








01
引言
在过去的几年里,Transformer在 NLP 领域掀起了一场风暴。现在,它们在 NLP 之外的应用中也取得了成功。Transformer结构之所以有如此大的能量,是因为注意力模块。这是因为它能捕捉到序列中每个单词与其他单词之间的关系。
但最重要的问题是,它究竟是如何做到这一点的?在本文中,我们将尝试回答这个问题,并了解它为什么要进行这样的计算。
闲话少说,我们直接开始吧!
02
输入序列如何送入Attention模块
注意力模块存在于编码器stack中的每个编码器以及解码器stack中的每个解码器中。我们先来观察编码器中的Attention模块。
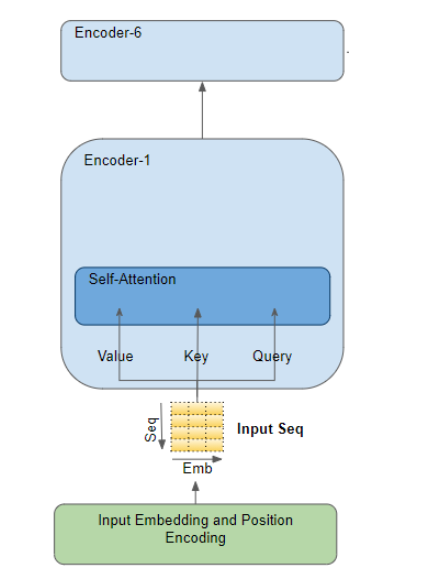
编码器中的Attention
举个例子,假设我们正在处理一个英语到西班牙语的翻译问题,其中一个样本源序列是 “The ball is blue”。目标语序列是 “La bola es azul”。
源序列首先经过嵌入层和位置编码层,该层为序列中的每个单词生成嵌入向量。嵌入向量被传递到编码器,首先到达Attention模块。在Attention模块中,嵌入序列会经过三个线性层,产生三个独立的矩阵–即Query、Key和Value。这三个矩阵用于计算注意力得分。需要牢记的是,这些矩阵的每一行对应源序列中的一个单词。
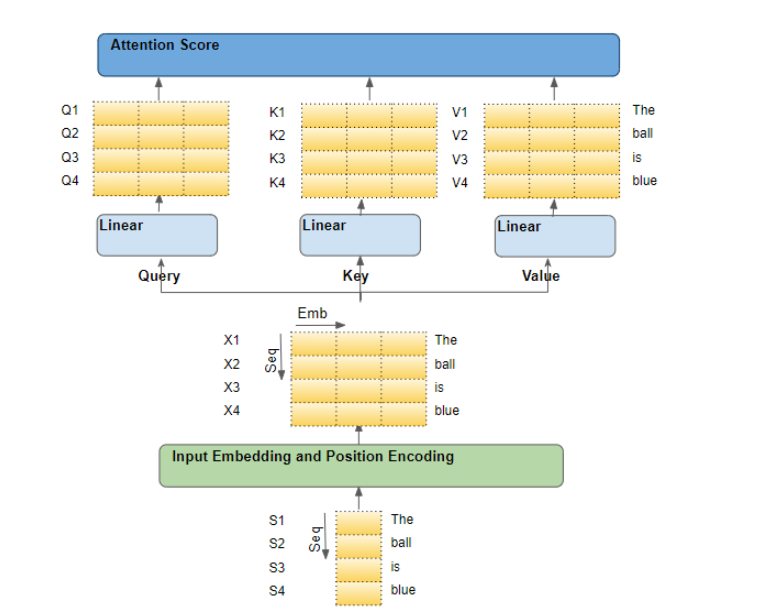
源序列的流程
03
每行都是序列中的一个单词
