技术盲区,把它当成一次学习机会,补上自己的知识短板。
通过这个循环,把一份粗糙的草案不断迭代,直到它成为一份逻辑清晰、细节明确的 SPEC。SPEC 的真正价值在于,它提供了一个框架,通过与 AI 的反复沟通,让你系统地思考并加深对问题的理解,最终交付高质量的成果。
AI工具实践范例
首推speckit.clarify 工具做澄清。可以直接运行该命令,或如下指定关注点如:
/speckit.clarify 哪些具体模块需要解耦?目标测试覆盖率是多少?如何处理tRPC服务的模拟?如何在重构过程中确保审计日志的完整性用反问的模式,挖掘隐性上下文与潜在风险,范例 prompt:
<@需求文件> 生成一份问题清单,以帮助我思考其中未明确说明的方面。清单应重点关注:
1. 业务目标与动机:此功能或设计背后的根本原因是什么?它为谁解决什么问题?2. 未声明的约束:是否存在任何潜在的技术、预算或时间限制?3. 范围边界:哪些是明确不在此次范围内的相关功能?4. 风险与依赖:此方案可能引入哪些风险?它依赖于哪些外部系统或数据?03
失败点 3: 过度设计——在 SPEC 阶段陷入“分析瘫痪”
失败场景
在 SPEC 阶段,团队常常陷入一个矛盾:宏观上想得太多,微观上又定义得太模糊。一方面,担心未来的变化,试图设计一个能应对所有情况的“完美”架构,导致设计阶段拖延很久,无法开始。另一方面,在具体的规范描述里,又充满了像“优化性能”、“返回必要信息”这样模糊的话。这些话人能大概理解,但对于需要精确指令的 AI 来说却无法执行,导致它生成的代码充满不确定性,也让 SPEC 失去了作为验收标准的作用。
正确策略
有效的策略是通过拆分和追求确定性来解决这个问题。
拆分 SPEC,把大事化小:把大的项目或需求不断拆解,直到每个子需求的 SPEC 都满足两个条件:目标单一明确;能在很短时间(比如半天到一天)内完成。这能有效避免在宏观上过度设计,让团队始终专注于小的、可交付的功能点。
追求确定性,消除模糊:为 AI 编写的 SPEC 必须是可执行、可验证的。可以做个简单的“角色扮演测试”来检查其质量:
需求 (requirement.md):一个测试工程师,只看这个文档能不能写出完整的测试用例(包括边界和异常情况)?文档里必须有可量化的标准,而不是模糊的描述。
设计 (design.md):一个下游(比如前端)开发者,只看这个文档能不能开始对接工作,而不需要再问问题?API 约定、数据结构和交互协议必须是精确的。
