







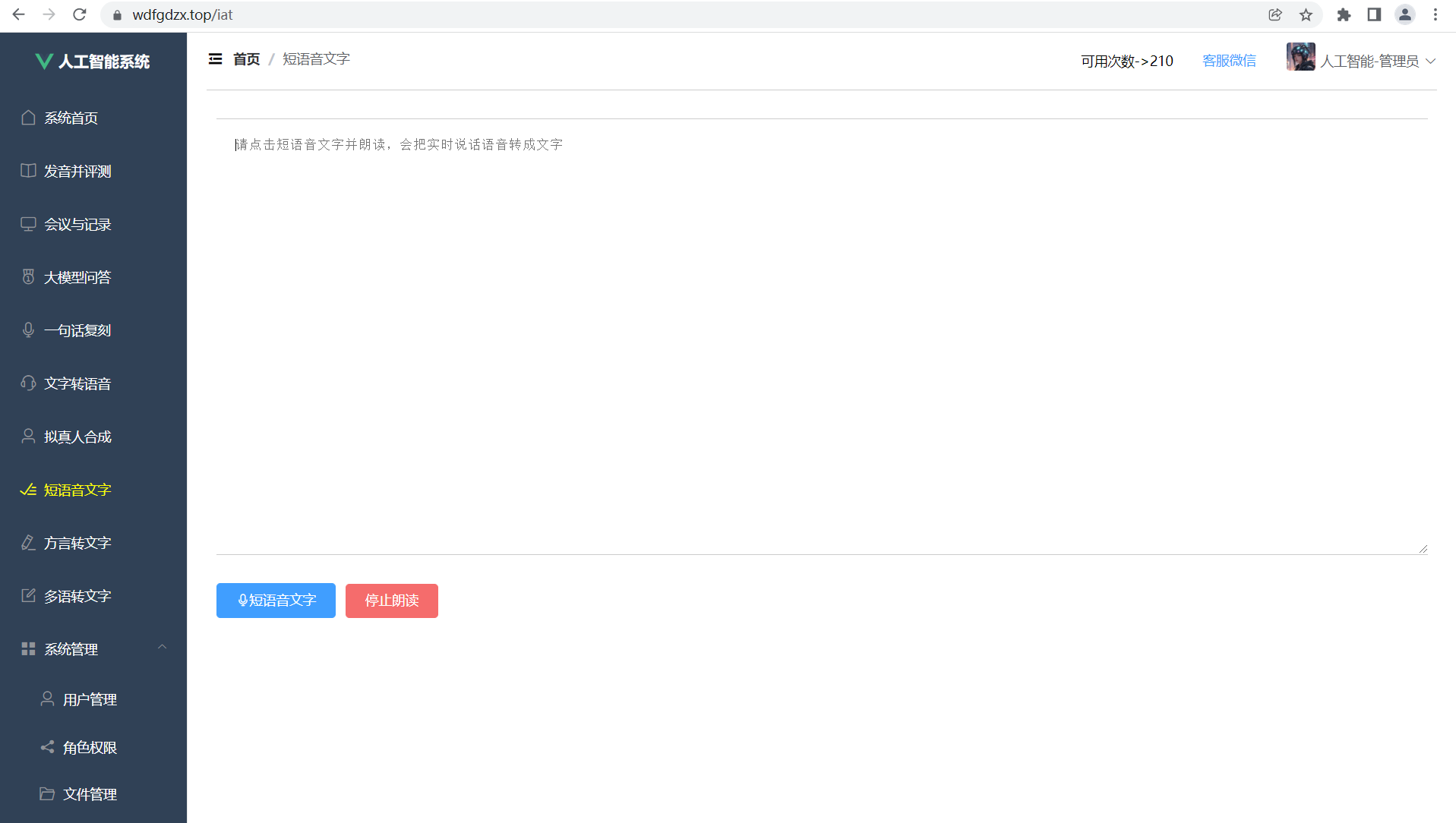
在当今AI技术飞速发展的时代,语音识别技术已经成为人机交互的重要方式之一。本文将详细介绍如何基于WebSocket协议实现一个实时语音转文字的前端应用,该应用能够将用户的语音实时转换为文字显示在文本框中,并支持短语音识别和手动停止功能。
一、技术架构概述
本实现主要采用了以下核心技术:
-
WebSocket协议:用于建立客户端与语音识别服务器之间的全双工通信通道
-
Recorder.js:前端录音库,用于捕获用户的语音输入
-
科大讯飞开放平台:提供语音识别(IAT)的API服务
-
Vue.js框架:前端MVVM框架,用于构建用户界面
-
Element UI:提供美观的UI组件
整个技术栈构成了一个完整的前端语音识别解决方案,实现了从语音采集、实时传输到文字转换的全流程。
二、核心代码解析
2.1 前端界面设计
界面设计简洁明了,主要包含以下几个部分:
<template>
<div class="Iat-container" style="padding: 10px;margin-bottom:50px;">
<!-- 聊天窗口开始 -->
<div style="height: 150px;">
<textarea v-model="text"
placeholder="请点击短语音文字并朗读,会把实时说话语音转成文字"
style="height: 460px;width: 100%;padding: 20px; border: none;border-top: 1px solid #ccc;border-bottom: 1px solid #ccc;outline: none">
</textarea>
</div>
<div style="text-align: left;padding-right: 10px;margin-top: 340px;">
<el-button type="primary" size="medium" @click="voiceSend">
<i class="el-icon-microphone"></i>短语音文字
</el-button>