为了帮助大家理解Attention模块,我们首先从源序列中的单个单词开始,然后沿着它们的路径通过Transformer,我们尤其需要关注Attention模块内部的处理情况。这将有助于我们清楚地看到源序列和目标序列中的每个单词是如何与源序列和目标序列中的其他单词相互作用的。
因此,在我们进行解释时,请将注意力集中在对每个单词进行了哪些运算,以及每个向量是如何映射到原始输入单词的。一般诸如矩阵形状、算术计算的具体细节、多头注意力等许多其他细节与每个单词的走向没有直接关系,我们就不必担心。
因此,为了简化解释和可视化,让我们忽略嵌入向量的维度,只跟踪每个单词的走向。
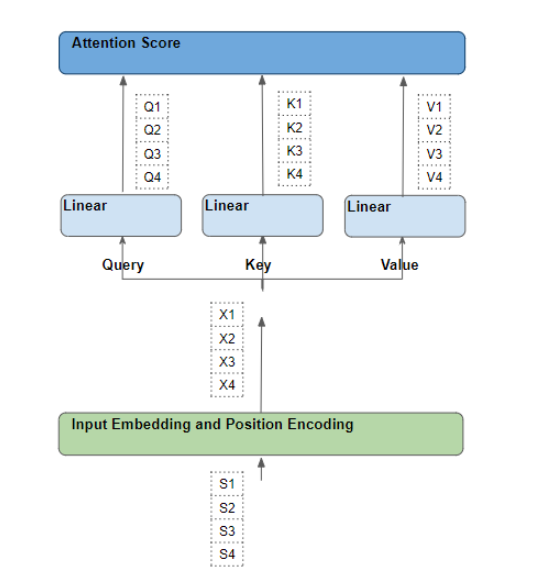
The flow of each word in the source sequence
04
每个单词都经过一系列可学习的变换
观察上图,每一行都是通过一系列转换–嵌入层、位置编码层和线性层–从相应的源序列生成的。所有这些转换操作都是可训练学习的。这意味着,这些操作中使用的权重不是预先确定的,而是通过模型学习的方式产生的。
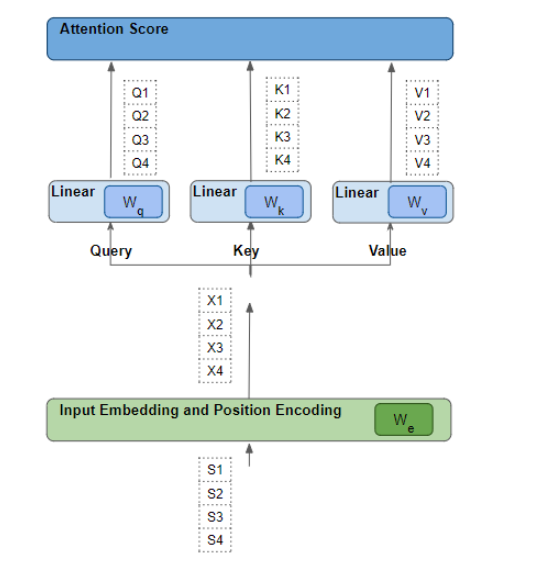
Linear and Embedding weights are learned
关键问题是,Transformer如何确定哪组权重能达到最佳的效果?请记住这一点,因为我们稍后会再讨论这个问题的。
05
注意力得分之Q和K之间的点积
Attention的计算需要经过多个步骤,但在这里,我们只关注线性层和注意力分数。
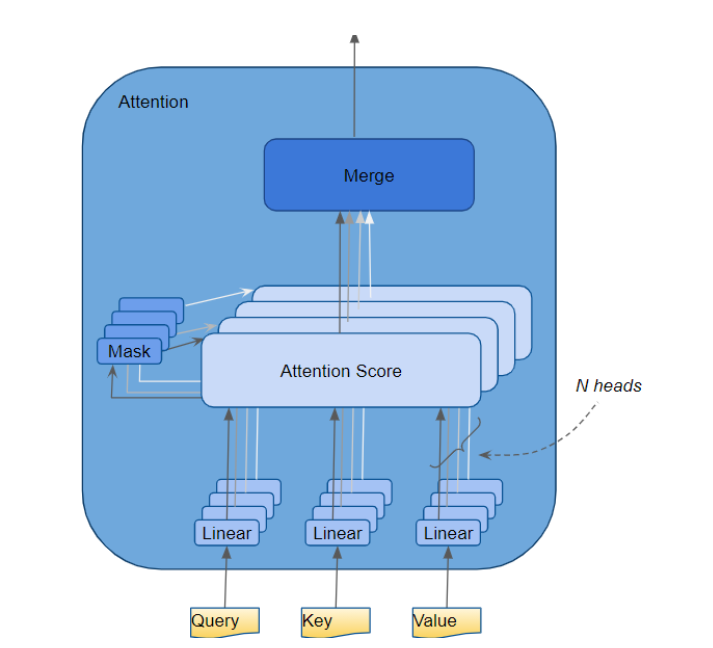
Multi-head attention