任务 (tasks.md):一个不了解背景的程序员,只看这个文档能不能在几分钟内开始写代码?每个任务都应该是独立的、具体的操作指令。
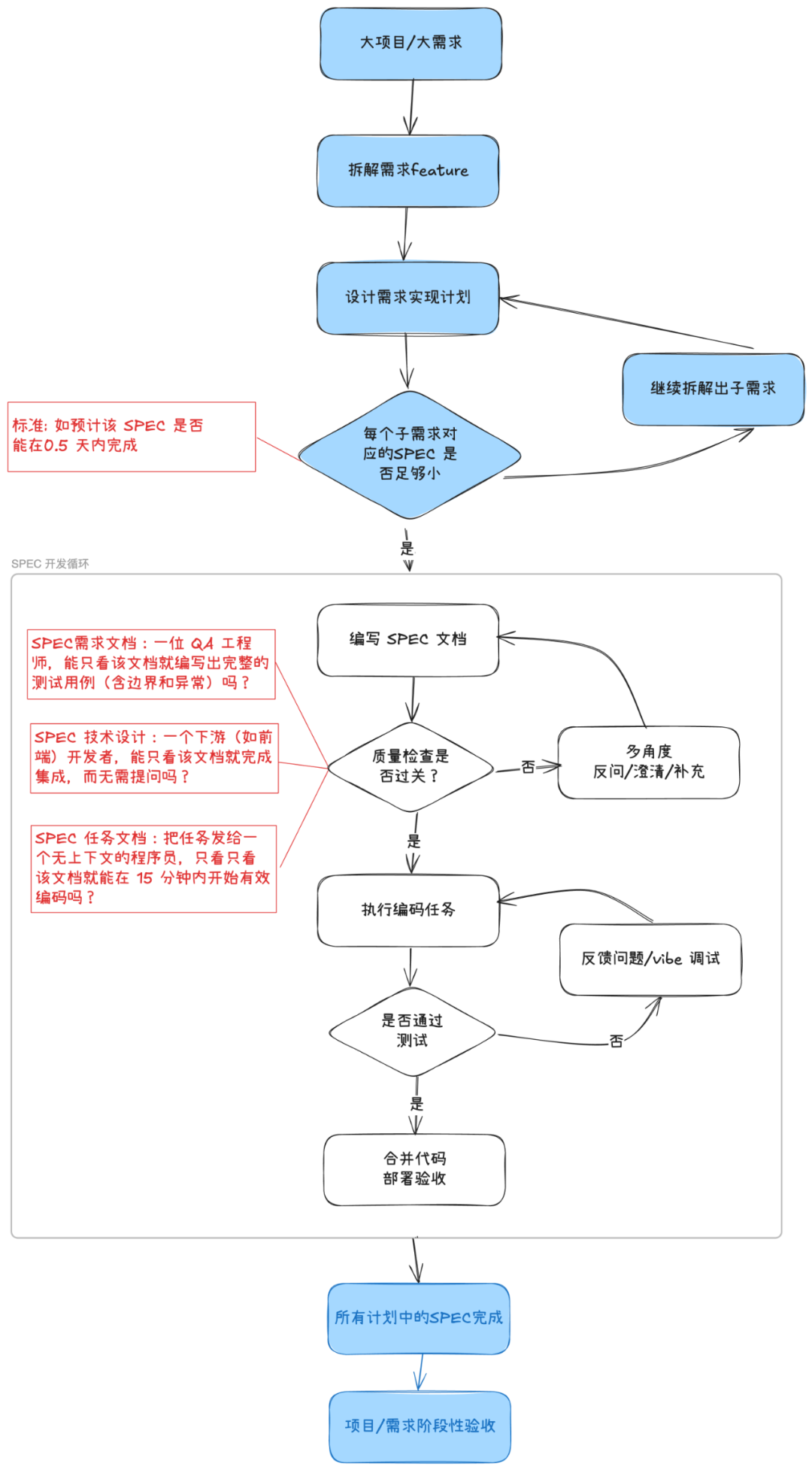
通过这种方式,SPEC 不再是模糊的设计图,而是变成了一系列具体、可执行、可验证的指令,从而确保 AI 高效、准确地工作。
例如: 需求要重构业务中的解耦式工作流服务。
错误的“大而全”SPEC 范例:

以下是真正能落地基于需求拆解后的 SPEC 流程,可演进和迭代,且能动态调整。
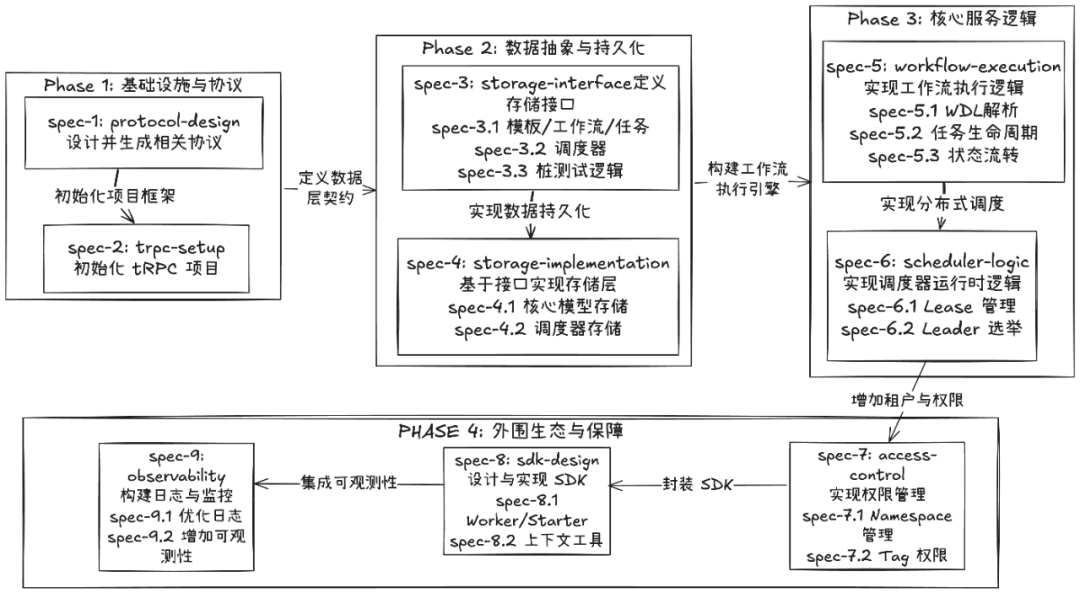
AI工具实践范例
基于 tapd 需求做初步分解(需 tapd mcp)
请分析tapd需求<tapd url>,并将其拆分为多个独立的子需求。
在拆分时,你必须严格遵循以下原则:1. 单一目标原则:每个子需求必须只解决一个核心问题或实现一个明确的业务目标。2. 短期可交付原则:每个子需求从 SPEC 编写到开发完成的工作量,应控制在 0.5 到 1 个工程日内。3. 垂直切分原则:优先创建端到端的、可独立验证的功能切片(例如,“用户能上传头像”),而不是按技术分层(例如,“完成后端接口”、“完成前端页面”)。4. 独立性原则:尽可能减少子需求之间的依赖关系,以便于并行开发。
请根据以上原则,将下面的需求进行拆分,并按照以下格式输出每一个子需求:
* 子需求标题: [一个清晰、简洁的标题]* 单一目标: [用一句话描述这个子需求要实现的唯一目标]* 关键验收标准: [列出 2-3 个核心的验收条件,以确认目标已达成]* 依赖关系: [指出它依赖于哪个其他的子需求,或写“无”]* 工作量评估理由: [简要说明为什么这个工作量适合在 0.5-1 天内完成]04
失败点 4:规约与实现解耦——在“意外”产生时绕过 SPEC 直接修改代码
失败场景
这是 SPEC 实践中最容易出问题的地方。当出现需求变更、设计遗漏或严重 BUG 时,团队为了图“快”,往往会绕过规范,直接修改代码。这种“先改代码,有空再补文档”的想法,是导致整个模式失败的直接原因。一旦第一个补丁被直接打上,代码就和 SPEC 不一致了。随着这种改动越来越多,SPEC 文档很快就变成了没人维护的过时文档,SPEC 驱动开发的基础也就不存在了,之前的所有投入都白费了。
