



Tabm是一个可以用于结构化(tabular)数据的分类和回归任务的深度学习模型。
在广泛的结构化数据集上,Tabm取得了和lightgbm/catboost等树模型相匹敌或者更优的效果。
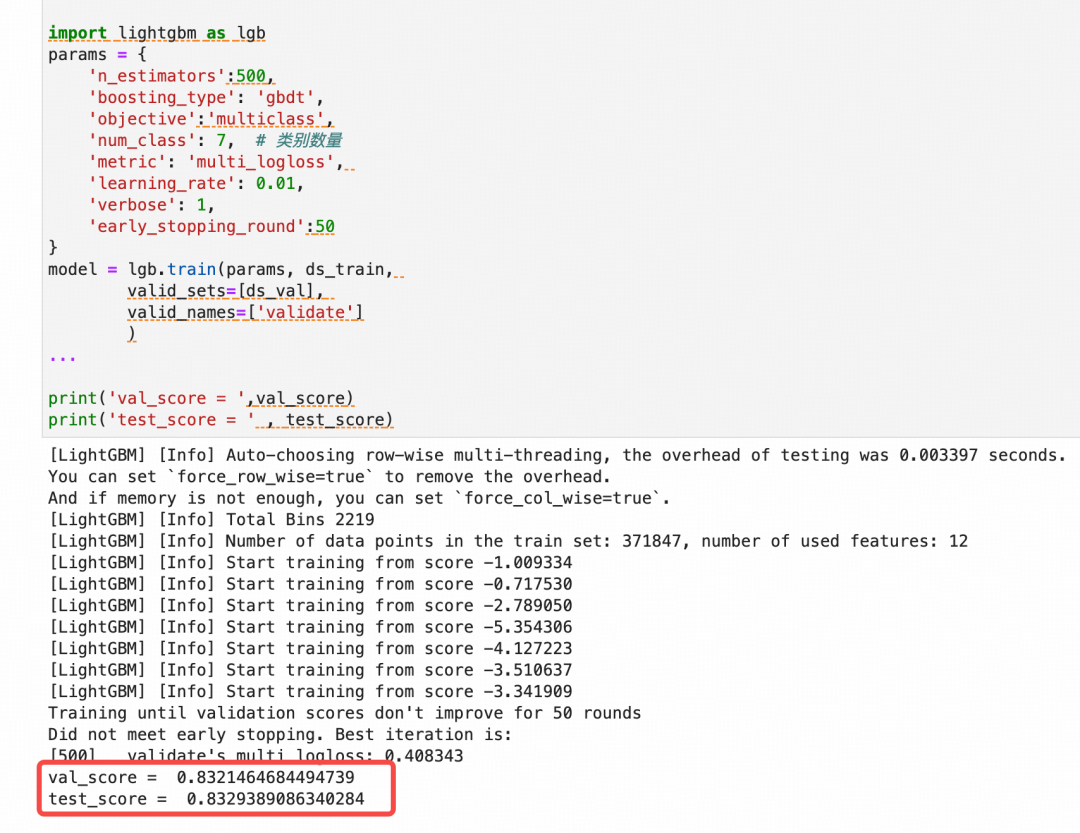
在本文范例的Covertype数据集多分类数据集上,Tabm模型的测试集准确率为93%,远超lightgbm的83%~
Tabm它的名字是 Tabular 和 Multiple单词开头的拼接。
含义是:A Tabular DL model that makes Multiple predictions。
顾名思义,Tabm模型能够同时输出多个预测,并且取这些预测的平均作为最终的输出。
这是一种非常经典的模型集成的思想,叫做bagging,就像随机森林做的那样。
你可以这样大致理解Tabm的原理。
1,Tabm由许多MLP小模型(例如k=32个)组成的,每个小模型都可以输出独立的预测,每个小模型的loss也是独立计算的。最终的预测是它们的预测结果的平均。
2,为了减少总的权重参数规模,这些小模型有相当多的权重参数是共享的,因此Tabm的实际权重大小是显著小于许多个完全独立的小模型的,这种权重共享的设计实际上也起到了一定的正则化的作用,可以提升模型的效果。
3,Tabm还引入了精心设计的对数值特征的PLREmbedding技术以及模型参数初始化方法,这些设计也能显著提升模型的效果。
本范例我们使用Covertype数据集,它的目标是预测植被覆盖类型,是一个七分类问题。
公众号算法美食屋后台回复关键词:torchkeras,获取本文notebook源码和所用Covertype数据集下载链接。
!pip install tabm
!pip install torchkeras==4.0.5一,准备数据
我们加载torchkeras中的 TabularPreprocessor来实现自动化的特征预处理。包括缺失值填充,类别特征编码,数值特征归一化等。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
file_path = "covertype.parquet"
dfdata = pd.read_parquet(file_path)
...from torchkeras.tabular import TabularPreprocessor
from sklearn.preprocessing import OrdinalEncoder
#特征工程
pipe = TabularPreprocessor(cat_features = cat_cols,
embedding_features=cat_cols)
encoder = OrdinalEncoder()
dftrain = pipe.fit_transform(dftrain_raw.drop(target_col,axis=1))
...from torchkeras.tabular import TabularDataset
from torch.utils.data import Dataset,DataLoader
...