<el-button type="danger" size="medium" @click="stopVoice">
停止朗读
</el-button>
</div>
</div>
</template>
-
textarea:用于显示实时转换的文字结果
-
两个按钮:分别用于开始录音和停止录音
-
样式设计采用简洁风格,突出核心功能
2.2 录音功能实现
录音功能使用Recorder.js库实现,这是一个强大的前端录音解决方案:
import Recorder from '../../public/recorder/index.umd.js'
// 初始化录音工具
let recorder = new Recorder("../../recorder")
recorder.onStart = () => {
console.log("开始录音了")
}
recorder.onStop = () => {
console.log("结束录音了")
}
录音的核心配置包括采样率和帧大小:
javascript
复制
下载
recorder.start({
sampleRate: 16000, // 采样率16kHz
frameSize: 1280, // 帧大小
});
这里选择16kHz采样率是因为它在语音识别中既能保证识别质量,又能减少数据量。帧大小设置为1280字节,这是一个经验值,可以在实时性和性能之间取得平衡。
2.3 WebSocket连接管理
与语音识别服务器的通信通过WebSocket实现:
wsTask = new WebSocket(reqeustUrl);
// WebSocket事件处理
wsTask.onopen = function() {
console.log('ws已经打开...')
wsFlag = true
// 发送第一帧数据...
}
wsTask.onmessage = function(message) {
// 处理服务器返回的识别结果...
}
wsTask.onclose = function() {
console.log('ws已关闭...')
}
wsTask.onerror = function() {
console.log('发生错误...')
