



大家好,我是架构师技术同盟的小盟。
01 引言
当 Transformer 架构像一把钥匙打开深度学习的新大门,大语言模型(LLM)已从实验室走向产业落地。但对多数人而言,从基础概念到架构选型的学习之路,常像在参数森林里迷路 —— 哪些是必须掌握的核心原理?不同模型架构的取舍背后藏着怎样的逻辑?
本LLM系列文章选自腾讯云架构师技术同盟成员羚羊工业互联网股份有限公司 高级系统架构师 宋国磊。宋老师为开发者搭建了一条由浅入深的学习路径。
先看《基础概念篇》,把神经网络的学习过程、自注意力机制的工作原理拆解得很清楚,也详细说明了预训练和微调之间的区别,能帮你搞懂模型从通用能力到专项能力的转变逻辑。
再读第二篇《核心技术之架构模式》,文中对比了稠密模型和 MoE 架构,分析了前者全参数激活与后者专家分工的不同特点,让你明白为何有的模型注重参数规模,有的则通过稀疏计算来提高效率。
从基础概念到架构技术,这两篇文章循序渐进,能让开发者扎实掌握 LLM 的核心知识,值得一读。
02 正文
《大模型发展历程:技术演进与趋势洞察》
羚羊工业互联网股份有限公司 高级系统架构师 宋国磊
摘要:本文系统梳理了 2017 年至 2025 年间,大语言模型(LLM)领域的关键进展、技术演进和代表模型。从 Transformer 架构的革命性突破,到 GPT-3 的规模化成功,再到多模态模型的兴起,大模型技术正在重塑人工智能产业格局。
第一阶段(2017-2019):Transformer 革命与早期探索
技术演进总结
2017年,Google发表的《Attention Is All You Need》论文标志着深度学习进入全新纪元。Transformer架构通过自注意力机制(Self-Attention)彻底解决了传统RNN和CNN在处理长序列时的局限性,为后续大模型的发展奠定了根本性基础。
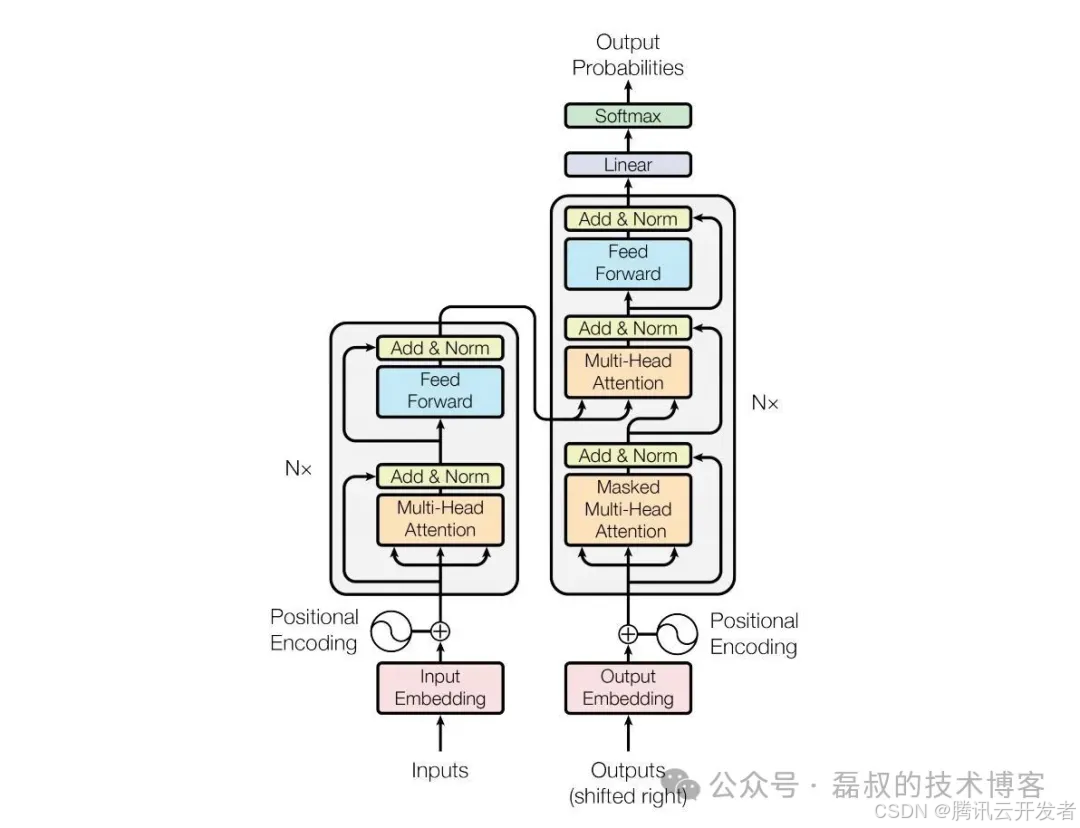
Transformer架构图
该阶段的核心技术突破包括:
- • 自注意力机制:实现了序列中任意位置间的直接建模
- • 并行计算:相比RNN的序列计算,大幅提升了训练效率
- • 位置编码:解决了Transformer缺乏序列位置信息的问题
- • 多头注意力:增强了模型对不同语义空间的理解能力
代表性模型
| 模型名称 | 发布机构 | 发布时间 | 参数量 | 架构类型 | 亮点特征 |
|---|---|---|---|---|---|
| GPT-1 | OpenAI | 2018年6月 | 1.17亿 | Transformer 解码器 | 首次验证了无监督预训练 + 下游任务微调的范式有效性 |
| BERT | | 2018年10月 | Base: 1.1亿;Large: 3.4亿 | Transformer 编码器 | 双向语言模型,通过 Masked Language Model 实现深度双向表示 |