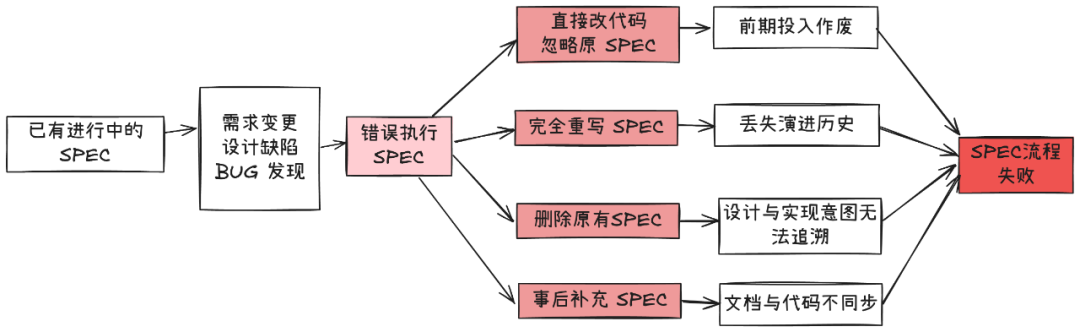
正确策略
正确的做法是:把变更本身也当作一个需要通过 SPEC 来管理的需求。遇到任何意外情况,都应该先调整 SPEC,而不是直接去改代码。
评估变更影响:首先判断当前 SPEC 的执行到了哪一步。如果正在执行任务(Tasks),应立即停下来,避免基于旧的规约产生更多无用代码。
选择变更路径:
继承式修改:如果变更只是局部的调整或修复,应在原来的 SPEC 基础上进行修改和扩展。保留历史版本,清楚地标出改了什么,形成一条可追溯的变更记录。
开启新 SPEC:如果变更导致核心目标完全变了,就应该果断地开启一个全新的 SPEC 来重新设计,并明确废弃旧的 SPEC。
同步更新:如果变更引入了新的设计原则或技术(比如加了一个新的消息队列),必须同步更新项目的“指导原则”(Constitution),确保顶层设计也保持最新。
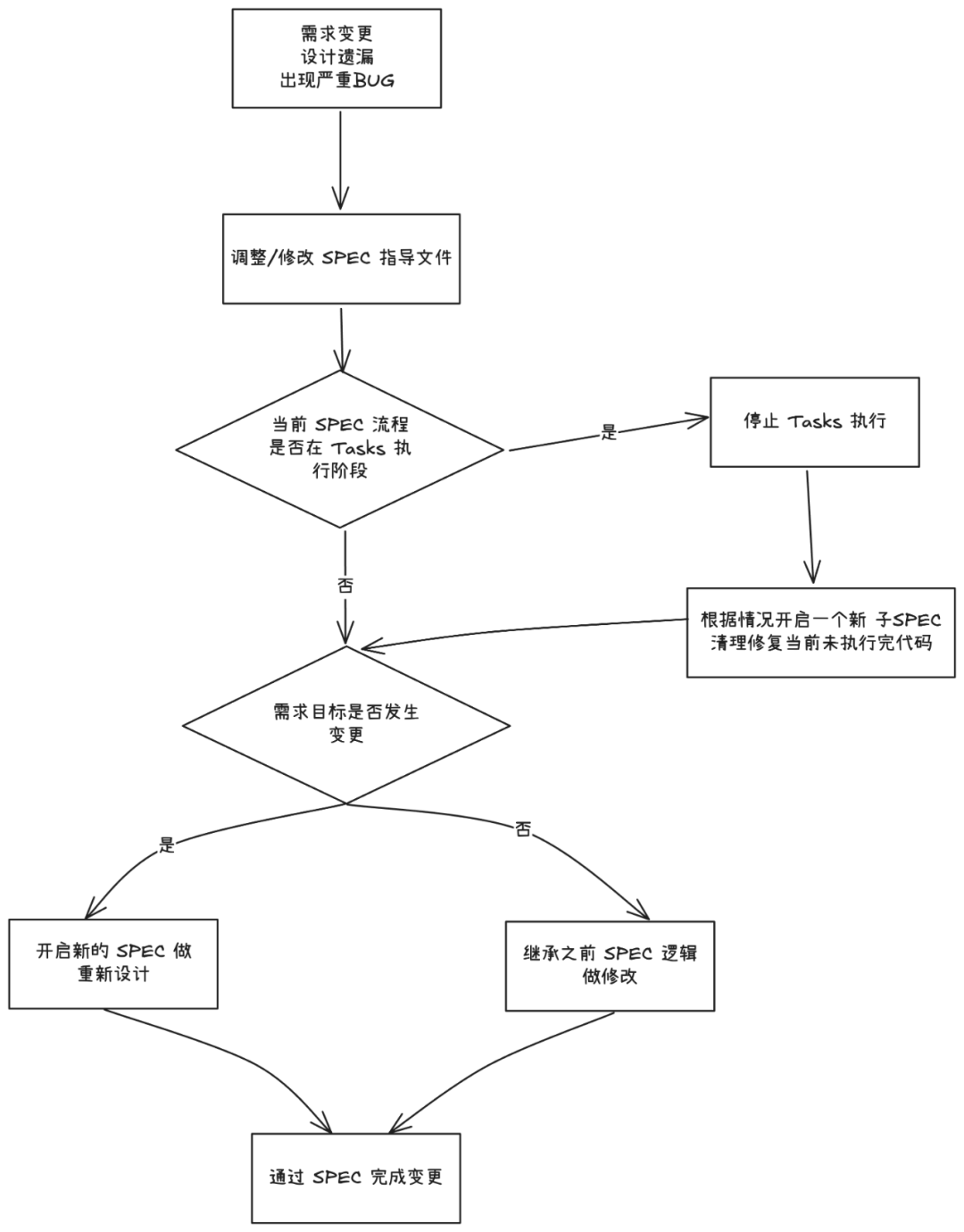
管理变更的核心思想,是保护和复用之前在规约上花费的精力。通过建立一个规范的变更流程,将所有改动都纳入 SPEC 的管理之下,才能确保 SPEC 始终是项目的“活文档”,持续让 AI 高效、准确地工作。
AI工具实践范例
使用 /speckit.analyse 自动检测生成的文档中冲突和模糊点(会生成一个一致性报告),并根据分析结果修正文档(可着重强调关注点)
在需求或设计变更时,给执行到一半的 tasks.md 做终止声明的 Prompt范例:
结合新的需求变更描述,请对 Tasks.md 文档执行终止操作,并生成更新后的完整内容。
操作规则如下:1. 添加终止声明: 在文档的最顶部,插入一个“终止声明”区块,说明终止的原因和时间。2. 修改任务状态: 遍历所有任务,将所有未完成的任务(如 `[ ]`, `[In Progress]`, `[TODO]` 等状态)的状态标记更改为 `[Obsolete]`。已完成的任务(如 `[x]`, `[Done]`)状态保持不变。3. 生成影响范围评估: 在文档的末尾,添加一个“影响评估”部分,其中应包含两个列表: * 已完成的任务列表。 * 被标记为 `[Obsolete]` 的未完成任务列表。05
失败点 5:流程形式化——为赶进度而牺牲 SPEC 流程
