





👉目录
1 问题的本质:当调度器成为性能瓶颈
2 本工作的核心贡献
3 解决方案:赋予调度器语义感知能力
4 设计原则:生产环境的考量
5 性能评测:数据说话
6 实现细节:魔鬼在细节中
7 从技术到哲学:重新定义调度器的认知边界
8 总结
在开源技术峰会上与Linus Torvalds同台论道时,我们讨论了内核设计中一个常被忽视的命题:优雅的系统并非源于复杂的算法,而是源于对"语义"的深刻理解。台上短暂的交流、晚宴时关于调度器哲学的探讨,都在反复印证同一个观点——代码的优雅来自对意图的精准表达。那场对话之后的几个月,我将这个洞察带入了KVM调度器的重构——结果是在高密虚拟化环境下实现了Dedup工作负载47.1%的性能飞跃。
关注腾讯云开发者,一手技术干货提前解锁👇
当虚拟化调度器学会“读懂”语义:高密场景下47%性能飞跃的背后
在云计算时代,虚拟化技术的极限往往不是硬件性能的天花板,而是调度器能否理解工作负载的真实意图。高密场景当vCPU竞争物理核心时,传统调度器像一个只会机械执行规则的裁判,而我们需要的,是一个能够洞察比赛本质的智者。
这篇文章记录的,是一次对Linux内核调度器的深度重构——通过赋予KVM调度器“语义感知”能力,我们在高密虚拟化环境下实现了Dedup工作负载47.1%的性能提升。这不是简单的参数调优,而是对调度器认知模型的根本性升级。
在云厂商的调度体系里,真正决定集群上限的,从来不是某一块网卡或某一代CPU,而是调度器对“谁该先跑”这个问题的回答质量。这篇文章讲的,不是某个内核patch的小修小补,而是一整条调度路径在高密环境下的重新定义。
如果把近十年的虚拟化扩展工作粗略划分,一类依赖硬件特性演进(APICv、Posted Interrupt、VMFUNC),一类依赖Guest内的准虚拟化协议(PV spinlock、PV TLB)。而我们走的是第三条路径——在Host调度器这一层,以极低的语义注入成本,直接重写高密虚拟化的性能边界。这不是在某个已有方向上做增量改进,而是在探索一个此前被低估的优化维度。
01
问题的本质:当调度器成为性能瓶颈
在高密部署场景下,多个虚拟机共享有限的物理CPU资源。当Guest内部的vCPU因等待锁而自旋时,KVM的准虚拟化spinlock机制会触发yield_to()调用,试图将CPU时间片让渡给持锁的vCPU。这个设计理念是优雅的——让出CPU给真正需要运行的任务。
然而,现实远比理想复杂。问题不在于yield_to()的设计思想有误,而在于它的实现假设了一个早已不复存在的世界:没有深层Cgroup嵌套、没有EEVDF调度器、没有大规模IPI通信。当这些假设一个个失效,优雅的设计就成了性能的陷阱。
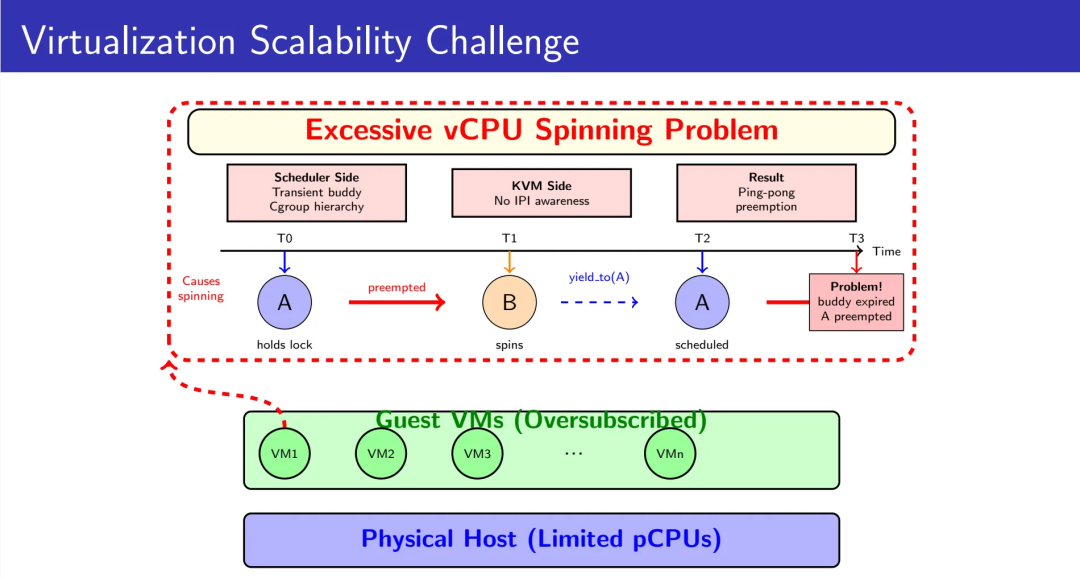
1.1 调度器侧的困境:一次性偏好的陷阱
