



Pine 发自 凹非寺
量子位 | 公众号 QbitAI
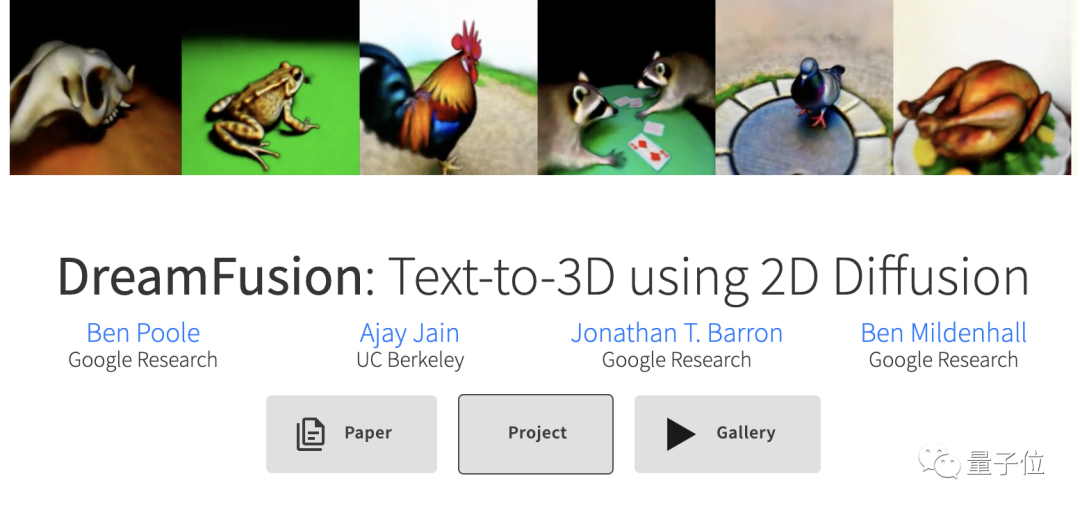
用2D数据训练出来的模型,也能生成3D图像了。
输入简单的文本提示,就能生成3D模型,这个“AI画师”的技术如何?
直接看效果。

它生成的3D模型还具有密度、颜色。

并且能够在不同的光照条件进行渲染。

不仅如此,它甚至可以把生成的多个3D模型融合到一个场景里。

更重要的是,生成的3D模型还可以导出到网格中,用建模软件进一步加工。

这简直就是高阶版的NeRF,而这个AI画师呢,名叫DreamFusion,是Google Research的一个最新成果。
DreamFusion名字是不是听起来有点耳熟?
没错,DreamFields!前不久,还有个中国小哥基于这个模型开源了一个AI作画程序。
而这次的DreamFusion正是在DreamFields的基础上进化而来的。
那从DreamFields到DreamFusion,都有哪些变化,让DreamFusion有如此巨大的飞跃?
扩散模型是关键
一句话来讲,DreamFusion与DreamFields之间最大的不同就是计算损失的方法不同。
在最新的DreamFusion中,它用了一个新的损失计算方法来代替CLIP:通过文本到图像的Imagen扩散模型来计算损失。
扩散模型大家今年应该都很熟悉了吧,DreamFusion由数十亿图像-文本对的扩散模型驱动,相当于一个由扩散模型优化之后的NeRF,想不厉害都难。
不过要把扩散模型直接用来进行3D合成需要大规模的标记3D数据集和有效的3D数据去噪架构,但目前这两个都还没有,只能另谋出路。
因此在这项工作中,研究人员巧妙地避开这些限制,使用一个预先训练的二维文本到图像扩散模型来执行文本到三维合成。
具体来说,就是用Imagen扩散模型来计算生成3D图像过程中的损失,对3D模型进行优化,那损失是如何计算呢?
这其中有很关键的一环,研究人员引入一个新的图像采样方法:评分蒸馏采样 (SDS),它在参数空间而不是像素空间中进行采样。
因为参数的限制,这种方法能够很好的控制生成图像的质量走向(下图右)。

而这里,就是用评分蒸馏采样来表示生成过程中的损失,通过不断优化最小化这种损失,从而输出质量良好的3D模型。
值得一提的是,DreamFusion在生成图像的过程中,里面的参数会经过优化,成为扩散模型的一个训练样本,经过扩散模型训练之后的参数具备多尺度特性,更利于后续的图像生成。
除此之外,扩散模型带来的还有很重要的一点是:不需要反向传播,这是因为扩散模型能够直接预测更新的方向。
网友讨论
这波研究成果属实是惊呆网友了,前脚Meta刚发布text-video,后脚谷歌这边就发布了text-3D的模型。
(还是用2D扩散模型输出3D图像)
甚至有网友发问:
下一版本的高分辨率3D成果什么时候会出来?两年吗?
论文的一作直接在下方调侃地评论道:
两周?
当然这个AI技术成果也免不了激起那个老生常谈的话题——会不会取代人类。