失败场景
当项目面临交付时间突然缩短的压力时,规范的流程往往最先被放弃。团队容易陷入一个严重的误区:把写 SPEC 和评审看成是多余的流程负担,转而去走“捷径”——绕过规范,直接让 AI “快速搞定”。这种因为恐慌而放弃规则的做法,短期看好像是快了,但由于大量未经充分设计和评审的 AI 代码被引入,很快就会在集成阶段集中爆发问题,导致更长的调试和返工时间。结果往往是想快也快不起来,反而延误了交付。
正确策略
面对紧急需求,正确的思路是把 SPEC 看作是高压下的决策工具,而不是开发的累赘。在紧要关头,你的价值不在于“写得更快”,而在于“决策更准”。
一份清晰的 SPEC 此刻不是阻碍,它能帮助团队明确目标,守住底线:
用 SPEC 量化影响,不做口头承诺
当有新需求进来,一份结构化的 SPEC 能让你快速评估它对现有设计的影响和具体工作量(tasks)。这让你能拿出事实和数据去沟通,比如:“增加这个功能需要修改 3 个模块,预计增加 2 人天”,而不是凭感觉说“可能来不及”。
用 SPEC 做取舍,而不是全盘接受
如果时间确实不够,最有效的办法是在需求层面和产品负责人一起,有策略地砍掉或推迟优先级低的功能。这是一种主动的范围管理,好过在代码层面硬扛所有需求,最后导致项目质量彻底失控。
用 SPEC 拆解任务,实现高效并行
一份拆分得当、任务独立的 tasks.md 能让并行开发成为可能。你可以放心地把这些任务分给不同的人,甚至多个 AI Agent,因为任务间的依赖和边界已经定义清楚了。这能让团队里的每个人(或 AI)都同时开工,提升开发效率。
核心原则:不要自己加速,而是驱动 AI 加速;不要打破规则,而是在规则内寻找最优路径。
错误逻辑(执行者) | 正确逻辑(指挥者) |
"没时间写文档,直接改代码" | "用 30 分钟规划,节省 2 天返工时间" |
"AI 生成什么就用什么" | "用提示词驱动 AI 生成最优方案" |
"先实现功能,规范以后再说" | "用 Urgency Mode 在规范内快速实现" |
"测试太慢,上线后再补" | "Test-First 确保一次成功" |
AI 工具实践范例
speckit.plan 阶段 - 强制简化实现
/speckit.plan 需求 URGENT。实现上求简求快,忽略非关键问题,除非必要,否则所有配置均使用默认值。speckit.tasks 阶段 - 最小化任务,最大化并行
