



IDEA研究院 投稿
量子位 | 公众号 QbitAI
AI能看懂细节了!
IDEA研究院发布基于多模态大语言模型的目标检测模型DINO-XSeek。
结合视觉与语言理解,只需通过自然语言描述,DINO-XSeek 就能精准定位复杂场景中的目标。
比如这张图。
消防员手持喷水枪,站在执行任务的消防车云梯上。

结果它能精准识别出来这个正在工作的消防员。

在人来人往的米兰大教堂前,找到个有金色头发的人~
结果也精准识别出来了。

基于 IDEA研究院 DINO-X 统一视觉模型,DINO-XSeek 在精准感知能力的基础上,融合了多模态大语言模型的推理与理解能力。
它的核心突破在于,不仅能识别名词层级的目标(如“女孩”),还能联合解析形容词(如“红色上衣”)和介词(如“站在旁边”),真正让 AI 看懂细节。
无论是“穿红色上衣的女孩”还是“站在白衣男生旁边的她”,DINO-XSeek 都能准确检测。
AI能看懂细节了:目标检测+多模态语言理解
传统目标检测模型虽然在目标感知上表现优异,但缺乏对复杂语言的理解能力。大语言模型在文本理解方面突出,却在精确目标定位上存在短板。
为了解决这一矛盾,DINO-XSeek 参考ChatRex的模型架构,采用了一种检索式框架。
即先使用开集目标检测模型 DINO-X 检测图像中的所有物体,并生成候选目标的边界框。
然后,大语言模型根据指代表达,从检测出的目标集合中检索最相关的对象,而非直接预测坐标。
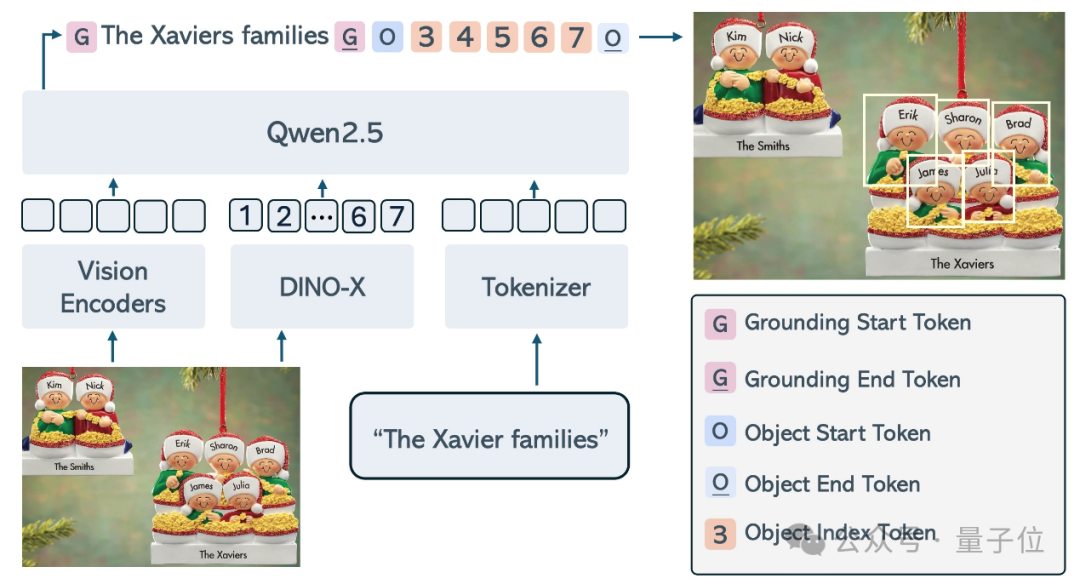
△DINO-XSeek 模型概览图。其主要有三部分组成,包括提取视觉token的视觉编码器、提取物体token的目标检测模型,以及提取文本token的tokenizer。三种token一起送入LLM中,进行物体索引预测。
现有主流方法,往往仅针对单实例进行训练和推理,难以应对现实世界中一条指代描述对应多个目标的情况。
这一设计避免了传统MLLM在检测任务上的泛化难题,使得 DINO-XSeek 能精准处理多实例指代任务。