当前的yield_to_task_fair()实现依赖set_next_buddy()机制来提供调度偏好。Buddy机制的设计初衷是提供“下一次调度决策”的瞬时优先级——它是一个临时的、一次性的提示。一旦目标任务被调度运行,buddy标记立即被清除。
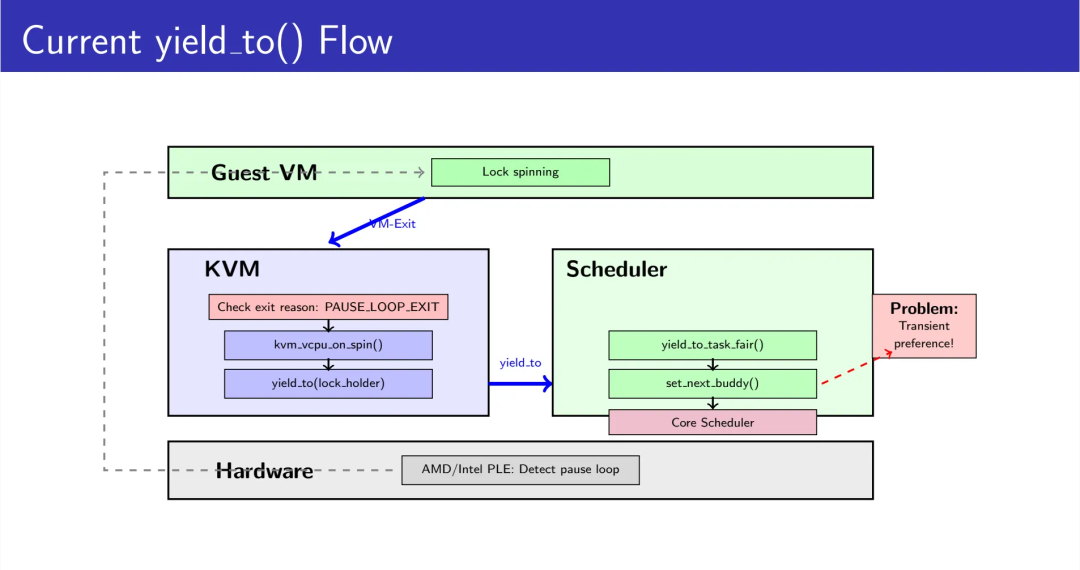
问题在于,buddy机制的一次性特性会导致严重的乒乓抢占问题。

时间线展现了这个困境:
T0时刻:vCPU-B执行yield_to(vCPU-A),set_next_buddy(vCPU-A)生效
T1时刻:vCPU-A被调度运行,buddy标记立即清除
T2时刻:再次调度时,回退到vruntime比较
T3时刻:vCPU-B重新抢占vCPU-A
结果:乒乓抢占。锁持有者vCPU-A刚获得CPU就被抢占,临界区无法完成,自旋者vCPU-B继续空转,再次触发yield_to()。这种恶性循环会导致大量无效的上下文切换和缓存颠簸。
从Guest视角看,这是一条平平无奇的自旋路径;从Host视角看,它是在用最贵的那几颗物理核,忙着做最没产出的那几轮context switch。表面上CPU利用率很高,实际上是把算力预算浪费在让错误的vCPU来回上台。
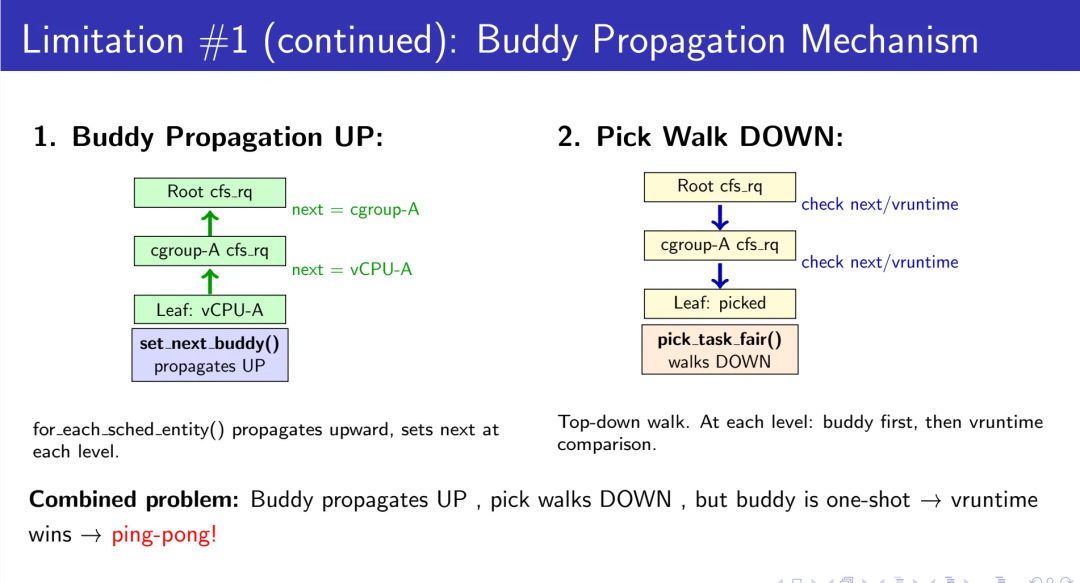
根本原因:Buddy机制propagate向上、pick路径walk向下,但一次性特性使其在层级化Cgroup结构中失效。没有vruntime调整的持久化偏好,调度器无法维持目标任务的优势。
这个bug的隐蔽之处在于,它只在三个条件同时满足时才显现:Cgroup嵌套、高密部署、频繁yield。这就是为什么它在社区存在多年却没被系统性解决——大多数人只遇到其中一两个条件,看到的是“偶尔的性能抖动”,而不是“结构性的调度失效”。
1.2 KVM侧的盲区:不知道该帮谁
传统的kvm_vcpu_on_spin()通过Directed Yield候选选择来识别应该boost的vCPU。它的启发式算法基于抢占状态:哪个vCPU被抢占了?哪个在内核态?
但这种策略存在严重的语义缺失。当vCPU-A发送IPI给vCPU-C然后自旋等待响应时,当前逻辑可能选择boost一个无关的vCPU-B(错误!),而不是真正的IPI接收者vCPU-C(正确!)。
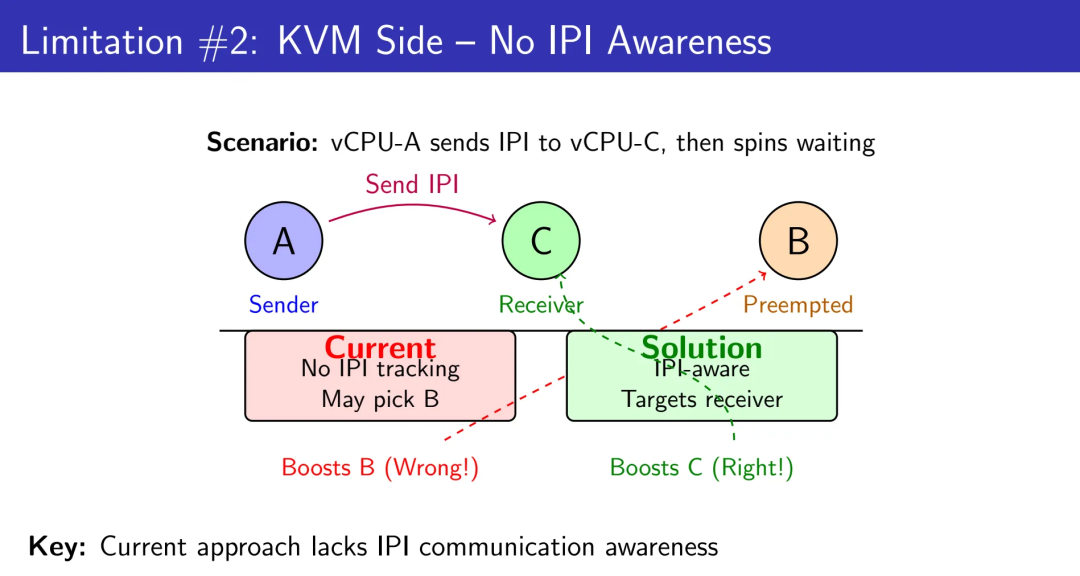
为什么?因为调度器缺乏对IPI通信关系的感知。它不知道vCPU-A在等谁的响应,不知道vCPU-C是TLB shootdown的目标,不知道这是一次跨核同步操作。在没有IPI语义的世界里,调度器只能凭抢占状态“猜测”谁是关键路径上的vCPU,而不是“知道”谁才是那个必须被立即叫醒的人。
