



一、Chain的限制:当固定流程遇上复杂场景
前面九篇文章,我们用Chain构建了各种应用:RAG问答、Agent工具调用、数据分析。Chain确实很强大,但它有个根本性的限制:执行路径是固定的有向无环图(DAG)。
也就是说Chain的每个步骤只能执行一次,不能回头,不能循环。流程是线性的:A → B → C → D,走完就结束。
这在很多场景下不够用。举几个实际需求:
场景1:对话确认机制
用户问:“帮我订一张明天去北京的机票”
系统查询后:“找到3个航班,请选择…”
用户:“第一个”
系统:“确认订购XX航班吗?”
用户:“确认”
这需要多轮交互,每轮都要根据用户反馈决定下一步。Chain做不到,因为它不能根据中间结果决定是继续提问还是执行订购。
场景2:迭代优化流程
让AI写一篇文章:先生成大纲 → 检查大纲质量 → 如果不满意就重新生成 → 满意后再写正文。
这个"检查-重试"的循环,Chain无法实现。
我们需要一个更灵活的框架,能支持循环、条件分支、状态记忆。这就是LangGraph诞生的原因。
二、LangGraph:打破线性的束缚
LangGraph是LangChain生态的高级框架,专门用于构建复杂的、有状态的工作流。它的核心创新是:把工作流看作一个状态机(State Machine),而不是简单的链。
三、LangGraph的核心概念
1. StateGraph(状态图)
StateGraph是LangGraph的基础,它定义了一个带状态的图结构。状态在节点间传递和更新,记录了整个执行过程的信息。
from langgraph.graph import StateGraph
from typing import TypedDict
class WorkflowState(TypedDict):
messages: list
user_input: str
should_continue: bool
graph = StateGraph(WorkflowState)
状态对象可以包含任何信息:对话历史、中间结果、控制标志等。
2. Nodes(节点)
节点是执行具体任务的函数。每个节点接收当前状态,执行操作,返回更新后的状态。
def process_input(state: WorkflowState) -> WorkflowState:
# 处理用户输入
user_text = state["user_input"]
# ... 处理逻辑 ...
state["messages"].append({"role": "user", "content": user_text})
return state
节点可以调用LLM、使用工具、执行计算,做任何你需要的操作。
3. Edges(边)
边定义了节点之间的连接关系。LangGraph支持两种边:
普通边(Normal Edge):无条件跳转,执行完A必然跳到B。
graph.add_edge("node_a", "node_b")
条件边(Conditional Edge):根据状态内容决定跳转到哪里,这是实现分支和循环的关键。
def should_continue(state: WorkflowState) -> str:
if state["should_continue"]:
return "continue_chat"
else:
return "end_chat"
graph.add_conditional_edges(
"check_node",
should_continue,
{
"continue_chat": "llm_node",
"end_chat": "end"
}
)
条件函数检查状态,返回一个字符串,LangGraph根据这个字符串决定下一步走向。
四、实战:可循环的对话机器人
现在用LangGraph实现一个多轮对话机器人,它能:
- 记住对话历史
- 根据用户输入决定是继续对话还是结束
- 支持无限轮对话
# LangChain生态学习系列 - LangGraph循环对话示例
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage, AIMessage
import operator
# 定义状态结构
class ChatState(TypedDict):
messages: Annotated[list, operator.add] # 消息列表,自动追加
user_input: str
round_count: int
# 初始化LLM
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)
# 节点1:处理用户输入
def handle_user_input(state: ChatState) -> ChatState:
user_text = state.get("user_input", "")
return {
"messages": [HumanMessage(content=user_text)],
"round_count": state.get("round_count", 0) + 1
}
# 节点2:生成AI回复
def generate_response(state: ChatState) -> ChatState:
messages = state["messages"]
response = llm.invoke(messages)
return {
"messages": [AIMessage(content=response.content)]
}
# 条件判断:是否继续对话
def should_continue_chat(state: ChatState) -> str:
user_input = state.get("user_input", "").lower()
# 如果用户说再见,结束对话
if any(word in user_input for word in ["再见", "拜拜", "结束", "quit"]):
return "end"
# 限制最多10轮对话(防止无限循环)
if state.get("round_count", 0) >= 10:
return "end"
return "continue"
# 构建状态图
workflow = StateGraph(ChatState)
# 添加节点
workflow.add_node("process_input", handle_user_input)
workflow.add_node("generate_reply", generate_response)
# 设置入口点
workflow.set_entry_point("process_input")
# 添加边:输入处理 → 生成回复
workflow.add_edge("process_input", "generate_reply")
# 添加条件边:根据对话状态决定继续或结束
workflow.add_conditional_edges(
"generate_reply",
should_continue_chat,
{
"continue": "process_input", # 循环回到输入处理
"end": END # 结束整个工作流
}
)
# 编译图
chat_app = workflow.compile()
# 运行对话
if __name__ == "__main__":
print("聊天机器人已启动(输入'再见'结束对话) ")
state = {"messages": [], "user_input": "", "round_count": 0}
while True:
user_input = input("你: ")
state["user_input"] = user_input
# 执行工作流
result = chat_app.invoke(state)
# 获取最新的AI回复
ai_message = result["messages"][-1]
print(f"助手: {ai_message.content}")
# 更新状态
state = result
# 检查是否结束
if should_continue_chat(state) == "end":
print("对话结束,再见!")