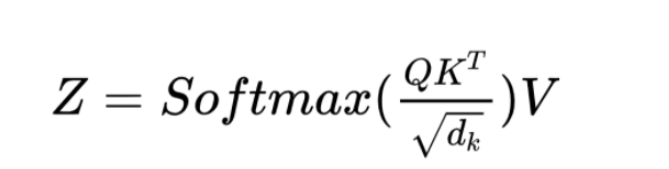
Attention Score calculation
从上述公式中我们可以看到,Attention 的第一步是在Query矩阵和Key矩阵的转置之间进行矩阵乘法(即点积)。看看每个单词会发生什么变化。我们生成一个中间矩阵,其中每个单元格都是两个词之间的矩阵乘法。
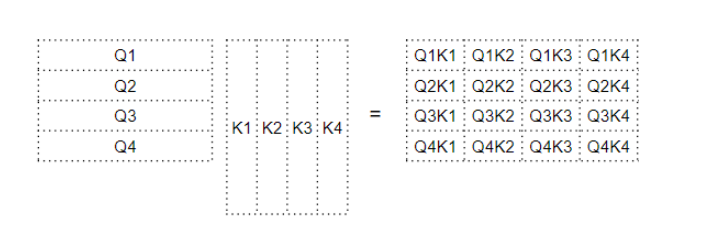
Query矩阵和Key矩阵之间的点积
例如,第四行的每一列都对应于第四个Query与每个Key之间的点积。
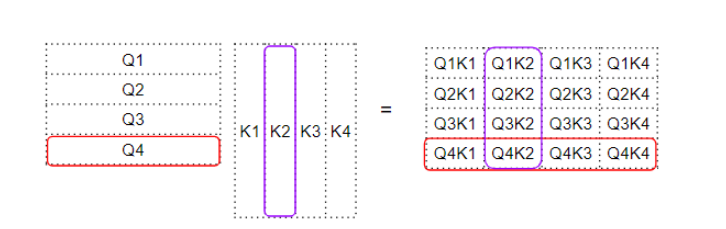
Query矩阵和Key矩阵之间的点积
06
注意力得分之Q-K和V之间的点积
下一步是将上一步中得到的中间矩阵与Value矩阵相乘,得出注意力模块中的注意力分数。
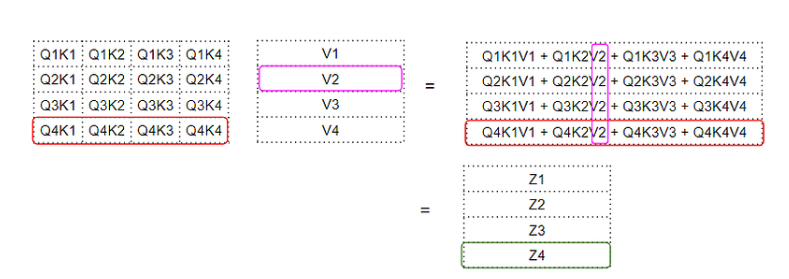
Dot Product between Query-Key and Value matrices
在这里,我们可以看到第四行对应的是第四个Query矩阵与所有其他Key和Value的乘积。这就产生了注意力模块输出的注意力分数向量 Z。
我们可以这样来理解输出注意力得分:对于每个单词来说,它都是Value矩阵中每个词的编码值,并由中间矩阵加权。中间矩阵是该特定词的Query值与所有词的Value值的点积。

Attention Score is a weighted sum of the Value words
07
Query,Key,Value的作用是什么?