通过自然语言描述,DINO-XSeek 可以推理出待检测目标的属性(如颜色、大小、姿势、穿着等)、方位(如朝向、距离、深度等)或者(物品之间或与环境的)交互关系,从而实现精准的目标定位。DINO-XSeek 实现了指代表达理解(Referring Expression Comprehension, REC)。REC 是计算机视觉与自然语言理解交叉领域的核心任务,旨在通过自然语言描述精准定位图像中的目标对象。DINO-XSeek 通过多模态融合和高级语义推理,为 REC 任务提供了更强大的解决方案。
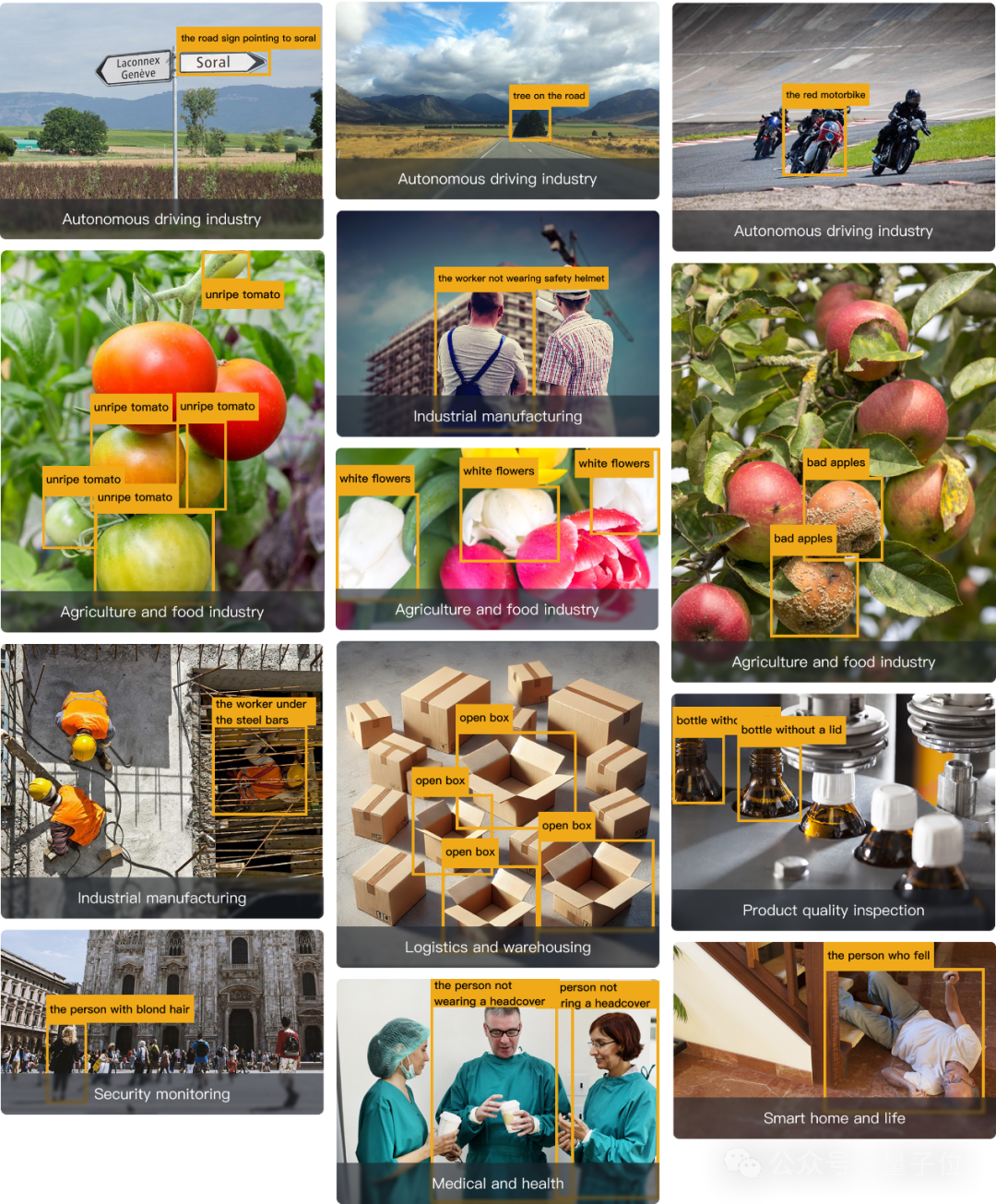
△DINO-XSeek 识别结果。在工业制造与质检、安防等行业应用潜力广泛。
与主流目标检测模型以物体为核心不同,DINO-XSeek 以“理解物体属性及关系”为核心,不再孤立地关注物体本身,而是专注于物体相关的处理逻辑。
具体而言,以人类学习为例,以物体为核心的模型更像是幼儿启蒙阶段对物体的认知,如幼儿会辨认道路的“车”。随着见识(即数据)增长,部分高阶的认知能够进一步识别物体基础的属性以及关系,如“红色的车”、“前面的车”、“大的车”、“货车”,但仍旧难以理解“正在执行任务的消防车”之类的更复杂的描述。
相比之下,DINO-XSeek 则像是一位学生,已经建立起知识储备和对事务逻辑的理解,能够对“正在执行任务的消防车的云梯上拿着喷水枪的消防员”这样复杂的描述进行正确的辨认,而不是简单地标记“消防车”或“消防员”,真正实现了近似人类对复杂场景的理解能力。
以“理解物体属性及关系”为切入点意味着,DINO-XSeek 将能够根据用户输入的业务处理逻辑来完成相关的目标检测任务,降低在实际生产应用中,用户基于视觉模型进行二次处理的后置开发成本。
举个例子,在当前的工厂流水线中,企业在使用视觉模型检测出零部件存在缺陷以后,需要进一步对缺陷进行分类,如划痕、裂纹、尺寸偏差等,并统计各种缺陷的出现频率和分布情况,为生产工艺的改进提供数据支持。
而DINO-XSeek为生产工艺智能化提供了更多想象。比如通过使用 DINO-XSeek 精准区分出“划痕过多的零部件”、“带裂纹的零部件”或者“尺寸不合格的零部件”,企业便可以实现零部件缺陷的检测和分类工作全自动化,无需再像之前一样投入巨大的资源对零部件缺陷进行进一步分类和统计。
安全合规检测:识别「未佩戴护目镜的操作员」「进入危险区域的工人」,触发语音警告。