这里有个反直觉的认知:在虚拟化环境中,最昂贵的不是“做错事”,而是“帮错人”。当你boost了一个无关的vCPU,不仅浪费了这次调度机会,还延长了真正关键路径上的阻塞时间,导致整个依赖链的雪崩式延迟。传统启发式的问题不是“不够聪明”,而是它在一个信息不完备的世界里试图做精准决策——这在数学上就是不可能任务。
02
本工作的核心贡献
在深入技术细节之前,有必要先明确这项工作在高密虚拟化调度领域的定位和贡献:
语义感知调度框架的系统化构建 提出一种可部署在现有KVM栈上、无需Guest修改的语义感知调度框架。通过vCPU Debooster机制,将Directed Yield从一次性的buddy提示升级为在Cgroup层级公平模型中维持的持久化调度偏好,从根本上解决了传统yield_to()在嵌套容器化环境中的失效问题。
因果链显式化的精准调度决策 提出IPI-Aware Directed Yield机制,将跨vCPU的处理器间通信因果链显式暴露给Host调度器。在不依赖新硬件特性、不引入Guest侵入性修改的前提下,将“帮谁”从基于状态的盲目启发式转化为基于语义的根因驱动决策,逼近关键路径调度的理论上限。
系统性实证与收益边界分析 在真实硬件和生产级工作负载上给出系统性评测,在Dedup/VIPS/Dbench等典型场景下展示14.4%–47.1%的稳定性能提升。更重要的是,通过对不同高密比例(2:1至4:1)的收益曲线分析,明确界定了语义感知调度在何种密度区间是第一性瓶颈,为云厂商的容量规划提供量化指导。
03
解决方案:赋予调度器语义感知能力
我们的方案包含两个正交且互补的机制。更重要的是,这两个机制共享同一条设计哲学:让调度器不再只看“状态”,而是开始理解“语义”。
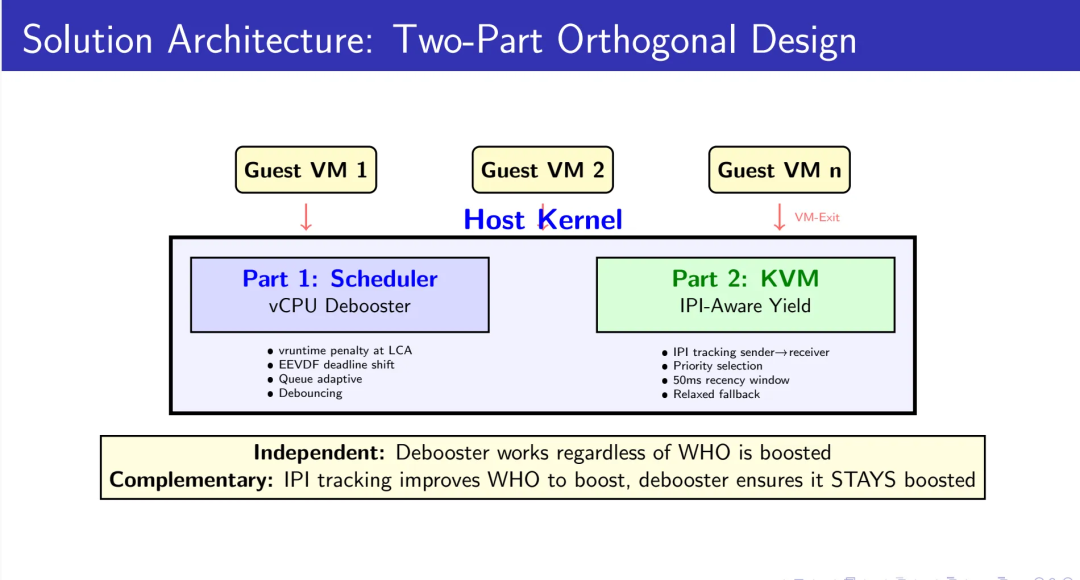
3.1 Part 1:调度器vCPU Debooster——持久化的调度偏好
核心思想:在Cgroup层级的最低公共祖先(LCA)处施加vruntime惩罚,为目标任务提供超越buddy机制的持续优势。
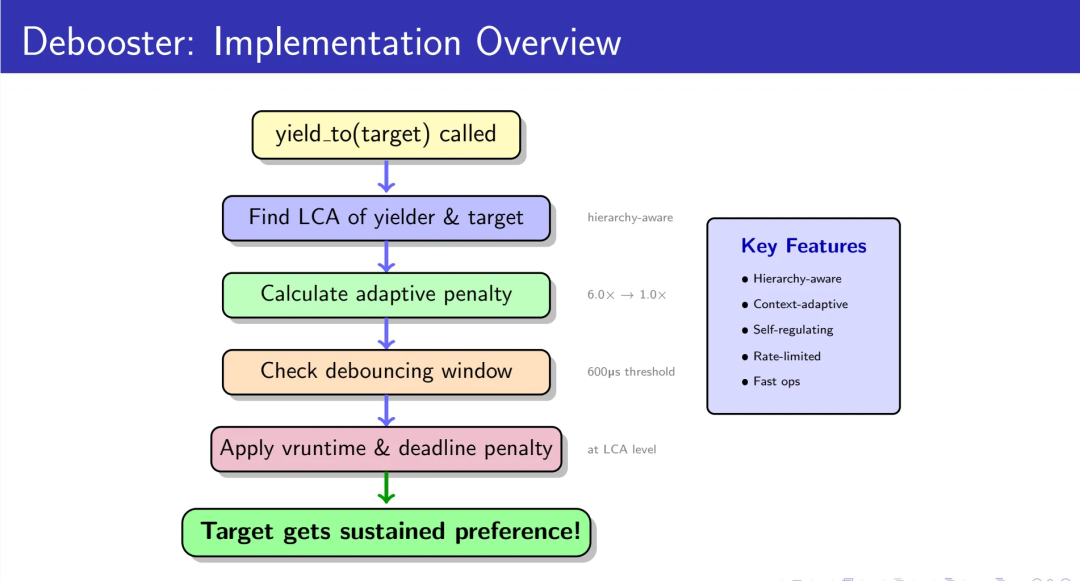
层级感知的惩罚放置
关键洞察:LCA是yielding vCPU和target vCPU真正竞争的层级。在LCA施加惩罚,可以让目标任务在后续的所有调度决策中持续获胜。
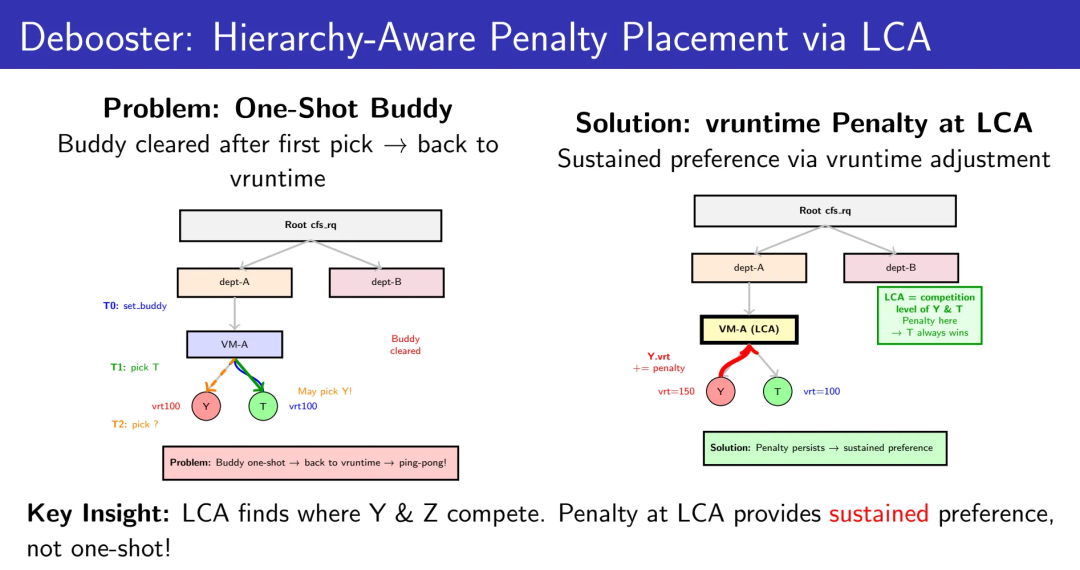
找到LCA后,我们在这个层级施加惩罚。这确保了即使在复杂的Cgroup嵌套结构中,目标任务也能保持调度优势。
这里的设计选择值得细说:为什么是LCA而不是其他层级?答案在于调度器的pick路径是自顶向下的树遍历——只有在LCA这个“分叉点”施加差异,才能确保每一次pick都看到这个差异。如果在更低的层级施加惩罚,那么当pick路径从更高层级选择了另一个分支时,你的惩罚就失效了;如果在更高层级施加惩罚,你影响的是整个子树,而不是特定的竞争关系。LCA是唯一精确的答案,这不是调参的结果,而是树结构的数学必然。
