



什么是强化学习
在连接主义学习中,在学习的方式有三种:非监督学习(unsupervised learning)、监督学习
(supervised leaning)和强化学习。监督学习也称为有导师的学习,需要外界存在一个“教师”对给定
输入提供应有的输出结果,学习的目的是减少系统产生的实际输出和预期输出之间的误差,所产生
的误差反馈给系统来指导学习。非监督学习也称为无导师的学习。它是指系统不存在外部教师指导
的情形下构建其内部表征。学习完全是开环的。
生物进化过程中为适应环境而进行的学习有两个特点:一是人从来不是静止的被动的等待而是主动
的对环境作试探;二是环境对试探动作产生的反馈是评价性的,生物根据环境的评价来调整以后的
行为,是一种从环境状态到行为映射的学习,具有以上特点的学习就是强化学习。
强化学习(reinforcement learning)又称为再励学习,是指从环境状态到行为映射的学习,以使系
统行为从环境中获得的累积奖励值最大的一种机器学习方法,智能控制机器人及分析预测等领域有
许多应用。
强化学习VS其他机器学习
1.没有监督者,只有量化奖励信号
2.反馈延迟,只有进行到最后才知道当下的动作是好是坏
3.强化学习属于顺序决策,根据时间一步一步决策行动,训练数据不符合独立分布条件
4.每一步行动影响下一步状态以及奖励
强化学习的原理及概念
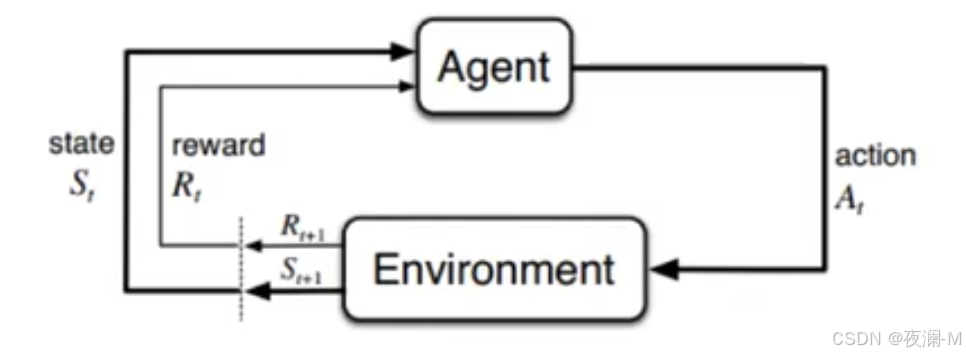
Agent(智能体、机器人、代理):强化学习训练的主体就是Agent,有时候翻译为“代理”,这里统称为“智能体”。Pacman中就是这个张开大嘴的黄色扇形移动体。
Environment(环境):整个游戏的大背景就是环境;Pacman中Agent、Ghost、豆子以及里面各个隔离板块组成了整个环境。
State(状态):当前 Environment和Agent所处的状态,因为Ghost一直在移动,豆子数目也在不停变化,Agent的位置也在不停变化,所以整个State处于变化中;这里特别强调一点,State包含了Agent和Environment的状态。
Action(行动):基于当前的State,Agent可以采取哪些action,比如向左or右,向上or下;Action是和State强挂钩的,比如上图中很多位置都是有隔板的,很明显Agent在此State下是不能往左或者往右的,只能上下;
Reward(奖励):Agent在当前State下,采取了某个特定的action后,会获得环境的一定反馈就是Reward。这里面用Reward进行统称,虽然Reward翻译成中文是“奖励”的意思,但其实强化学习中Reward只是代表环境给予的“反馈”,可能是奖励也可能是惩罚。比如Pacman游戏中,Agent碰见了Ghost那环境给予的就是惩罚。
强化学习的主要特点
试错学习:强化学习需要训练对象不停地和环境进行交互,通过试错的方式去总结出每一步的最佳行为决策,整个过程没有任何的指导,只有冰冷的反馈。所有的学习基于环境反馈,训练对象去调整自己的行为决策。
延迟反馈:强化学习训练过程中,训练对象的“试错”行为获得环境的反馈,有时候可能需要等到整个训练结束以后才会得到一个反馈,比如Game Over或者是Win。当然这种情况,我们在训练时候一般都是进行拆解的,尽量将反馈分解到每一步。
时间是强化学习的一个重要因素:强化学习的一系列环境状态的变化和环境反馈等都是和时间强挂钩,整个强化学习的训练过程是一个随着时间变化,而状态&反馈也在不停变化的,所以时间是强化学习的一个重要因素。
当前的行为影响后续接收到的数据:为什么单独把该特点提出来,也是为了和监督学习&半监督学习进行区分。在监督学习&半监督学习中,每条训练数据都是独立的,相互之间没有任何关联。但是强化学习中并不是这样,当前状态以及采取的行动,将会影响下一步接收到的状态。数据与数据之间存在一定的关联性。
强化学习训练过程
马尔科夫决策过程(Markov Decision Process)
Markov是一个俄国的数学家,为了纪念他在马尔可夫链所做的研究,所以以他命名了“Markov Decision Process”,以下用MDP代替。


















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