break
五、可视化工作流结构
LangGraph支持将图结构导出为Mermaid格式,方便理解流程:
from langgraph.graph import Mermaid
# 生成Mermaid图
mermaid_code = chat_app.get_graph().draw_mermaid()
print(mermaid_code)
输出类似:
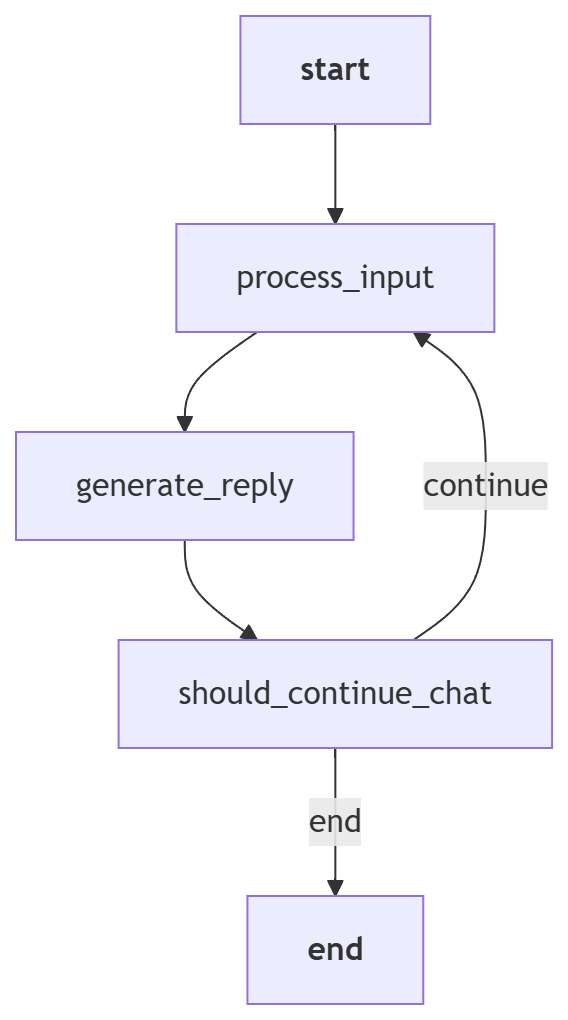
这个图清楚地展示了循环结构:generate_reply可以回到process_input。
六、LangGraph vs Chain:能力对比
| 特性 | Chain | LangGraph |
|---|---|---|
| 循环执行 | 不支持 | 支持 |
| 条件分支 | 有限支持 | 完全支持 |
| 状态管理 | 不保存 | 完整状态对象 |
| 回溯能力 | 不支持 | 支持 |
| 复杂度 | 简单 | 较复杂 |
| 适用场景 | 简单流程 | 复杂工作流 |
七、实际应用场景
LangGraph特别适合这些场景:
迭代式内容生成:写文章 → 评估质量 → 不满意就修改 → 满意后发布。
多轮审批流程:提交申请 → 初审 → 如果不通过返回修改 → 复审 → 终审。
游戏AI:观察环境 → 决策 → 执行动作 → 观察结果 → 继续决策(循环)。
客服机器人:理解问题 → 查询知识库 → 如果没找到答案就澄清问题 → 重新查询 → 直到解决。
数据处理管道:读取数据 → 验证 → 如果验证失败清洗数据 → 重新验证 → 处理 → 保存。
八、从线性到图:思维方式的转变
使用LangGraph需要改变思维方式:
Chain思维:把问题分解成线性步骤,设计一条路径。
LangGraph思维:把问题看作状态转换,设计状态机。
关键问题变成了:
- 我的状态对象需要包含哪些信息?
- 每个节点如何更新状态?
- 什么条件下应该循环、分支或结束?
这需要一点适应期,但一旦掌握,你会发现很多之前难以实现的功能变得简单了。
九、从Chain到Graph:能力升级
今天我们完成了从Chain到LangGraph的跨越,但今天的例子还比较简单,状态对象只包含几个字段。在实际应用中,你可能需要管理复杂的多层状态、处理执行过程中的错误、实现中断恢复等功能。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 2348
2348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