EEVDF一致性的惩罚应用
Linux 6.6引入EEVDF(Earliest Eligible Virtual Deadline First)调度器后,调度决策基于三个状态:vruntime(虚拟运行时间)、deadline(虚拟截止时间)、vlag(延迟标记)。
施加惩罚时,必须同步更新所有EEVDF字段以保持调度器状态一致性。增加yielding vCPU的vruntime,重新计算deadline,更新vlag以反映“过度服务”状态,并维护cfs_rq的最小vruntime。

效果:yielding vCPU看起来“已经运行了很久”,被自然地降低优先级。从调度器视角看,这是一次受控的“虚拟时间重写”:我们没有打破公平性,只是在正确的层级上,主动偏向真正能解锁进度的那条执行链。
这里有个微妙的工程权衡:为什么不直接减小target的vruntime,而是增大yielder的vruntime?因为EEVDF的数学模型中,min_vruntime是全局时钟,所有新唤醒的任务都以它为基准。如果你减小某个任务的vruntime,它可能掉到min_vruntime之下,破坏调度器的单调性假设,引发饥饿或优先级反转。而增大yielder的vruntime,相当于让它“透支了未来的配额”,这在EEVDF的公平性模型中是被自然支持的——就像一个任务运行太久会被惩罚一样。我们只是人为触发了这个惩罚,而不是等它自然发生。
自适应惩罚:平衡偏好与公平
惩罚力度不能一刀切。队列规模直接影响饥饿风险:
2个任务:6.0×调度粒度(强力推进,低饥饿风险)
3个任务:4.0×粒度
4-6个任务:2.5×粒度
7-8个任务:2.0×粒度
9-12个任务:1.5×粒度
超过12个任务:1.0×粒度(保守,避免饥饿)
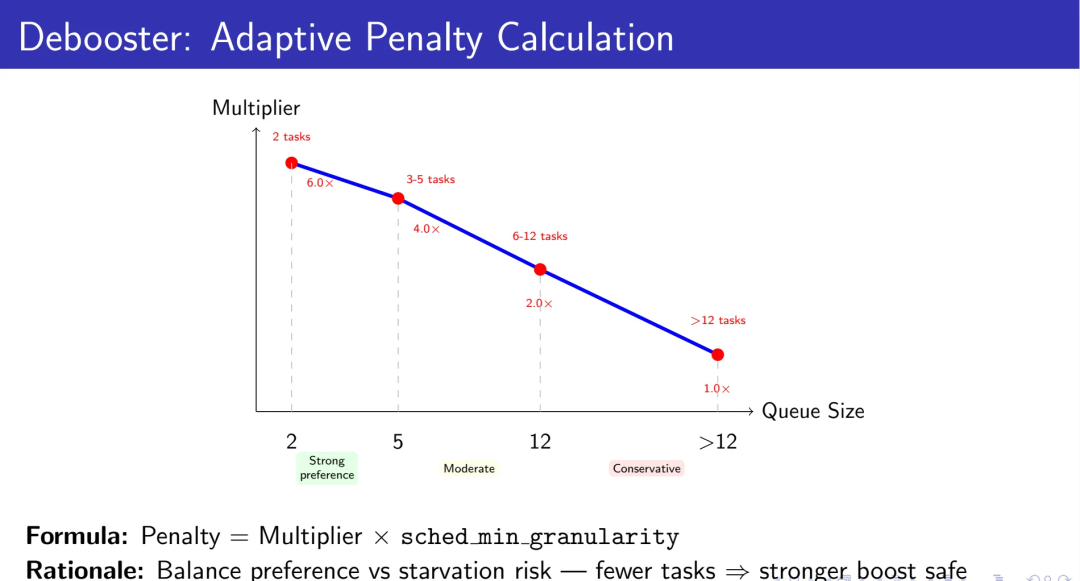
这种自适应策略在提供有意义的偏好和避免系统饥饿之间找到了平衡点。
这些数字不是拍脑袋决定的。在2任务场景下,6.0×粒度意味着yielder被“罚下场”足够长的时间,让target完成临界区;而在12+任务场景下,1.0×粒度只是提供“轻微倾向”,避免因过度惩罚导致其他无关任务饿死。曲线的斜率反映了一个基本事实:当竞争者越多,单个任务的“绝对优先级”就越难维持,你必须从“强制偏好”退化到“温和提示”。这不是妥协,而是在多目标约束下的最优解——既要保证锁持有者进度,又要保证整体系统的活性。
防抖动机制:识别乒乓模式
如果在600微秒内检测到反向配对(A yield to B,然后B yield to A),将惩罚减半。这防止了两个任务相互让步时的震荡放大。
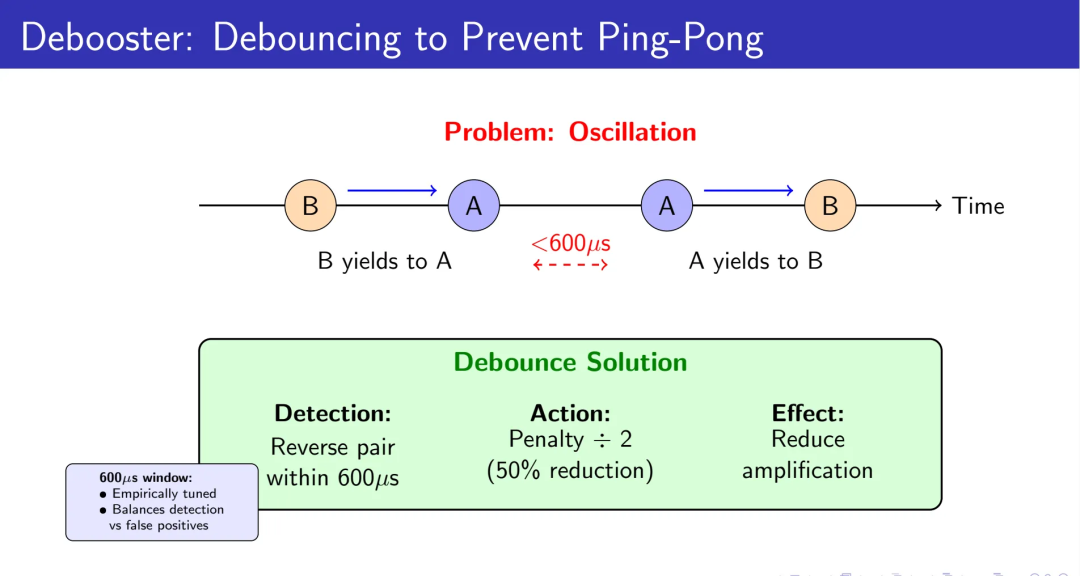
速率限制与效果验证
