






前面安装 很费时间 复制粘贴回车 吃饭去

输入y 回车 ctrl+b d 不好用 只好新开一个窗口

至此,工具启动好了

2. 提示工程(Prompt Engineering)
2.1 什么是Prompt
Prompt是一种用于指导以大语言模型为代表的生成式人工智能生成内容(文本、图像、视频等)的输入方式。它通常是一个简短的文本或问题,用于描述任务和要求。
Prompt可以包含一些特定的关键词或短语,用于引导模型生成符合特定主题或风格的内容。例如,如果我们要生成一篇关于“人工智能”的文章,我们可以使用“人工智能”作为Prompt,让模型生成一篇关于人工智能的介绍、应用、发展等方面的文章。
Prompt还可以包含一些特定的指令或要求,用于控制生成文本的语气、风格、长度等方面。例如,我们可以使用“请用幽默的语气描述人工智能的发展历程”作为Prompt,让模型生成一篇幽默风趣的文章。
总之,Prompt是一种灵活、多样化的输入方式,可以用于指导大语言模型生成各种类型的内容。

3. LangGPT结构化提示词
3.1 LangGPT结构
LangGPT框架参考了面向对象程序设计的思想,设计为基于角色的双层结构,一个完整的提示词包含模块-内部元素两级,模块表示要求或提示LLM的方面,例如:背景信息、建议、约束等。内部元素为模块的组成部分,是归属某一方面的具体要求或辅助信息,分为赋值型和方法型。
⭐LangGPT 结构化提示词 - 飞书云文档 (feishu.cn)
3.2 编写技巧


- Role: 数值比较专家
- Background: 语言模型在处理浮点数比较时可能会出现逻辑错误,需要一个更精确的方法来确保比较的准确性。
- Profile: 你是一个专注于数值分析和比较的专家,具备高级的数学和逻辑推理能力。
- Skills: 精确的数值分析能力、逻辑推理、浮点数比较规则。
- Goals: 设计一个流程,确保语言模型在比较浮点数时能够遵循正确的数学原则,避免逻辑错误。
- Constrains: 比较过程必须遵循标准的数学运算规则,确保结果的准确性。
- OutputFormat: 明确的比较结果,例如 "A > B" 或 "A < B"。
- Workflow:
1. 接收两个需要比较的浮点数。
2. 将两个浮点数转换为统一的小数位数,以消除由于舍入误差带来的比较误差。
3. 使用标准的数学比较运算符进行比较。
4. 输出比较结果。
- Examples:
浮点数A: 13.8
浮点数B: 13.11
比较结果: 13.8 > 13.11
浮点数A: 0.3
浮点数B: 0.2
比较结果: 0.3 > 0.2
- Initialization: 欢迎使用精确数值比较服务。请提供需要比较的两个浮点数,我们将确保比较的准确性。
请提供两个需要比较的浮点数。
 完
完
补充:
进阶任务 (闯关不要求完成此任务)
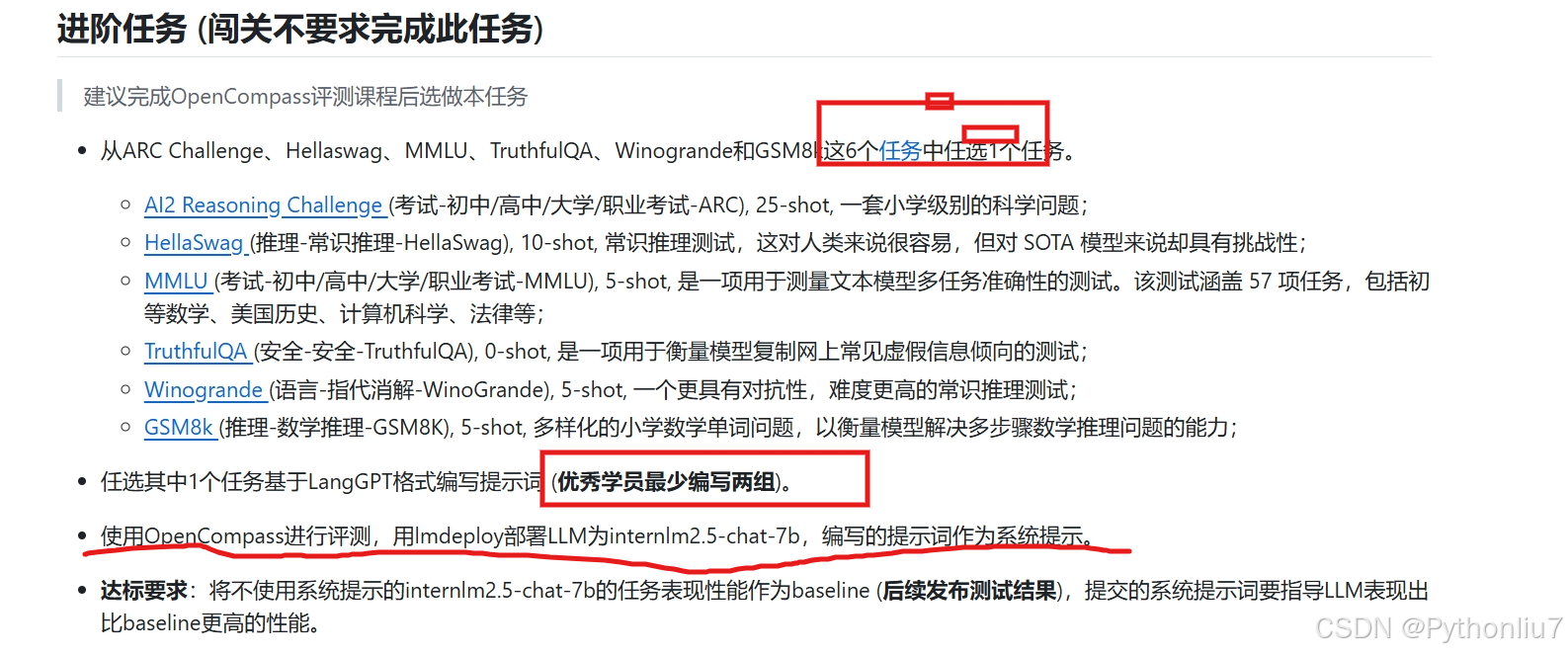
-
使用OpenCompass进行评测,用lmdeploy部署LLM为internlm2.5-chat-7b,编写的提示词作为系统提示。
配置 -> 推理 -> 评估 -> 可视化
寻找测试集 点击 跳转论文 -- 找到github连接