}
WebSocket连接建立后,需要按照协议发送不同状态的数据帧:
-
第0帧:初始化参数,包含appid、语言配置等
-
第1帧:中间语音数据帧,实时传输录音数据
-
第2帧:结束帧,通知服务器语音结束
2.4 语音数据处理
录音数据通过onFrameRecorded事件处理:
recorder.onFrameRecorded = ({isLastFrame, frameBuffer}) => {
if (!isLastFrame && wsFlag) {
// 发送中间帧
const params = {
data: {
status: 1,
format: "audio/L16;rate=16000",
encoding: "raw",
audio: toBase64(frameBuffer),
},
};
wsTask.send(JSON.stringify(params))
} else {
// 发送最后一帧
const params = {
data: {
status: 2,
format: "audio/L16;rate=16000",
encoding: "raw",
audio: "",
},
};
wsTask.send(JSON.stringify(params))
}
}
音频数据需要转换为Base64格式传输,转换函数如下:
function toBase64(buffer) {
let binary = "";
let bytes = new Uint8Array(buffer);
let len = bytes.byteLength;
for (let i = 0; i < len; i++) {
binary += String.fromCharCode(bytes\[i\]);
}
return window.btoa(binary);
}
2.5 鉴权与安全
与科大讯飞API的通信需要严格的鉴权,采用HMAC-SHA256算法:
getWebSocketUrl() {
return new Promise((resolve, reject) => {
var url = this.URL;
var host = this.URL.host;
var apiKeyName = "api\_key";
var date = new Date().toGMTString();
var algorithm = "hmac-sha256";
var headers = "host date request-line";
var signatureOrigin = \`host: ${host}\\ndate: ${date}\\nGET /v2/iat HTTP/1.1\`;
var signatureSha = CryptoJS.HmacSHA256(signatureOrigin, atob(this.user.apisecret));
var signature = CryptoJS.enc.Base64.stringify(signatureSha);
var authorizationOrigin =
\`${apiKeyName}="${atob(this.user.apikey)}", algorithm="${algorithm}", headers="${headers}", signature="${signature}"\`;
var authorization = base64.encode(authorizationOrigin);
url = \`${url}?authorization=${authorization}&date=${encodeURI(date)}&host=${host}\`;
resolve(url);
});
}
三、关键技术点详解
3.1 实时语音处理流程
-
语音采集:通过浏览器API获取麦克风权限并录制音频
-
分帧处理:将连续的语音流分割为小的音频帧
-
实时传输:通过WebSocket将音频帧实时发送到服务器
-
结果接收:异步接收服务器返回的识别结果
-
结果展示:动态更新界面显示识别文字
3.2 语音识别结果处理
服务器返回的识别结果采用增量返回方式,需要特殊处理:
if (jsonData.data && jsonData.data.result) {
let data = jsonData.data.result;
let str = "";
let ws = data.ws;
for (let i = 0; i < ws.length; i++) {
str = str + ws\[i\].cw\[0\].w;
}
if (data.pgs) {
if (data.pgs === "apd") {
\_this.resultText = \_this.resultTextTemp;
}
\_this.resultTextTemp = \_this.resultText + str;
} else {
\_this.resultText = \_this.resultText + str;
}
\_this.text = \_this.resultTextTemp || \_this.resultText || "";
}
-
pgs字段:表示识别结果的进度状态
-
apd值:表示追加模式,需要合并临时结果和最终结果
-
ws数组:包含识别的词语信息
3.3 自动停止机制
系统实现了两种停止识别的方式:
-
手动停止:用户点击停止按钮
-
自动停止:检测到用户2秒没有说话自动停止
if (jsonData.code === 0 && jsonData.data.status === 2) {
recorder.stop();
\_this.$message.success("检测到您2秒没说话,自动结束识别!")
wsTask.close();
wsFlag = false
}
自动停止通过服务器的vad_eos参数控制,设置为2000毫秒。
四、性能优化与注意事项
4.1 性能优化点
-
音频压缩:采用16kHz采样率和raw格式减少数据量
-
帧大小优化:1280字节的帧大小平衡了实时性和性能
-
增量更新:只更新变化的文本部分,减少DOM操作
-
连接复用:保持WebSocket连接而不是每次重新建立
4.2 常见问题与解决方案
-
跨浏览器兼容性:
-
使用特性检测判断浏览器是否支持WebSocket
-
提供备选方案或错误提示
-
-
麦克风权限问题:
-
明确提示用户授权麦克风
-
处理权限被拒绝的情况
-
-
网络不稳定:
-
实现重连机制
-
缓存未发送的音频数据
-
-
识别准确率:
-
优化录音参数
-
添加降噪处理
-
提供纠错接口
-
五、扩展与改进方向
5.1 功能扩展
-
多语言支持:扩展支持英语、日语等其他语言识别
-
语音命令:实现基于语音的交互命令
-
语音合成:增加文字转语音功能实现双向交互
-
离线识别:集成本地识别引擎减少网络依赖
5.2 技术改进
-
WebAssembly加速:使用WASM提高音频处理效率
-
Web Worker:将音频处理放入Worker线程避免阻塞UI
-
自适应码率:根据网络状况动态调整音频质量
-
更高效的编码:考虑使用opus等更高效的音频编码格式
六、总结
本文详细介绍了基于WebSocket的实时语音转文字前端实现方案。通过整合Recorder.js录音库、WebSocket实时通信和科大讯飞语音识别API,构建了一个高效、实时的语音识别应用。关键点包括:
-
完整的语音采集、传输、识别流程
-
实时增量结果显示处理
-
安全的API鉴权机制
-
自动与手动停止机制
-
性能优化与错误处理
该方案可以广泛应用于在线教育、语音笔记、实时字幕等多种场景,为人机交互提供了更加自然的方式。随着Web技术的不断发展,前端语音识别能力将会变得更加强大和普及。
2025开年,AI技术打得火热,正在改变前端人的职业命运:
阿里云核心业务全部接入Agent体系;
字节跳动30%前端岗位要求大模型开发能力;
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
大模型正在重构技术开发范式,传统CRUD开发模式正在被AI原生应用取代!