高频yield会导致病态开销。我们设置6ms的速率限制——在这个窗口内,同一个rq上的deboost操作只执行一次。这在性能和开销之间取得了实用的平衡。
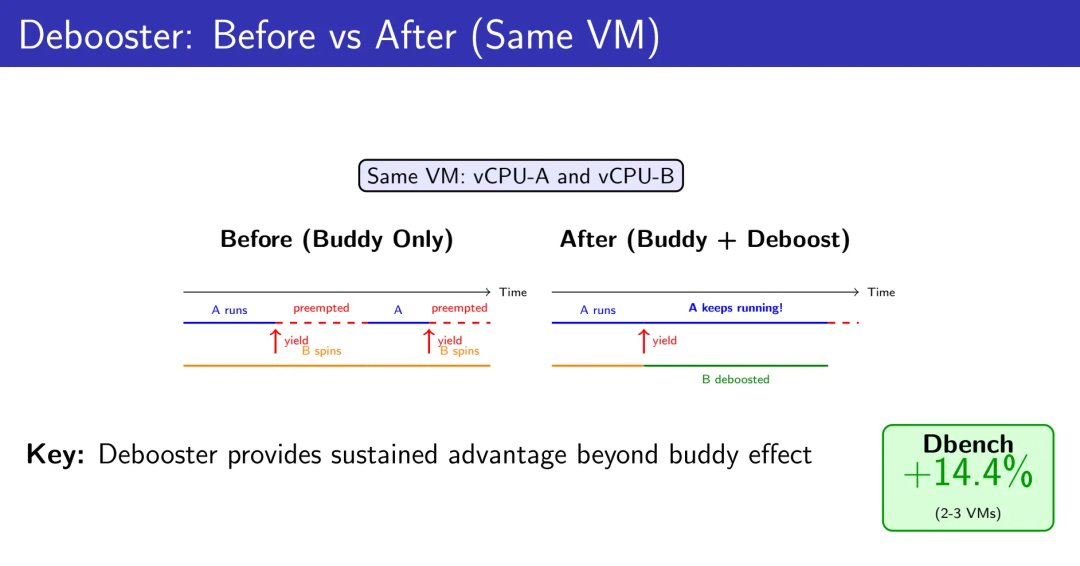
对比显示,Debooster提供的持续优势远超buddy效果。在Dbench测试中,2-3个VM的场景获得了14.4%的吞吐量提升。
3.2 Part 2:IPI感知的定向让步——精确的boost目标识别
如果说Debooster解决了“让目标持续运行”的问题,那么IPI-Aware机制解决的是“选对正确目标”的问题。
轻量级IPI追踪基础设施
Per-vCPU数据结构设计仅16字节,包含最近IPI发送者/接收者的vCPU ID、待处理IPI响应标记、以及IPI发送时的单调时间戳。
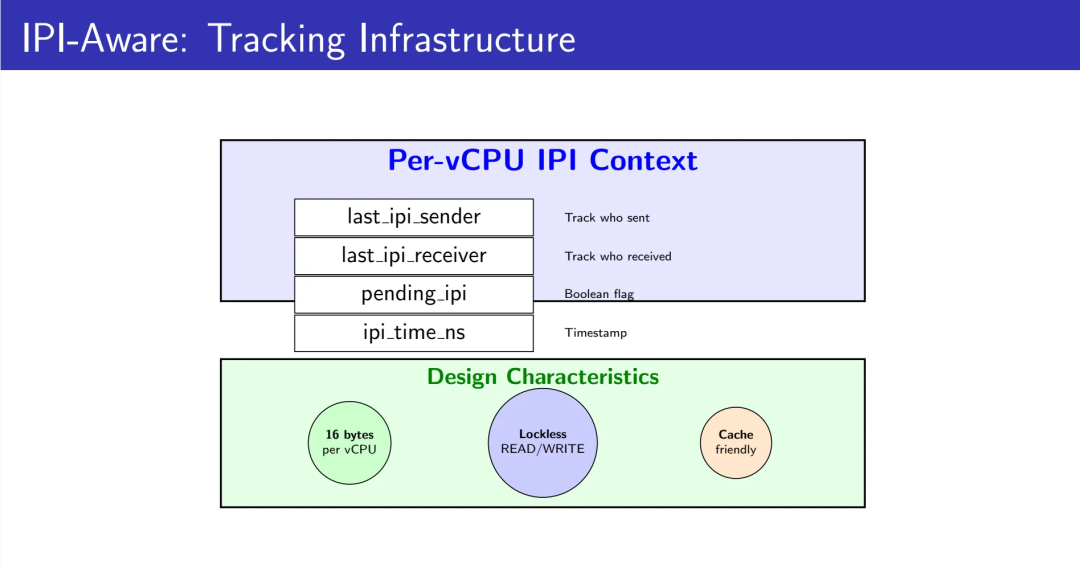
使用无锁READ_ONCE/WRITE_ONCE访问器,避免引入新的锁竞争。Cache友好的设计最小化性能影响。
16字节这个数字是精心设计的结果。现代CPU的cache line通常是64字节,一个cache line可以容纳4个vCPU的IPI上下文,这意味着在典型的8-16 vCPU虚拟机中,整个追踪数据集只占用2-4个cache line。更关键的是,我们用READ_ONCE/WRITE_ONCE而不是atomic操作——因为IPI追踪容忍短暂的不一致(最坏情况是错过一次优化机会),但不能容忍锁竞争的延迟(那会变成新的瓶颈)。这种“用正确性换性能”的权衡,是系统编程中最考验判断力的地方:你要精确知道哪些不变式是可以暂时违反的。
中断投递集成点
在LAPIC中断投递的目标解析之后进行hook,记录单播IPI关系。仅追踪LAPIC-originated、APIC_DM_FIXED模式、无shorthand、且恰好有一个目标vCPU的情况。这是处理器间同步的常见模式(spinlock、RCU、TLB shootdown等)。
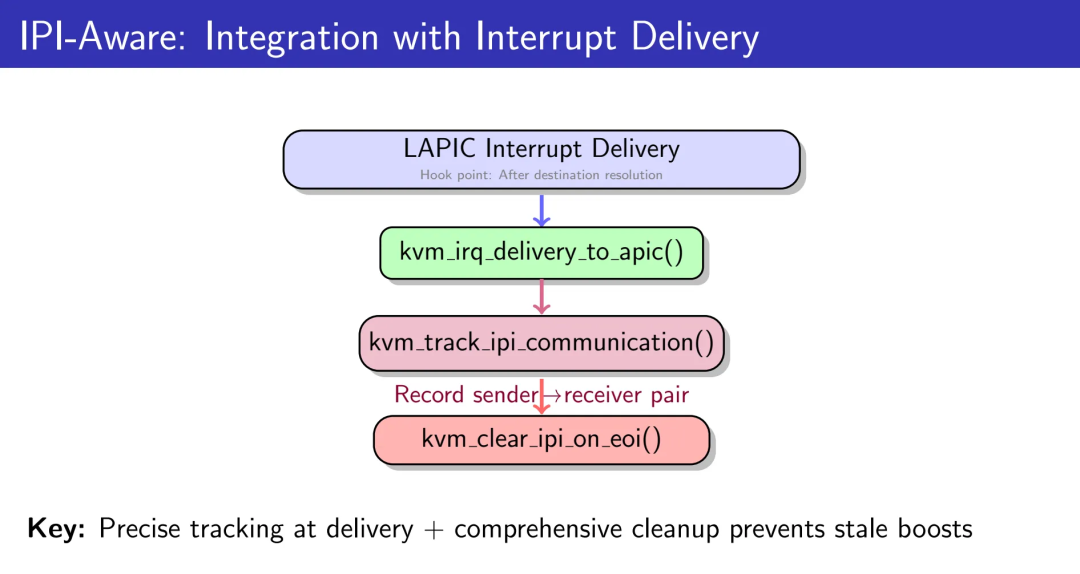
EOI时的精确清理
两阶段清理策略至关重要。第一阶段无条件清除接收者的IPI上下文(它已处理中断)。第二阶段有条件地清除发送者的pending标记:仅当发送者的last_ipi_receiver匹配当前接收者、IPI在时间窗口内(50ms)、且发送者vCPU仍然有效时才清除。
这防止了无关的EOI过早清除有效的IPI状态。在APICv/AVIC硬件加速中断投递的环境下,必须在两条EOI路径上都调用清理函数(软件模拟路径和硬件加速路径),否则在APICv启用的Guest中会保留陈旧的IPI状态,导致错误的boost决策。
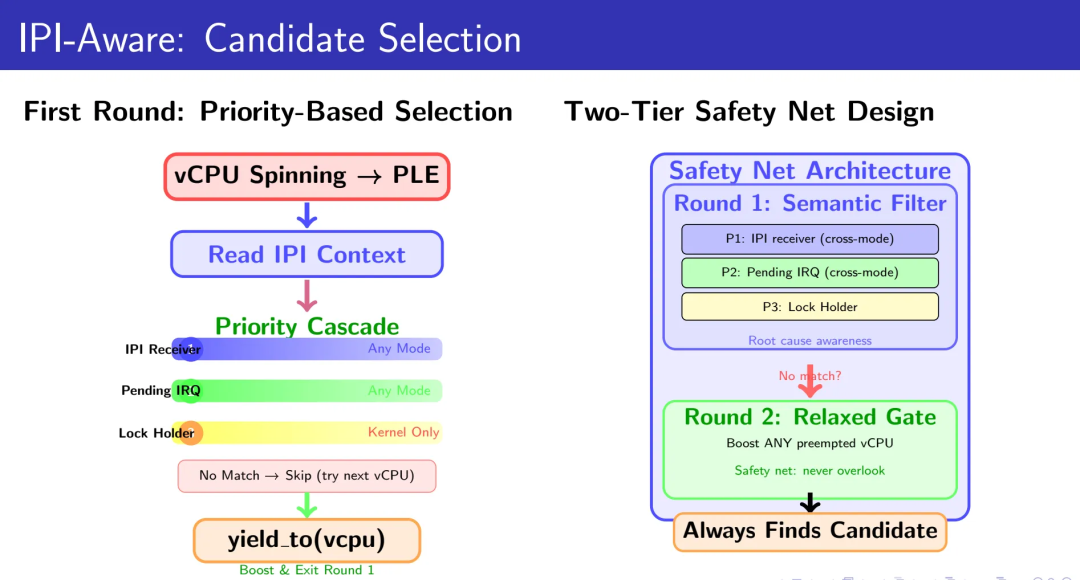
优先级级联的候选选择