△DINO-XSeek识别结果。提示词:The worker not wearing a safety helmet(没有戴安全帽的工人)

△DINO-XSeek识别结果。提示词:The worker under the steel bars(在钢筋下面的工人)
质量检测:针对流水线上生产的零部件或最终成品,自动识别并分类各种缺陷(如划痕、裂纹、尺寸偏差),为工艺改进提供更精准的数据参考。

△DINO-XSeek识别结果。提示词:abnormal light(异常光线)
智能家居与生活
危险行为识别:在家庭场景中自动识别老人意外摔倒等高风险状况,及时通知看护人员或发出紧急警告。

△提示词:The person who fell(摔倒的人)
农业与食品
农作物检测:根据发育程度对农作物进行分类,或识别腐坏、病虫害侵染的果实,有效提升种植和收获效率。

△提示词:Bad apple(坏苹果)
自动驾驶
道路场景识别:对车载摄像头拍摄的道路图像进行标注,识别出道路、交通标志、车道线、行人、其他车辆等目标,帮助自动驾驶汽车理解周围环境,做出正确的行驶决策。

△DINO-XSeek识别结果。提示词:The road sign pointing to Soral(指向Soral的路标)
障碍物检测:及时标注出图像中的障碍物,如路边的障碍物、突然出现的动物等,使自动驾驶系统能够提前做出制动或避让等操作,保障行车安全。

△DINO-XSeek识别结果。提示词:Tree on the road(路上的树)
关于新模型就介绍到这里,欢迎大家体验~
论文链接:
官网: https://deepdataspace.com/
Blog: https://deepdataspace.com/blog/dino-xseek



















 33
33

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









