







文章目录
-
- 概要
- 整体架构流程
- 具体实现
-
- 一,分片下载之本地储存(localForage)
- 前言:
- 二,本地数据获取(获取下载列表)
- 二,操作JS
-
- 1,下载进度监听
- 2,文件下载状态控制
- 3,分片下载
- 二,VUE页面
- 小结
概要
本文从前端方面出发实现浏览器下载大文件的功能。不考虑网络异常、关闭网页等原因造成传输中断的情况。分片下载采用串行方式(并行下载需要对切片计算hash,比对hash,丢失重传,合并chunks的时候需要按顺序合并等,很麻烦。对传输速度有追求的,并且在带宽允许的情况下可以做并行分片下载)
整体架构流程
1, 使用分片下载: 将大文件分割成多个小块进行下载,可以降低内存占用和网络传输中断的风险。这样可以避免一次性下载整个大文件造成的性能问题。
2, 断点续传: 实现断点续传功能,即在下载中途中断后,可以从已下载的部分继续下载,而不需要重新下载整个文件。
3, 进度条显示: 在页面上展示下载进度,让用户清晰地看到文件下载的进度。如果一次全部下载可以从process中直接拿到参数计算得出(很精细),如果是分片下载,也是计算已下载的和总大小,只不过已下载的会成片成片的增加(不是很精细)。
4, 取消下载和暂停下载功能: 提供取消下载和暂停下载的按钮,让用户可以根据需要中止或暂停下载过程。
5, 合并文件: 下载完成后,将所有分片文件合并成一个完整的文件。
具体实现
一,分片下载之本地储存(localForage)
前言:
浏览器的安全策略禁止网页(JS)直接访问和操作用户计算机上的文件系统。
在分片下载过程中,每个下载的文件块(chunk)都需要在客户端进行缓存或存储,方便实现断点续传功能,同时也方便后续将这些文件块合并成完整的文件。这些文件块可以暂时保存在内存中或者存储在客户端的本地存储(如 IndexedDB、LocalStorage 等)中。
使用封装,直接上代码:
import axios from 'axios';
import ElementUI from 'element-ui'
import Vue from 'vue'
import localForage from 'localforage'
import streamSaver from 'streamsaver';
import store from "@/store/index"
/**
* localforage–是一个高效而强大的离线存储方案。
* 它封装了IndexedDB, WebSQL, or localStorage,并且提供了一个简化的类似localStorage的API。
* 在默认情况下会优先采用使用IndexDB、WebSQL、localStorage进行后台存储,
* 即浏览器不支持IndexDB时尝试采用WebSQL,既不支持IndexDB又不支持WebSQL时采用
* localStorage来进行存储。
*
*/
/**
* @description 创建数据库实例,创建并返回一个 localForage 的新实例。每个实例对象都有独立的数据库,而不会影响到其他实例
* @param {Object} dataBase 数据库名
* @return {Object} storeName 实例(仓库实例)
*/
function createInstance(dataBase){
return localForage.createInstance({
name: dataBase
});
}
/**
* @description 保存数据
* @param {Object} name 键名
* @param {Object} value 数据
* @param {Object} storeName 仓库
*/
async function saveData(name, value, storeName){
await storeName.setItem(name, value).then(() => {
// 当值被存储后,可执行其他操作
console.log("save success");
}).catch(err => {
// 当出错时,此处代码运行
console.log(err)
})
}
/**
* @description 获取保存的数据
* @param {Object} name 键名
* @param {Object} storeName 仓库
*/
async function getData(name, storeName, callback){
await storeName.getItem(name).then((val) => {
// 获取到值后,可执行其他操作
callback(val);
}).catch(err => {
// 当出错时,此处代码运行
callback(false);
})
}
/**
* @description 移除保存的数据
* @param {Object} name 键名
* @param {Object} storeName 仓库
*/
async function removeData(name, storeName){
await storeName.removeItem(name).then(() => {
console.log('Key is cleared!');
}).catch(err => {
// 当出错时,此处代码运行
console.log(err);
})
}
/**
* @description 删除数据仓库,将删除指定的 “数据库”(及其所有数据仓库)。
* @param {Object} dataBase 数据库名
*/
async function dropDataBase(dataBase){
await localForage.dropInstance({
name: dataBase
}).then(() => {
console.log('Dropped ' + dataBase + ' database');
}).catch(err => {
// 当出错时,此处代码运行
console.log(err);
})
}
/**
* @description 删除数据仓库
* @param {Object} dataBase 数据库名
* @param {Object} storeName 仓库名(实例)
*/
async function dropDataBaseNew(dataBase, storeName){
await localForage.dropInstance({
name: dataBase,
storeName: storeName
}).then(() => {
console.log('Dropped',storeName)
}).catch(err => {
// 当出错时,此处代码运行
console.log(err);
})
}
二,本地数据获取(获取下载列表)
/**
* @description 获取下载列表
* @param {String} page 页面
* @param {String} user 用户
*/
export async function getDownloadList(page, user, callback){