三层优先级设计确保我们总能找到最合适的boost目标:
Priority 1:确认的IPI接收者(任何模式)——立即boost,根因感知
Priority 2:待处理中断的快速路径(任何模式)——架构特定的快速检测
Priority 3:内核态抢占的传统逻辑(仅kernel mode yield)——兼容现有工作负载
这一步,让曾经随机的“帮谁”问题,从启发式猜测变成了面向因果链的精准决策。
两轮回退安全网
第一轮使用严格的IPI感知选择,遍历所有vCPU寻找符合优先级条件的候选者。如果第一轮未找到候选者,第二轮放宽条件为“任何被抢占的vCPU”。这通过enable_relaxed_boost模块参数控制(默认开启),确保我们永远不会遗漏可以boost的机会。
04
设计原则:生产环境的考量
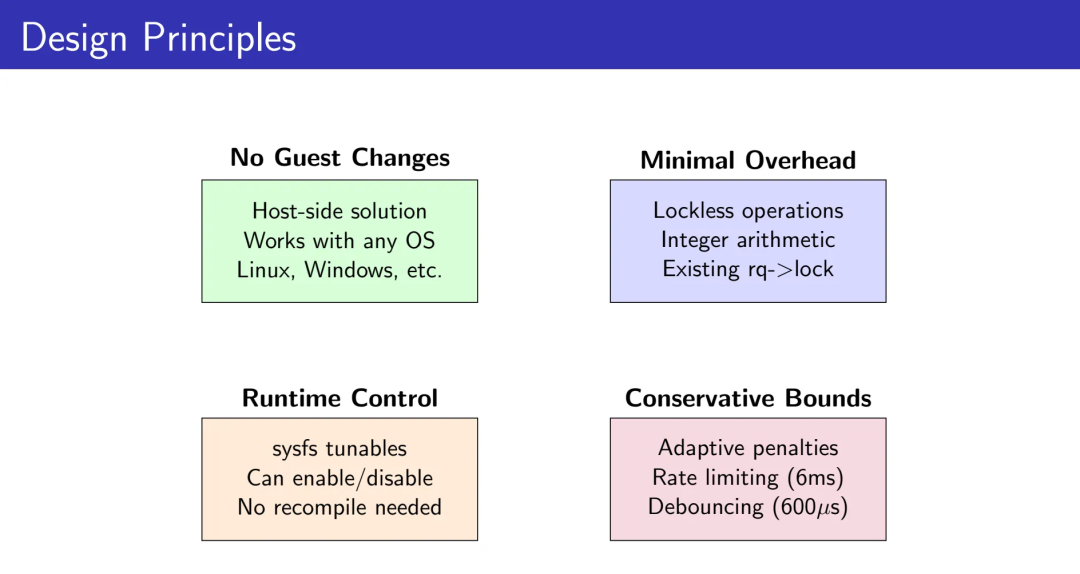
4.1 Guest无关性
完全在Host内核侧实现,无需修改Guest操作系统。适用于Linux、Windows等任何Guest OS。
4.2 最小开销
无锁操作(lockless IPI追踪)
整数算术(惩罚计算)
复用现有rq->lock(无新锁引入)
4.3 运行时可控
通过sysfs/debugfs动态控制,无需重新编译:
/sys/kernel/debug/sched/sched_vcpu_debooster_enabled
/sys/module/kvm/parameters/ipi_tracking_enabled
/sys/module/kvm/parameters/enable_relaxed_boost
4.4 保守边界
自适应惩罚、速率限制(6ms)、防抖动(600μs)、短时间窗口(50ms)——所有参数都经过实证调优,在性能和系统稳定性之间取得平衡。
05
性能评测:数据说话
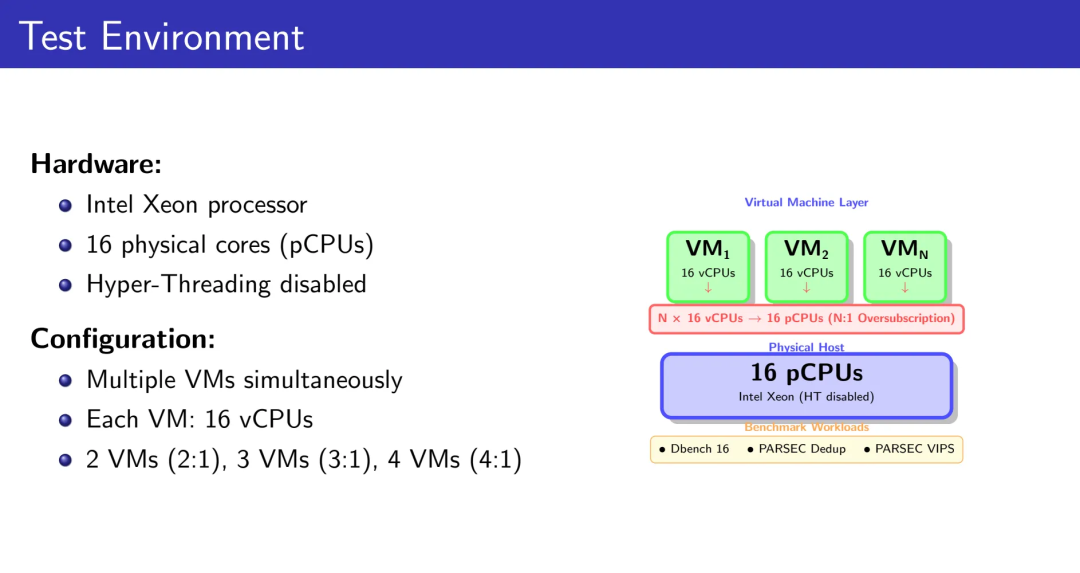
测试环境:Intel Xeon处理器,16物理核心(禁用超线程),每VM配置16个vCPU,N个VM在16个pCPU上形成N:1的高密部署。
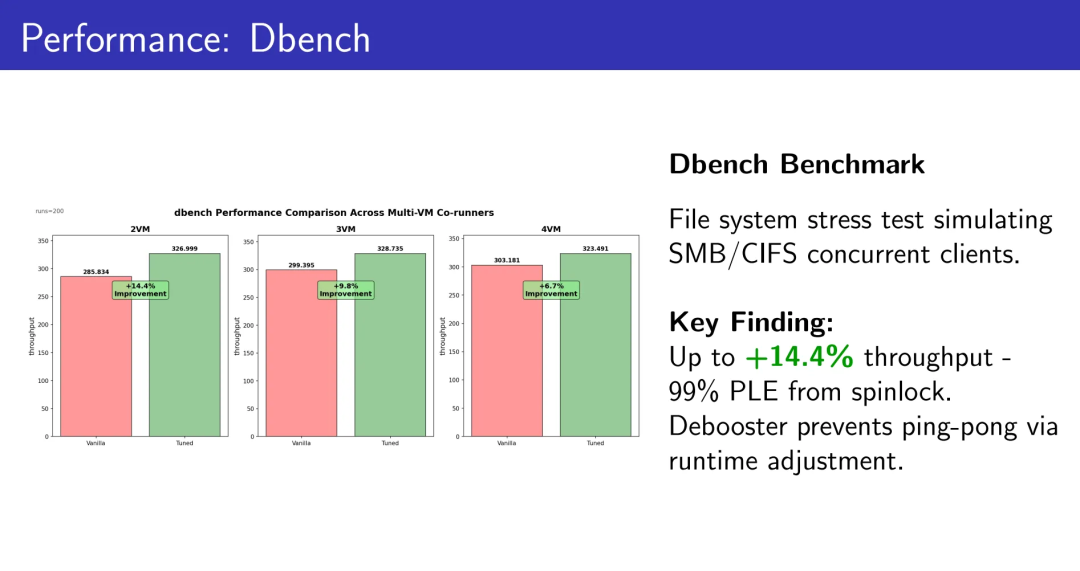
5.1 Dbench:文件系统元数据压力测试
模拟SMB/CIFS并发客户端的文件系统操作。
2 VMs:+14.4% 吞吐量
3 VMs:+9.8% 吞吐量
4 VMs:+6.7% 吞吐量
99%的PLE(Pause Loop Exit)来自spinlock。Debooster通过vruntime调整阻止乒乓抢占,锁持有者获得足够的CPU时间完成临界区。
在已经高密跑满的文件服务集群里,额外挖出14.4%的吞吐,不是优化,是在白捡一批机器的预算。
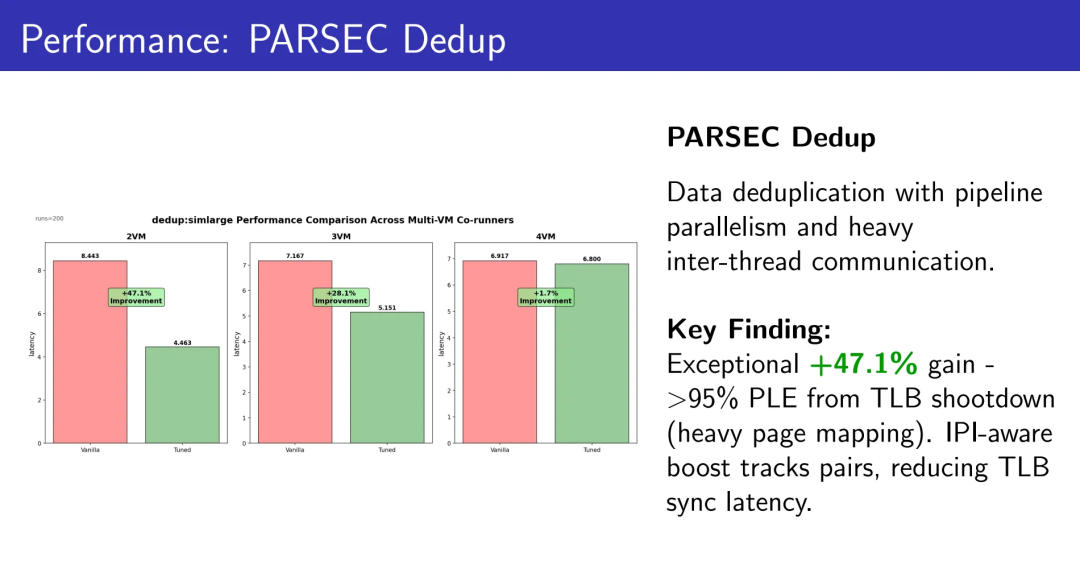