最残忍的是,业务面临转型,领导要求用RAG优化知识库检索,你不会;带AI团队,微调大模型要准备多少数据,你不懂;想转型大模型应用开发工程师等相关岗,没项目实操经验……这不是技术焦虑,而是职业生存危机!
曾经React、Vue等热门的开发框架,已不再是就业的金钥匙。如果认为会调用API就是懂大模型、能进行二次开发,那就大错特错了。制造、医疗、金融等各行业都在加速AI应用落地,未来企业更看重能用AI大模型技术重构业务流的技术人。
如今技术圈降薪裁员频频爆发,传统岗位大批缩水,相反AI相关技术岗疯狂扩招,薪资逆势上涨150%,大厂老板们甚至开出70-100W年薪,挖掘AI大模型人才!
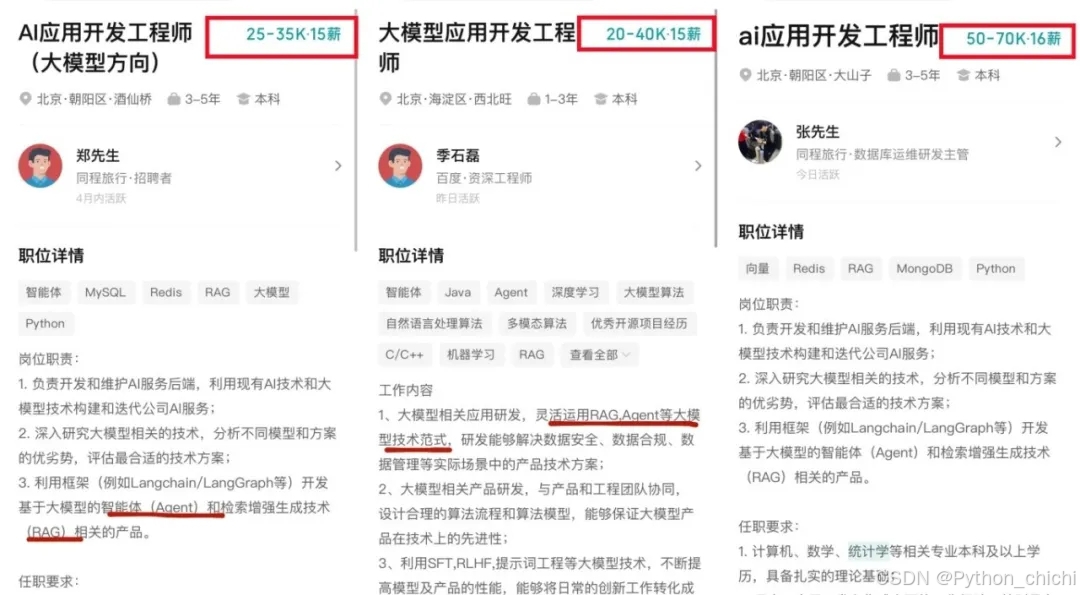
不出1年 “有AI项目开发经验”或将成为前端人投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 2561
2561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