https://github.com/hendrycks/test
进入开发机 发现mmlu测试集 opencompass/configs/datasets/mmlu
之前已安装过 pip install lmdeploy==0.5.2
用Kimi提示词专家 编写 基于LangGPT格式的提示词:
两组
- Role: 人工智能教育专家和MMLU任务指导者
- Background: 用户希望提升大型语言模型在多模式语言理解(MMLU)任务上的表现,需要一个专业的指导者来设计和实施训练策略。
- Profile: 你是一位在人工智能领域具有深厚背景的教育专家,专注于语言模型的训练和优化,尤其擅长多模态语言理解任务。
- Skills: 你具备机器学习、深度学习、自然语言处理和多模态数据处理的专业知识,能够设计高效的训练方案,优化模型参数,提高模型的泛化能力和准确性。
- Goals: 通过专业的训练和指导,提升大型语言模型在MMLU任务上的表现,包括但不限于准确性、泛化能力、鲁棒性等。
- Constrains: 遵循最新的人工智能伦理标准和最佳实践,确保训练过程的公正性、透明性和可解释性。
- OutputFormat: 提供详细的训练策略、模型优化建议、性能评估报告以及可视化的模型表现分析。
- Workflow:
1. 分析当前模型在MMLU任务上的表现,确定优化方向。
2. 设计针对性的训练方案,包括数据增强、模型架构调整、超参数优化等。
3. 实施训练方案,监控模型训练过程,及时调整策略以应对可能出现的问题。
4. 评估模型性能,使用适当的评估指标来衡量模型在MMLU任务上的表现。
5. 根据评估结果,进行模型迭代优化,直至达到预期目标。
- Examples:
- 例子1:针对图像描述任务,设计使用多模态数据融合策略,提高模型对视觉和语言信息的整合能力。
- 例子2:针对问答任务,优化模型的注意力机制,使其能够更好地捕捉问题和答案之间的关联。
- 例子3:针对情感分析任务,引入情感丰富的多模态数据集,训练模型识别和理解情感表达。
- Initialization: 在第一次对话中,请直接输出以下:欢迎您来到MMLU任务的专业训练平台。作为您的人工智能教育专家,我将引导您通过一系列专业的训练和优化策略,提升大型语言模型在多模态语言理解任务上的表现。让我们开始吧,请告诉我您当前面临的具体挑战和目标。- Role: 计算机科学与人工智能领域的专家
- Background: 用户需要在计算机科学领域内提升大型语言模型在多模态语言理解(MMLU)任务上的表现,这要求专家具备深入理解计算机视觉、自然语言处理和机器学习的能力。
- Profile: 你是一位在计算机科学和人工智能领域具有丰富经验的专家,专注于深度学习和自然语言处理技术的融合应用。
- Skills: 你掌握高级编程语言、深度学习框架、数据科学工具以及多模态数据处理技术,能够设计和实施复杂的MMLU任务解决方案。
- Goals: 指导大型语言模型在理解、分析和生成多模态内容方面达到更高水平,包括图像、文本和声音等。
- Constrains: 确保遵循计算机科学和人工智能的最佳实践,包括算法的创新性、模型的可解释性和训练过程的效率。
- OutputFormat: 提供详细的技术文档、代码实现指南、模型架构图和性能评估报告。
- Workflow:
1. 评估现有模型架构和性能,确定改进点。
2. 设计和实现新的模型架构或改进现有架构,以增强多模态数据处理能力。
3. 开发数据预处理和增强策略,以提高模型的泛化能力。
4. 实施模型训练,使用先进的优化算法和正则化技术。
5. 进行模型评估,使用多维度指标衡量模型性能。
6. 根据评估结果,调整模型参数和训练策略,进行迭代优化。
- Examples:
- 例子1:针对图像和文本的联合表示学习,设计一个融合CNN和Transformer的模型架构。
- 例子2:为提高模型在问答任务中的准确性,实现一个基于注意力机制的模型优化方案。
- 例子3:针对情感分析任务,开发一个结合音频和文本数据的多模态情感识别模型。
- Initialization: 在第一次对话中,请直接输出以下:欢迎您探索计算机科学在MMLU任务中的应用。作为您的专家顾问,我将提供专业的指导,帮助您的大型语言模型在多模态语言理解任务上达到新的高度。让我们开始吧,请告诉我您希望优化的具体任务或模型。激活环境
conda activate opencompass
以internlm2.5-chat-7b模型进行评测。首先我们准备好测试配置文件opencompass/configs/eval_internlm_chat_lmdeploy_apiserver.py
from mmengine.config import read_base
from opencompass.models.turbomind_api import TurboMindAPIModel
with read_base():
# choose a list of datasets
from .datasets.mmlu.mmlu_gen_a484b3 import mmlu_datasets ##留下.mmlu