5.2 PARSEC Dedup:数据去重pipeline
具有大量线程间通信的流水线并行工作负载。
2 VMs:+47.1% 吞吐量
3 VMs:+28.1% 吞吐量
4 VMs:+1.7% 吞吐量
超过95%的PLE源于TLB shootdown(频繁的页映射操作)。IPI-aware boost精确追踪发送者→接收者配对,显著降低TLB同步延迟。这是IPI通信密集型工作负载的完美案例。
在这样的IPI-heavy场景下,47.1%不是一个“微调”能得到的数字,而是调度器完全换了一种与Guest协作的方式之后才可能出现的跃迁。
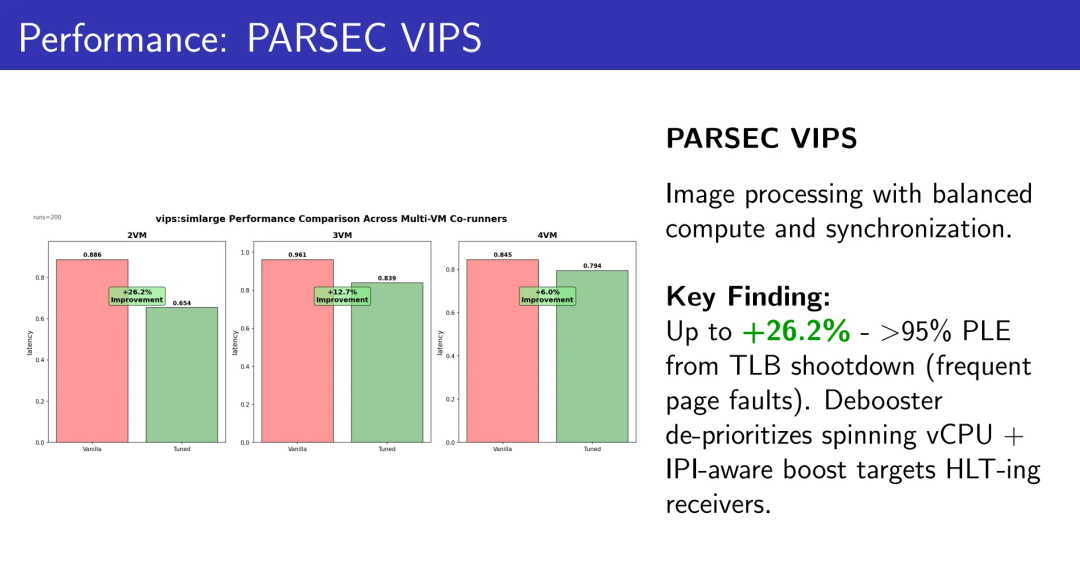
5.3 PARSEC VIPS:图像处理
计算和同步相对平衡的工作负载。
2 VMs:+26.2% 吞吐量
3 VMs:+12.7% 吞吐量
4 VMs:+6.0% 吞吐量
超过95%的PLE来自TLB shootdown(频繁的缺页)。Debooster降低自旋vCPU优先级 + IPI-aware boost定向提升处于HLT状态的接收者。双重机制的协同效应。
VIPS的曲线说明,这套机制不仅只会在“极端锁竞争”下吃香,而是在日常偏混合型负载里,同样能把高密环境下本该失去的那部分性能捞回来。
5.4 性能分析:为何在2-3 VM时收益最大?
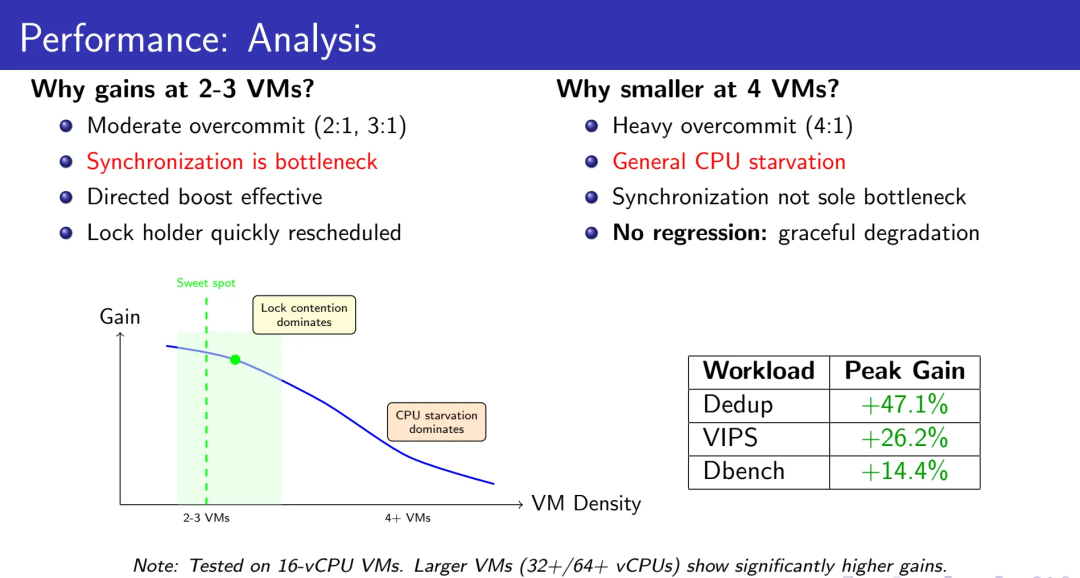
适度高密(2:1,3:1):
同步是主要瓶颈
Directed yield高效
锁持有者快速重新调度
Sweet spot:锁竞争主导性能
重度高密(4:1及以上):
普遍的CPU饥饿
同步不再是唯一瓶颈
没有回退:优雅降级
这个趋势符合预期。在16 vCPU的测试VM中已经看到这样的结果。在更大规模的VM(32、64 vCPU)上,我们观察到显著更高的收益——因为同步密集度随核心数增加而增长。
这条性能曲线揭示了一个更深层的系统原理:优化的收益边界,永远由“次优瓶颈”决定。在2:1场景下,锁竞争是主瓶颈,我们的方案直击要害,所以收益惊人;在4:1场景下,CPU饥饿成为新的主瓶颈,即使锁竞争完全消失,性能也上不去多少——这时你需要的不是更好的调度器,而是更多的物理核心。理解这个边界,才能避免在错误的战场上投入资源。47.1%的提升不是我们做了什么魔法,而是我们精准地识别出了“在哪个密度区间,调度器语义感知是第一性瓶颈”。
就绝对数值和收益来源而言,这组结果更接近“体系结构级优化”而非“局部微调”:我们没有改变任何单个锁的实现、没有调整Guest内核的任何参数、没有依赖新的硬件特性,却改变了整个高密虚拟化系统处理同步冲突的方式。这种跨越Guest-Host边界的全局视角,是传统单侧优化(要么改Guest,要么改硬件)所无法企及的。
06
实现细节:魔鬼在细节中
6.1 为何优于准虚拟化方案?