Query可以解释为我们当前需要计算注意力得分的词。Key和Value是我们需要关注的词,即该词与Query的相关程度。
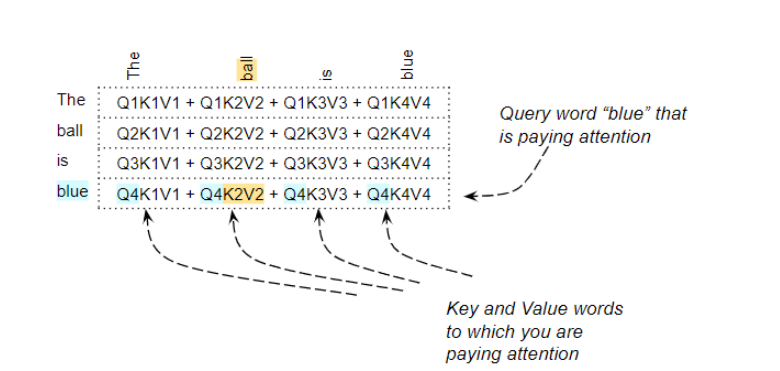
Attention Score for the word “blue” pays attention to every other word
例如,对于 "The ball is blue"这句话来说,"blue"这一行将包含单词"blue"与其他每个单词的Attention得分。这里,"blue "是Query,其他单词是 “Key/Value”。
还有其他一些操作需要执行,如除法和softmax,但在本文中我们可以忽略它们。它们只是改变矩阵中的数值,但不会影响矩阵中每个单词行的位置。
08
点积衡量单词之间的相似度
因此,我们可以看到,注意力分数是通过点积,然后将它们相加,来捕捉特定单词与句子中其他单词之间的一些互动关系。但是矩阵乘法如何帮助Transformer来确定两个词之间的相关性呢?
要理解这一点,请记住Query、Key和Value实际上是具有嵌入维度的向量。让我们来看看这些向量之间的矩阵乘法是如何计算的。
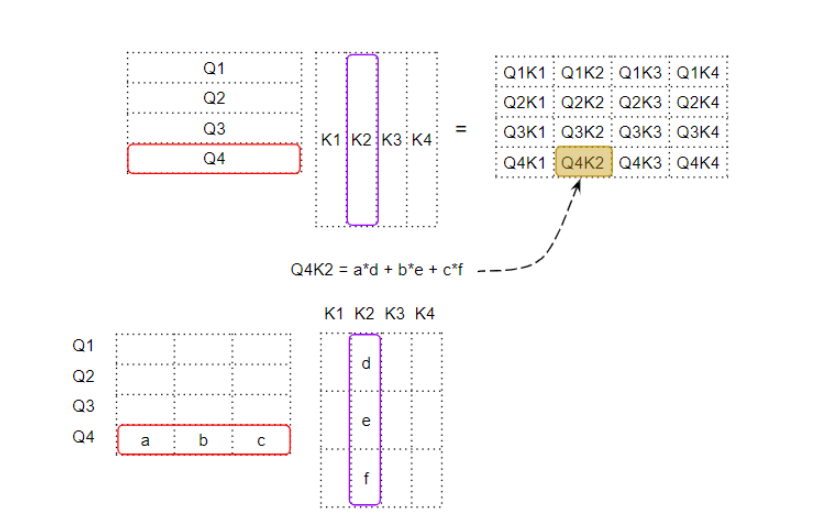
每个单元都是两个词向量的点积
当我们在两个向量之间进行点积操作时,我们是将对应位置上的一对数字相乘,然后求和。
-
如果两个配对的元素(如上面的 "a "和 “d”)都是正数或都是负数,那么乘积将是正数。乘积将增加最终的求和结果。
-
如果一个数是正数,另一个数是负数,那么乘积就是负数。乘积将减少最终的求和结果。
-
如果乘积是正数,则两个数字越大,它们对最终求和的贡献就越大。
这意味着,如果两个向量中相应数字的符号一致,最终的和会更大。
09
Transformer如何学习词语间的相关性
点积的概念同样适用于注意力得分。如果两个词的向量更加一致,那么注意力得分就会更高。那么,我们希望Transformer有什么样的行为呢?