| GPT-2 | OpenAI | 2019年2月 | 15亿(最大版本) | 扩展的 Transformer 解码器 | 展示了模型规模扩大带来的性能提升,初步体现了涌现能力 |
| ERNIE 1.0 | 百度 | 2019年4月 | 1.1亿(Base) | 基于 BERT 的改进版本 | 引入知识增强预训练,在中文理解任务上表现优异 |
场景应用案例
这一阶段的应用主要集中在传统 NLP 任务的性能提升:
- • 搜索引擎优化:Google将BERT应用于搜索排序,显著提升了查询理解能力
- • 机器翻译:Transformer架构在WMT翻译任务上取得突破性进展
- • 文本分类:各类情感分析、文档分类任务精度大幅提升
第二阶段(2020-2022):规模化突破
技术演进总结
这一阶段的核心特征是模型参数量的爆炸式增长和训练数据的大规模扩展。GPT-3 的发布证明了规模化是通向人工通用智能的可行路径,同时中国厂商开始在大模型领域密集布局。
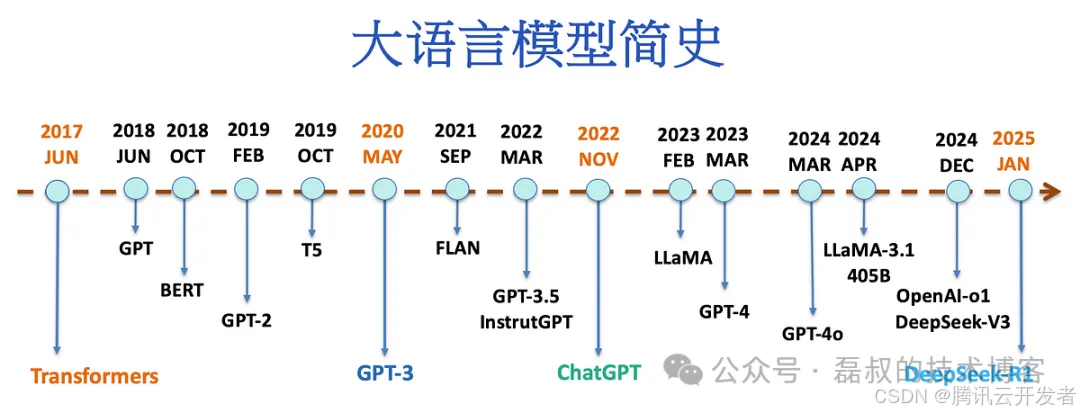
大模型发展时间线
关键技术突破包括:
- • 规模化训练:模型参数从十亿级跃升至千亿级
- • In-Context Learning:GPT-3 展示了无需微调即可完成新任务的能力
- • Few-Shot Learning:通过少量示例实现任务泛化
- • 知识增强:中国模型普遍注重将结构化知识融入预训练过程
代表性模型
| 模型名称 | 发布机构 | 发布时间 | 参数量 | 架构类型 | 亮点特征 |
|---|---|---|---|---|---|
| GPT-3 | OpenAI | 2020年5月 | 1750亿 | 扩展的 Transformer 解码器 | 展示了大规模模型的涌现能力,支持多样化的 zero-shot 和 few-shot 任务 |
| T5 | | 2020年10月 | 110亿(最大版本) | 编码器-解码器结构 | 将所有 NLP 任务统一为文本到文本的生成任务 |
| PaLM | | 2022年4月 | 5400亿 | 仅解码器 Transformer | 在推理、代码生成等复杂任务上表现突出 |
| ERNIE 3.0 Titan | 百度 | 2021年12月 | 2600亿 | 统一的文本、图像、知识理解框架 | 全球首个知识增强千亿大模型 |
| GLM-130B | 清华大学 & 智谱 AI | 2022年8月 | 1300亿 | General Language Model 架构 | 中英双语预训练,在理解和生成任务上均衡发展 |
| 通义千问 | 阿里云 | 2023年4月 | 未公开 | Transformer 架构 | 针对中文场景深度优化,集成阿里生态应用 |
场景应用案例
应用场景开始从传统NLP向更广泛的智能化场景扩展:
...
*本文摘选自腾讯云架构师技术同盟交流圈
点击下方可查看全文


















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