相比PV TLB shootdown等准虚拟化方法,我们的方案具有结构性优势:
Guest OS无需修改:无需重新编译或驱动支持
Guest OS无关:统一适用于各种操作系统
更广泛的适用性:捕获所有IPI模式(spinlock、RCU、smp_call_function等),而非仅限特定准虚拟化操作
部署简洁性:现有VM镜像立即受益,对生产环境至关重要
从工程投入产出比的角度看,把语义注入Host调度器,比在每一种Guest、每一个发行版里推广新的PV协议,要现实得多。真正撑起一片大规模高密云的,不是某一个花哨的硬件特性,而是一组在各种Guest、各种版本之上都稳定工作、且可渐进部署的基础设施。
从更长的时间尺度看,这种Host-side语义注入的模式,相比“每一种硬件特性+一套专用PV协议”的组合,更接近一种可被标准化、可在不同hypervisor/调度器之间迁移的通用框架。它不依赖特定的Guest协作、不依赖特定的硬件vendor,只依赖“虚拟化系统中确实存在语义信号”这一普遍事实。当Xen、Hyper-V、QEMU/KVM都面临同样的高密调度问题时,这套方法论是可以跨平台复用的——只需要在各自的调度器中找到对应的hook点。
在某些高密度、资源竞争激烈的部署场景中,APICv的性能优势可能受到调度和竞争模式的制约。在这种情况下,基于软件的IPI追踪作为一种补充优化路径,提供定向的调度提示,而无需依赖禁用APICv。实际选择应根据工作负载特征和平台配置进行评估和平衡。
这里的架构选择反映了一个被低估的事实:在云基础设施中,“零侵入性”不是一个可选的优点,而是能否大规模部署的前提条件。PV方案的问题不在于它不够优雅,而在于它要求你控制整个软件栈——从Guest内核到应用层驱动。而现实中,云厂商面对的是成千上万个客户镜像,从Windows Server 2012到各种Linux发行版,从自编译内核到商业闭源OS。如果你的优化方案需要每一个镜像都配合升级,那它在工程上就是不可行的。Host-side方案的价值,不仅在于它能工作,更在于它能在一个异构、失控、不断演化的生态系统中工作。
07
从技术到哲学:重新定义调度器的认知边界
这项工作的意义超越了性能数字本身。它触及了一个更根本的问题:调度器应该理解多少关于工作负载的语义?
传统调度器基于状态(runnable、running、blocked)做决策。它看到的是“what”——什么任务在等待CPU。
语义感知的调度器理解意图(intent)。它理解“why”——为什么这个vCPU在自旋?它在等谁?谁能解除它的阻塞?
这是从“反应式调度”到“预判式调度”的跃迁。而高密虚拟化,恰好是检验这种跃迁是否站得住脚的试金石。
Cgroup层级LCA的识别,让调度器理解了组织结构中的竞争层级。EEVDF字段的一致性更新,让调度器维持了公平性的数学不变式。IPI通信关系的追踪,让调度器洞察了处理器间协作的因果链。
我们没有改变调度器的核心算法,而是扩展了它的认知维度。这种“语义注入”的设计模式,可能为未来的系统软件优化指明方向。
但这里有个更深的洞察:语义感知不是越多越好。我们只追踪了IPI通信,没有追踪内存访问模式、没有追踪网络I/O依赖、没有追踪文件系统锁。为什么?因为每增加一个语义维度,就增加一分复杂性和开销。IPI是那个“ROI最高的切入点”——它的信号强度高(发送→接收→EOI是明确的三阶段协议)、追踪开销低(只在中断投递路径上加几行代码)、影响面广(覆盖spinlock、RCU、TLB shootdown等所有处理器间同步)。这种“只做关键20%的语义感知,获取80%的性能收益”的判断,才是系统优化中最稀缺的能力。完美主义者会想追踪一切;工程师知道要在边际收益归零之前停手。
如果说IPI语义是我们在高密KVM场景下选择的第一块踏脚石,那么相同的设计模式同样可以应用于其他类型的语义信号——例如NUMA亲和性的跨节点访问模式、分布式事务的两阶段提交路径、甚至是微服务架构中的RPC依赖拓扑。关键不在于我们追踪了哪一种语义,而在于我们证明了:在不打乱调度器数学基础的前提下,语义感知的调度完全可以成为一种工业级、可部署的能力。当下一代云基础设施开始系统性地暴露更多语义信号时,调度器就能做出更接近全局最优的决策。这不是科幻,而是一条已经被验证可行的演进路径。
08
总结
在云原生时代,虚拟化系统的性能边界正在从硬件能力转向软件智能。这项工作通过两个正交且互补的机制——调度器vCPU Debooster和IPI-Aware Directed Yield——为KVM调度器注入了语义感知能力。
Debooster通过层级感知的vruntime惩罚,在Cgroup嵌套结构中提供持续的调度偏好,解决了buddy机制的一次性限制。IPI-Aware机制通过轻量级的通信追踪,精确识别boost目标,将盲目启发式转化为根因驱动的决策。
在16核Intel Xeon上的测试显示,Dedup工作负载获得47.1%的性能提升,VIPS提升26.2%,Dbench提升14.4%。这些收益源于三个协同效应:锁持有者获得足够CPU时间完成临界区、IPI接收者被及时调度以响应同步请求、更好的缓存利用率减少上下文切换开销。
更重要的是,这项工作展示了一种新的系统优化范式:通过理解工作负载的语义,而非仅仅优化算法参数,我们可以突破传统性能瓶颈。这种从"what"到"why"的认知升级,可能是下一代系统软件的共同特征。
如果你的集群已经在高密模式下长期运行,却仍然依赖一个对IPI和cgroup层级一无所知的yield_to(),那么你其实是在用过去十年的调度器观念,消耗未来几年的资源预算。这不是危言耸听——当你的竞争对手开始部署语义感知的调度器,在同样的硬件上榨出20%-40%的额外容量时,成本差异会直接体现在财报上。而在云计算这个边际成本敏感的行业,谁能更早看到并抓住这类体系性优化机会,谁就掌握了下一轮成本竞争的主动权。
代码已提交至LKML:https://lore.kernel.org/lkml/20251110033232.12538-1-kernellwp@gmail.com/
当调度器学会读懂语义,性能的天花板就不再是硬件,而是我们对系统行为理解的深度。而在这条理解的道路上,每一次认知升级,都意味着一次性能跃迁的机会。从状态到语义、从反应到预判、从局部优化到全局协同——这不仅是虚拟化调度的演进方向,也可能是整个系统软件栈的共同命运。问题不是你能不能做到,而是你能不能比别人更早看到。


-End-
原创作者|李万鹏

你对本文内容有哪些看法?同意、反对、困惑的地方是?欢迎留言,我们将邀请作者针对性回复你的评论,同时选一条优质评论送出腾讯云定制文件袋套装1个(见下图)。12月4日中午12点开奖。
























 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