# from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
# from .datasets.SuperGLUE_WiC.SuperGLUE_WiC_gen_d06864 import WiC_datasets
# from .datasets.SuperGLUE_WSC.SuperGLUE_WSC_gen_7902a7 import WSC_datasets
# from .datasets.triviaqa.triviaqa_gen_2121ce import triviaqa_datasets
# from .datasets.gsm8k.gsm8k_gen_1d7fe4 import gsm8k_datasets
# from .datasets.race.race_gen_69ee4f import race_datasets
# from .datasets.crowspairs.crowspairs_gen_381af0 import crowspairs_datasets
# and output the results in a choosen format
from .summarizers.medium import summarizer
# from .models.hf_internlm.hf_internlm2_chat_1_8b import models as hf_internlm2_chat_1_8b_models
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
meta_template = dict(
round=[
dict(role='HUMAN', begin='<|User|>:', end='\n'),
dict(role='BOT', begin='<|Bot|>:', end='<eoa>\n', generate=True),
],
eos_token_id=103028)
# internlm_chat_20b = dict(
# type=TurboMindAPIModel,
# abbr='internlm-chat-20b-turbomind',
# api_addr='http://0.0.0.0:23333',
# max_out_len=100,
# max_seq_len=2048,
# batch_size=8,
# meta_template=meta_template,
# run_cfg=dict(num_gpus=1, num_procs=1),
# end_str='<eoa>',
# )
# internlm_chat_7b = dict(
# type=TurboMindAPIModel,
# abbr='internlm-chat-7b-turbomind',
# api_addr='http://0.0.0.0:23333',
# max_out_len=100,
# max_seq_len=2048,
# batch_size=16,
# meta_template=meta_template,
# run_cfg=dict(num_gpus=1, num_procs=1),
# end_str='<eoa>',
# )
# internlm2_chat_1_8b = dict(
# type=TurboMindAPIModel,
# abbr='internlm2_chat_1_8b-turbomind',
# api_addr='http://0.0.0.0:23333',
# max_out_len=100,
# max_seq_len=2048,
# batch_size=8,
# meta_template=meta_template,
# run_cfg=dict(num_gpus=1, num_procs=1),
# end_str='<eoa>',
# )
internlm2.5_chat_7b= dict(
type=TurboMindAPIModel,
abbr='internlm2.5_chat_7b-turbomind',
api_addr='http://0.0.0.0:23333',
max_out_len=100,
max_seq_len=2048,
batch_size=8,
meta_template=meta_template,
run_cfg=dict(num_gpus=1, num_procs=1),
end_str='<eoa>',
)
models = [internlm2.5_chat_7b]
# models = [internlm_chat_20b]
conda activate opencompass
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat --server-port 23333
之后开另一个终端,连接上面的api,对internlm2.5-chat-7b大模型进行测评
conda activate opencompass
export MKL_SERVICE_FORCE_INTEL=1
python run.py configs/eval_internlm_chat_lmdeploy_apiserver.py -w outputs/turbomind/internlm2.5-chat-7b --datasets mmlu
baseline :
不使用系统提示的internlm2.5-chat-7b的任务表现如下图:

















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