ds_train = get_dataset(dftrain)
...
dl_train = get_dataloader(ds_train,shuffle=True)
...二,定义模型
tabm模型在 torchkeras的 tabular模块中进行了一个容易使用的封装,可以直接调用。
from torchkeras.tabular.models import TabMConfig, TabMModel
# 配置模型
model_config = TabMConfig(
task="multiclass", #regression, binary, multiclass
k=32
)
# 合并数据集配置
config = model_config.merge_dataset_config(ds_train)
print('模型配置:')
print('categorical_cardinality =', config.categorical_cardinality)
print('embedding_dims =', config.embedding_dims)
# 初始化模型
net = TabMModel(config=config)
print(net.hparams.output_dim)三,训练模型
下面我们使用梦中情炉来训练tabm模型。
from torchkeras import KerasModel
from torchkeras.tabular import StepRunner
KerasModel.StepRunner = StepRunnerkeras_model = KerasModel(net,
loss_fn=None,
optimizer = torch.optim.AdamW(net.parameters(),lr = 1e-3),
metrics_dict = {"acc":Accuracy()}
)keras_model.fit(
train_data = dl_train,
val_data= dl_val,
ckpt_path='checkpoint',
epochs=30,
patience=10,
monitor="val_acc",
mode="max",
plot = True,
wandb = False
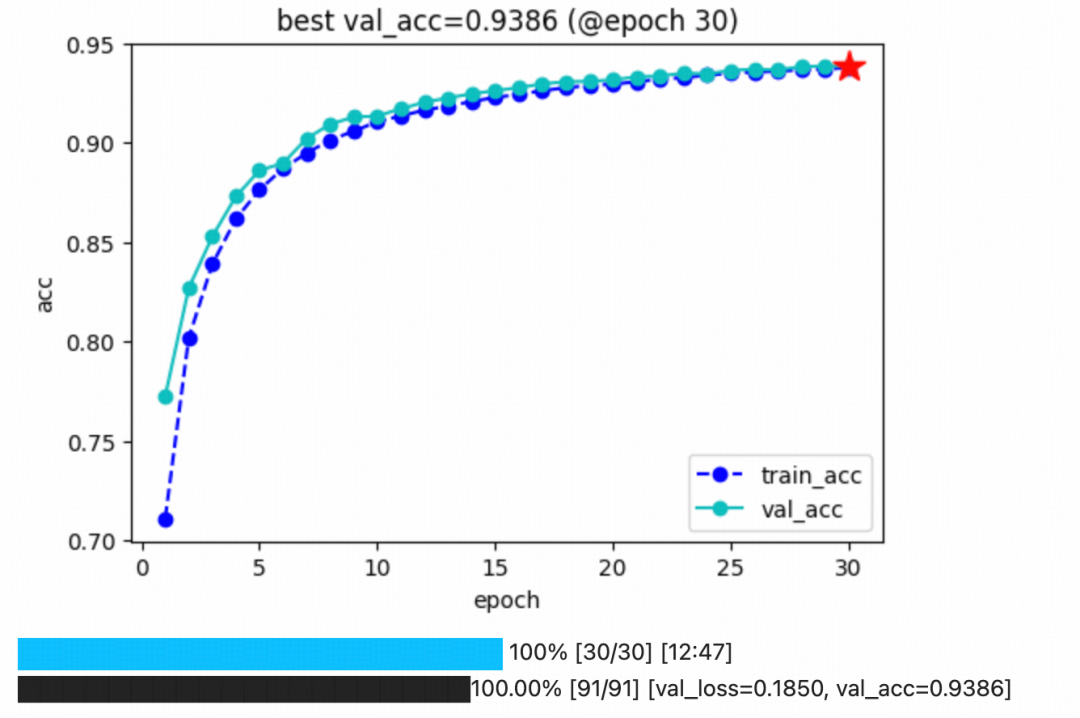
)
四,评估模型
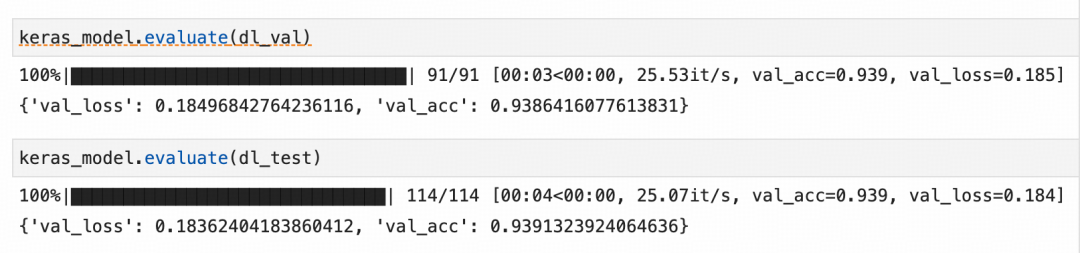
五,与LightGBM对比
使用默认参数的lightgbm模型来对比看看效果。
公众号算法美食屋后台回复关键词:torchkeras,获取本文notebook源码和所用Covertype数据集下载链接。

















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









