









yolov8工件识别数据集
带训练好的权重
可训练螺栓、螺母、轴承、齿轮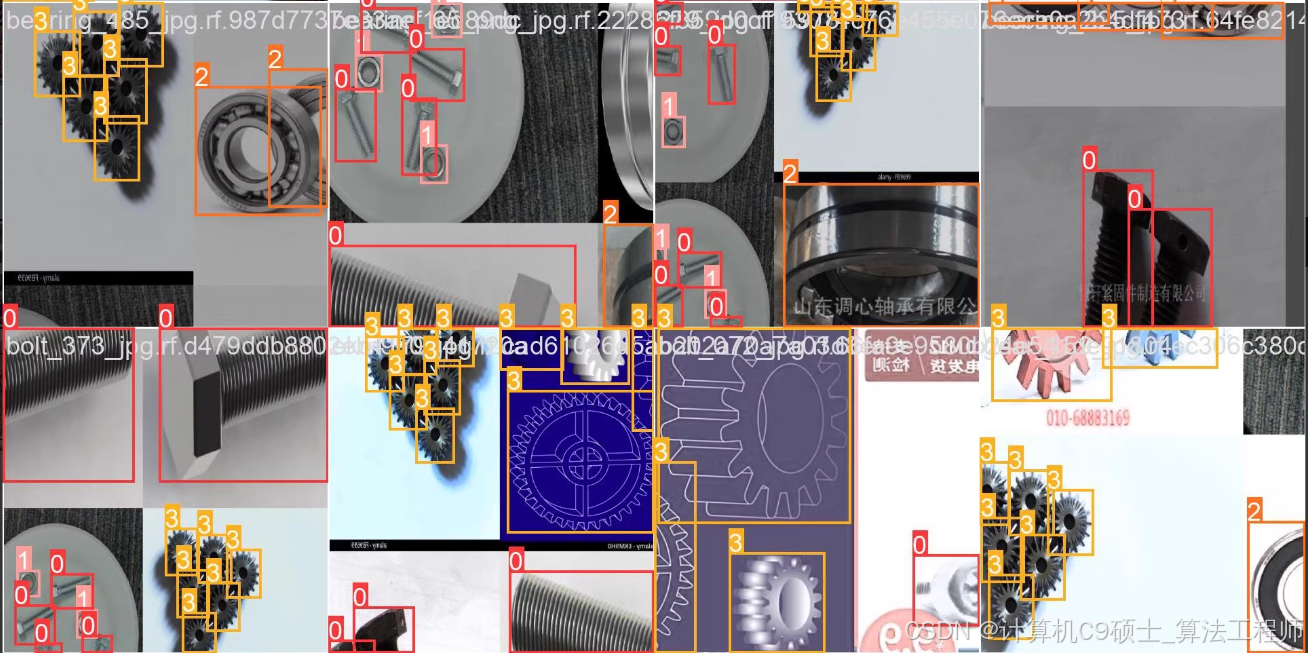

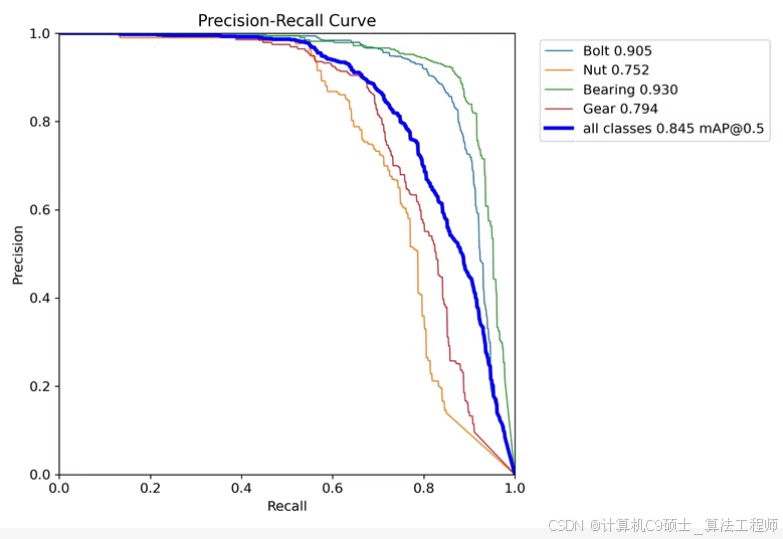
一个物体识别任务的精度召回率曲线(Precision-Recall Curve)。从图表中可以看出,对于四个不同的类别的识别——螺栓(Bolt)、螺母(Nut)、轴承(Bearing)和齿轮(Gear)——它们在不同召回率水平下的精确度变化情况。此外,还显示了所有类别的平均精确度(mAP@0.5),即当置信阈值设为0.5时的平均精确度。
具体来说:
- 螺栓(Bolt)的mAP是0.905,
- 螺母(Nut)的mAP是0.752,
- 轴承(Bearing)的mAP是0.930,
- 齿轮(Gear)的mAP是0.794,
- 所有类别的综合mAP是0.845。
首先,你需要安装必要的Python包,例如PyTorch和相关的YOLOv8库。假设你已经下载了YOLOv8的源码,并且你的环境已经准备好运行Python脚本。
以下是一个简单的训练脚本示例,它展示了如何使用YOLOv8来训练一个对象检测模型:
import torch
from ultralytics import YOLO
# 加载预训练的YOLOv8模型
model = YOLO("path/to/yolov8_weights.pt") # 如果没有预训练权重,则可以使用"yolov8n"
# 设置数据集路径
data_path = "path/to/dataset.yaml"
# 开始训练
results = model.train(
data=data_path,
epochs=100, # 训练周期数
batch=16, # 每批样本数量
imgsz=640, # 输入图像尺寸
name="yolov8_custom", # 输出模型的名字
patience=10, # 提早停止的耐心参数
workers=4 # 工作线程数
)
# 保存训练完成的模型
model.export(format="onnx")
在这个例子中,我们首先导入了所需的模块,然后加载了预训练的YOLOv8模型。接着,我们指定了数据集的位置以及一些训练参数,比如训练周期数、每批次的样本量等。最后,我们调用train()方法开始训练过程,并在完成后导出ONNX格式的模型以便于部署。
请注意,这只是一个基础的示例,实际应用中可能还需要根据具体的项目要求进行更多的定制和优化。
好的,下面是一个详细的YOLOv8训练代码示例,包括数据集准备、模型加载、训练配置和训练过程。我们将使用YOLOv8的官方库ultralytics来完成这些步骤。
1. 安装依赖
首先,确保你已经安装了必要的库。如果没有安装,可以使用以下命令进行安装:
pip install ultralytics
2. 数据集准备
假设你的数据集目录结构如下:
dataset/
├── images/
│ ├── train/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── val/
│ ├── image1.jpg
│ ├── image2.jpg
│ └── ...
└── labels/
├── train/
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
└── val/
├── image1.txt
├── image2.txt
└── ...
3. 数据集配置文件
创建一个data.yaml文件,配置数据集路径和类别信息。
# data.yaml
train: dataset/images/train