/speckit.tasks 最小化任务数量,最大化任务并行度,并为每项任务提供大致的时间估算。06
小结
SPEC 是保证 AI 编码质量的“规矩”
别把 SPEC 看成简单的任务列表。它其实是一套保证代码质量的流程和标准。通过前期定好规则、中期严格评审、后期管理好变更,就能确保 AI 生成的代码靠谱、不出乱子。
SPEC 不是银弹,它也有自己的问题
SPEC 流程并不完美。例如,写详细的文档很费 Token;现在还没有好用的管理工具,很多事都得靠人自觉;这个流程本身也容易导致想得太多不敢动手,或者一忙起来整个团队可能就是只是形式上遵守标准。
想用好就得在实践中摸索和迭代
SPEC 这套方法论,必须在实际项目中不断应用和总结才能掌握。这个领域和相关工具(像 speckit)都还在快速变化,想真正让 AI 帮你高效、高质量地写代码,就得边用边总结,同时跟上新工具和新方法的节奏。
SPEC 与 Vibe Coding 并非对立,而是互补
坚持用 SPEC 不代表要彻底放弃 Vibe Coding。在探索新技术栈、摸索新业务或快速验证产品想法时,Vibe Coding 的自由探索依然不可或缺。关键在于,我们可以有意识地沉淀 Vibe 过程中的成功经验和踩坑教训。例如,可以先变化为具体的规范(Rules),再用这些 Rules 来指导生成更靠谱的 SPEC 文件,把自由探索的成果,变成未来规范开发的基础。
SPEC 相关工具
spec-kit: https://github.com/github/spec-kit
OpenSpec: https://github.com/Fission-AI/OpenSpec
spec-workflow-mcp: https://github.com/Pimzino/spec-workflow-mcp
-End-
原创作者|朱邦义

📢📢来抢开发者限席名额!点击下方图片直达👇


你对本文内容有哪些看法?同意、反对、困惑的地方是?欢迎留言,我们将邀请作者针对性回复你的评论,同时选一条优质评论送出腾讯云定制文件袋套装1个(见下图)。12月12日中午17点开奖。
























 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