不过大多数人还是抱着很乐观的心态:
作为一个3D建模师/设计师,未来(AI)用于模型设计辅助的潜力也是难以置信的。

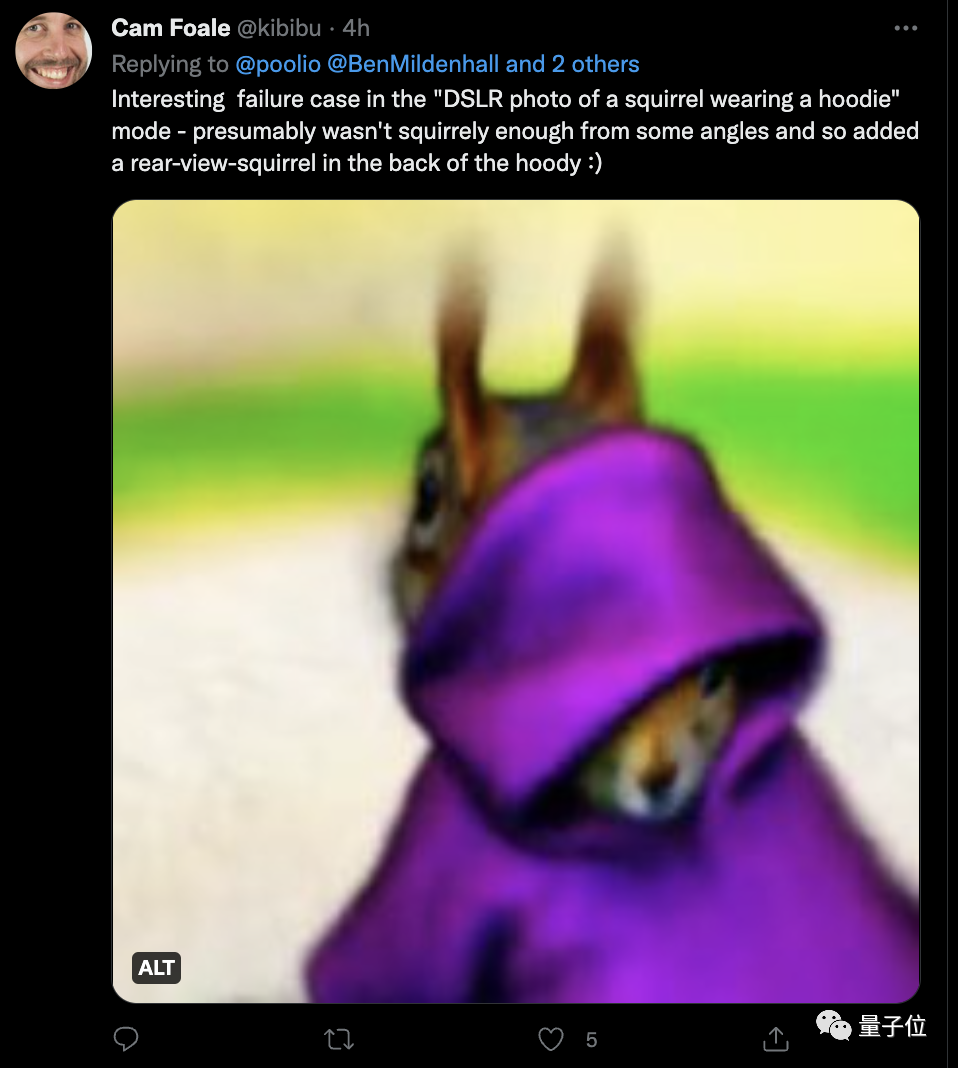
(小彩蛋)有网友挖出了DreamFusion的一些有趣的失败案例:
比如说生成的这只松鼠,在它的帽衫后面又多出了一只眼睛(也怪吓人的)。
团队介绍
研究团队中有三位均来自Google Research,分别为论文的一作Ben Poole,Jon Barron和Ben Mildenhall,还有一位加州大学伯克利分校的博士生。
Google Research是Google公司内部进行各种最先进技术研究的部门,他们也有自己的开源项目,在GitHub公开。
他们的口号是:我们的团队渴望做出影响每个人的发现,我们的方法的核心是分享我们的研究和工具,以推动该领域的进展。
一作Ben Poole是斯坦福大学神经学博士,也是谷歌大脑的研究员,目前他的研究重点是使用生成模型改进无监督和半监督学习的算法。

参考链接:
[1]https://dreamfusion3d.github.io/index.html
[2]https://twitter.com/poolio/status/1575618598805983234


















 14
14

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