val: dataset/images/val
nc: 4 # 类别数量
names: ['Bolt', 'Nut', 'Bearing', 'Gear'] # 类别名称
4. 训练脚本
创建一个训练脚本train_yolov8.py,包含数据集加载、模型加载、训练配置和训练过程。
# train_yolov8.py
import torch
from ultralytics import YOLO
def train_model(data_yaml_path, model_config, epochs, batch_size, img_size, device):
# 加载预训练的YOLOv8模型
model = YOLO(model_config)
# 设置数据集路径
data_path = data_yaml_path
# 开始训练
results = model.train(
data=data_path,
epochs=epochs, # 训练周期数
batch=batch_size, # 每批样本数量
imgsz=img_size, # 输入图像尺寸
name="yolov8_custom", # 输出模型的名字
patience=10, # 提早停止的耐心参数
workers=4, # 工作线程数
device=device # 设备(CPU或GPU)
)
# 保存训练完成的模型
model.export(format="onnx")
if __name__ == "__main__":
data_yaml_path = 'data.yaml'
model_config = 'yolov8n.pt' # 你可以选择其他预训练模型,如'yolov8s.pt', 'yolov8m.pt'等
epochs = 100
batch_size = 16
img_size = 640
device = '0' # 使用GPU,如果需要使用CPU,可以改为'cpu'
train_model(data_yaml_path, model_config, epochs, batch_size, img_size, device)
5. 详细解释
数据集配置文件 (data.yaml)
train: 训练集图像路径。val: 验证集图像路径。nc: 类别数量。names: 类别名称列表。
训练脚本 (train_yolov8.py)
train_model: 主训练函数。data_yaml_path: 数据集配置文件路径。model_config: 预训练模型路径。epochs: 训练周期数。batch_size: 每批样本数量。img_size: 输入图像尺寸。device: 训练设备(CPU或GPU)。
model = YOLO(model_config): 加载预训练的YOLOv8模型。model.train: 开始训练过程,传入训练配置参数。model.export: 导出训练完成的模型为ONNX格式。
6. 运行训练脚本
-
数据集准备:
确保你的数据集路径和类别信息正确无误。 -
训练模型:
python train_yolov8.py
7. 注意事项
- 数据集路径:确保数据集路径正确,特别是
data.yaml文件中的路径。 - 模型配置:确保模型配置文件路径正确。
- 图像大小:
img_size可以根据实际需求调整,通常使用640或1280。 - 设备:确保设备(CPU或GPU)可用。
- 超参数调整:根据实际情况调整训练参数,如学习率、批量大小等,以获得最佳训练效果。
8. 总结
通过以上步骤,你可以使用YOLOv8训练一个针对螺栓、螺母、轴承和齿轮的物体识别模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









