



什么是支持向量机?
支持向量机(Support Vector Machine,SVM)是一种经典的监督学习算法,用于解决二分类和多分类问题。 其核心思想是通过在特征空间中找到一个最优的超平面来进行分类,并且间隔最大。 SVM能够执行线性或非线性分类、回归,甚至是异常值检测任务。 它是机器学习领域最受欢迎的模型之一。
支持向量机是一种二分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。支持向量机的学习算法是求解凸二次规划的最优化算法。
基础的SVM算法是一个二分类算法,至于多分类任务,可以通过多次使用SVM进行解决。
线性可分与线性不可分
能够用一条直线对样本点进行分类的属于线性可区分(linear separable),否则为线性不可区分(linear inseparable)。
以下例子为线性不可分:
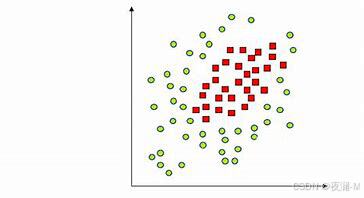
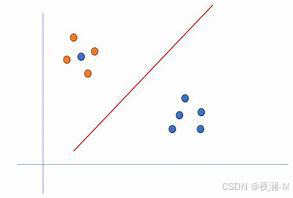
线性可分:
可以看出线性可分与线性不可分的区别在于能否用直线或超平面将向量分割为互不相干的两部分。
在线性不可分的情况下,数据集在空间中对应的向量无法被一个超平面区分开,如何处理?
- 利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中(比如下图将二维空间中的点映射到三维空间)
- 在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理
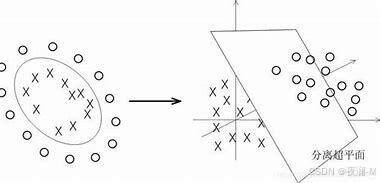
线性可分情况下,应注意哪些问题?
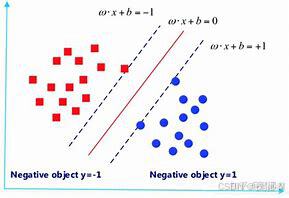
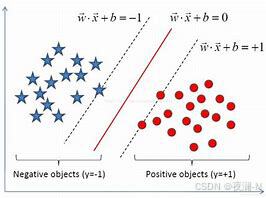
线性可分情况下,实例的特征向量(以二维为例)映射为空间中的一些点,如下图的实心点和空心点,它们属于不同的两类。SVM 的目的就是想要画出一条线,以“最好地”区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
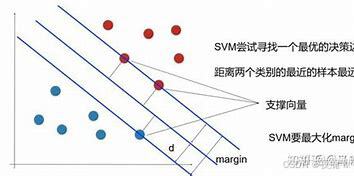
- 分割时先可以划分无数条,区别就在于效果好不好,每条线都可以叫做一个划分超平面。我们所希望找到的这条效果最好的线就是具有 “最大间隔的划分超平面”。
- 确定分割线时,寻找可以区分两个类别并且能使间隔(margin)最大的划分直线或超平面(三维及以上使用)。比较好的划分超平面,样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。
- 间隔:点到分割面的距离,称为点相对于分割面的间隔。数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。论文中提到的间隔多指这个间隔。SVM分类器就是要找最大的数据集间隔。
- 支持向量:离分隔超平面最近的那些点。
寻找最大间隔
(1)分隔超平面
二维空间一条直线的方程为,y=ax+b,推广到n维空间,就变成了超平面方程,即
w是权重,b是截距,训练数据就是训练得到权重和截距。
(2)如何找到最好的参数
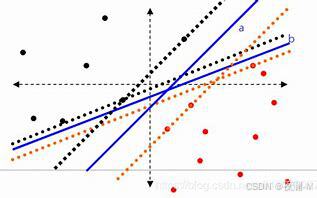
支持向量机的核心思想: 最大间隔化, 最不受到噪声的干扰。如上图所示,分类器a比分类器b的间隔(虚线间隔)大,因此a的分类效果更好。
总结
SVM的优点:
高效的处理高维特征空间:SVM通过将数据映射到高维空间中,可以处理高维特征,并在低维空间中进行计算,从而有效地处理高维数据。
适用于小样本数据集:SVM是一种基于边界的算法,它依赖于少数支持向量,因此对于小样本数据集具有较好的泛化能力。
可以处理非线性问题:SVM使用核函数将输入数据映射到高维空间,从而可以解决非线性问题。常用的核函数包括线性核、多项式核和径向基函数(RBF)核。
避免局部最优解:SVM的优化目标是最大化间隔,而不是仅仅最小化误分类点。这使得SVM在解决复杂问题时能够避免陷入局部最优解。
对于噪声数据的鲁棒性:SVM通过使用支持向量来定义决策边界,这使得它对于噪声数据具有一定的鲁棒性。
(2)SVM的缺点:
对大规模数据集的计算开销较大:SVM的计算复杂度随着样本数量的增加而增加,特别是在大规模数据集上的训练时间较长。
对于非线性问题选择合适的核函数和参数较为困难:在处理非线性问题时,选择适当的核函数和相应的参数需要一定的经验和领域知识。
对缺失数据敏感:SVM在处理含有缺失数据的情况下表现不佳,因为它依赖于支持向量的定义。
难以解释模型结果:SVM生成的模型通常是黑盒模型,难以直观地解释模型的决策过程和结果。
SVM在处理小样本数据、高维特征空间和非线性问题时表现出色,但对于大规模数据集和缺失数据的处理相对困难。同时,在模型的解释性方面也存在一定的挑战。

















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