我们希望句子中相互关联的两个词的注意力得分高。而对于两个互不相关的词语,我们则希望其得分较低。
例如,在 "The black cat drank the milk"这个句子中,"milk"与 "drank"非常相关,与 "cat"的相关性可能略低,而与 "black"则无关。我们希望 "milk"和 "drank"产生较高的Attention得分,"milk"和 "cat"产生稍低的分值,而 "milk"和 "black"产生的分值可以忽略不计。
这是我们希望模型通过训练学习产生的输出结果。为此,milk和drank的词向量必须对齐。milk和cat的词向量会有些偏离。而 milk和 black的词向量则会大不相同。
让我们回到我们一直萦绕在脑海中的问题–Transformer是如何计算出哪组权重能达到最佳效果的?
词向量是根据词嵌入和线性层的权重生成的。因此,Transformer可以学习这些嵌入层和线性层权重,从而生成上述所需的词向量。换句话说,它将以这样一种方式学习这些层的权重:如果句子中的两个词彼此相关,那么它们的词向量就会对齐。从而产生更高的注意力得分。而对于互不相关的单词,单词向量将不会对齐,并产生较低的注意力得分。
因此,milk和drank的嵌入会非常一致,并产生较高的注意力得分。在milk和cat的嵌入中,它们会有一些偏离,从而产生稍低的分数,而在milk和black的嵌入中,它们会有很大的不同,从而产生较低的分数。
这就是注意力模块的原理。
10
Transformer中的Attention
Query和Key之间的点积计算出每对词之间的相关性。然后,将该相关性作为一个 “因子”,计算出所有Value的加权总和。加权总和将作为注意力得分的输出。
Transformer结构中有三处使用了Attention:
-
编码器中的自注意力 --关注源序列自身
-
解码器中的自注意力 --关注目标序列自身
-
解码器中的交叉注意力 – 目标序列关注源序列
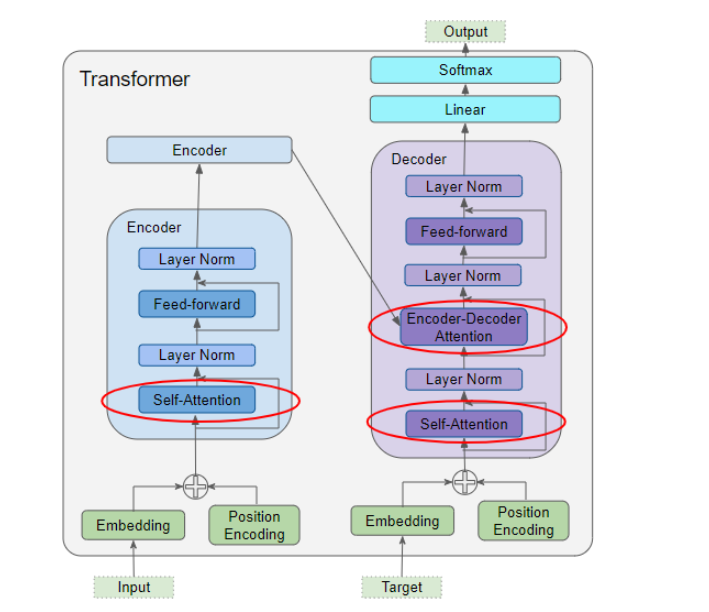
Attention in the Transformer
在编码器自注意力中,我们计算源句子中每个单词与源句子中其他单词的相关性。这发生在编码器stack中的所有编码器中。
11
解码器中的自注意力
我们刚才在编码器的自我注意力中看到的大部分内容也适用于解码器中的自注意力的计算,只是存在一些微小但重要的区别。
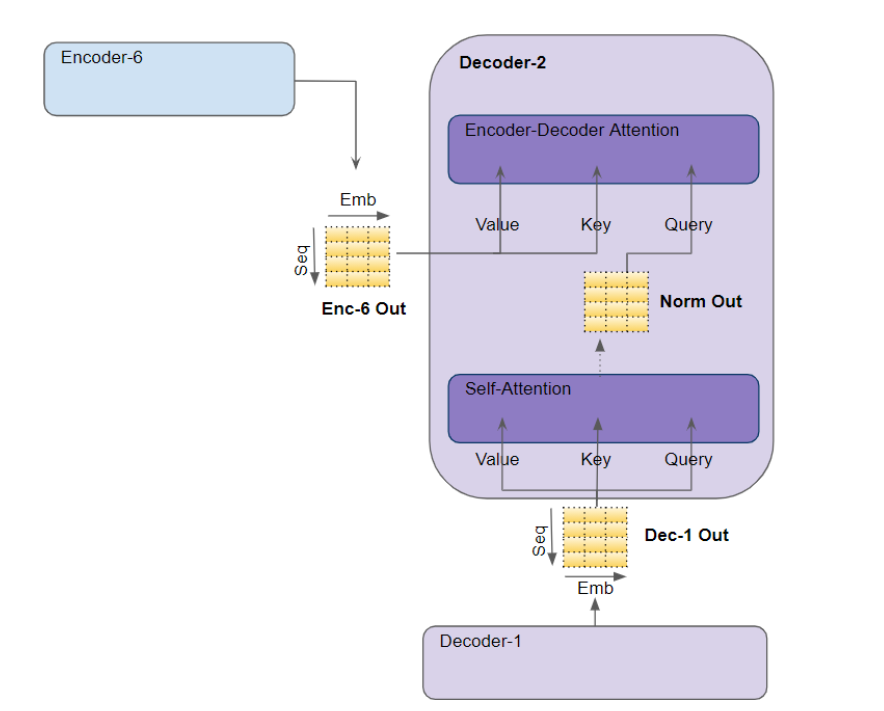
Attention in the Decoder
在解码器自注意力计算过程中,我们计算目标句中每个单词与目标句中其他单词的相关性。
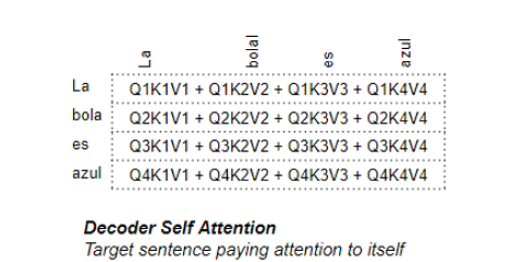
Decoder Self Attention
12
解码器中的交叉注意力
在解码器的交叉注意力的计算过程中,Query来自目标语句,而Key/Value来自源输入语句。这样,它就能计算出目标语句中每个词与源输入语句中每个词的相关性。
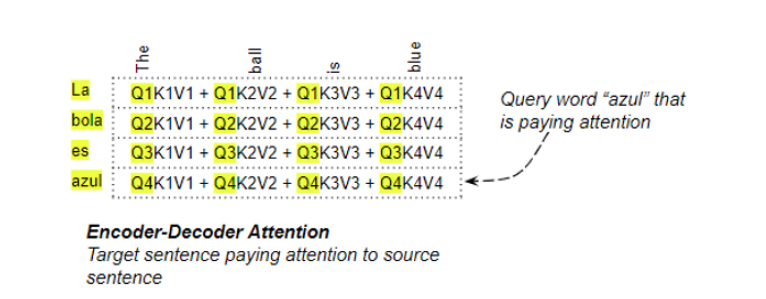
Encoder-Decoder Attention
13
总结
希望这能让大家充分感受到 Transformer设计的优雅。请阅读我的系列文章中的其他 Transformer 文章,深入了解为什么 Transformer 如今已成为众多深度学习应用的首选架构。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