// const key = user + "_" + page + "_";
// const key = user + "_";
const key = "_"; // 因为用户会过期 所以不保存用户名 直接以页面为键即可
// 基础数据库
const baseDataBase = createInstance(baseDataBaseName);
await baseDataBase.keys().then(async function(keys) {
// 包含所有 key 名的数组
let fileList = [];
for(let i = 0; i < keys.length; i++){
if(keys[i].indexOf(key)>-1){
// 获取数据
await getData(keys[i], baseDataBase, async (res) =>{
fileList.push(
{
'fileName': res, // 文件名
'dataInstance': keys[i] // 文件对应数据库实例名
}
);
})
}
}
// 获取进度
for(let i = 0; i < fileList.length; i++){
const dataBase = createInstance(fileList[i].dataInstance);
await getData(progressKey, dataBase, async (progress) => {
if(progress){
fileList[i].fileSize = progress.fileSize;
fileList[i].progress = progress.progress ? progress.progress : 0;
fileList[i].status = progress.status ? progress.status : "stopped";
fileList[i].url = progress.url;
}
});
}
callback(fileList);
}).catch(function(err) {
// 当出错时,此处代码运行
callback(err);
});
}
二,操作JS
1,下载进度监听
/**
* 文件下载进度监听
*/
const onDownloadProgres = (progress) =>{
// progress对象中的loaded表示已经下载的数量,total表示总数量,这里计算出百分比
let downProgress = Math.round(100 * progress.loaded / progress.total);
store.commit('setProgress', {
dataInstance: uniSign,
fileName: data.downLoad,
progress: downProgress,
status: downProgress == 100 ? 'success' : 'downloading',
cancel: cancel
})
}
2,文件下载状态控制
// 数据库进度数据主键
const progressKey = "progress";
/**
* @description 状态控制
* @param {String} fileName 文件名
* @param {String} type 下载方式 continue:续传 again:重新下载 cancel:取消
* @param {String} dataBaseName 数据库名 每个文件唯一
*
*/
async function controlFile(fileName, type, dataBaseName){
if(type == 'continue'){
} else if(type == 'again'){
// 删除文件数据
await dropDataBase(dataBaseName);
// 基础数据库
const baseDataBase = createInstance(baseDataBaseName);
// 基础数据库删除数据库实例
removeData(dataBaseName, baseDataBase);
} else if(type == 'cancel'){
// 删除文件数据
await dropDataBase(dataBaseName);
// 基础数据库
const baseDataBase = createInstance(baseDataBaseName);
// 基础数据库删除数据库实例
await removeData(dataBaseName, baseDataBase);
store.commit('delProgress', {
dataInstance: dataBaseName
})
} else if(type == 'stop'){
store.commit('setProgress', {
dataInstance: dataBaseName,
status: 'stopped',
})
}
}
3,分片下载
/**
* @description 分片下载
* @param {String} fileName 文件名
* @param {String} url 下载地址
* @param {String} dataBaseName 数据库名 每个文件唯一
* @param {Object} progress 下载进度 type: continue:续传 again:重新下载 cancel:取消
*
*/
export async function downloadByBlock(fileName, url, dataBaseName, progress) {
//调整下载状态
if(progress.type){
await controlFile(fileName, progress.type, dataBaseName);
}
// 判断是否超过最大下载数量
let downloadNum = store.state.progressList;
if(downloadNum){
if(!progress.type && downloadNum.length == downloadMaxNum){
ElementUI.Message.error("已超过最大下载量,请等待其他文件下载完再尝试!");
return;
}
}
// 基础数据库
const baseDataBase = createInstance(baseDataBaseName);
// 判断数据库中是否已存在该文件的下载任务
let isError = false;
await getData(dataBaseName, baseDataBase, async (res) =>{
if(res && !progress.type){
ElementUI.Message.error("该文件已在下载任务列表,无需重新下载!");
isError = true;
}
});
if(isError){
return;
}
// 储存数据的数据库
const dataBase = createInstance(dataBaseName);
// 获取文件大小
const response = await axios.head(url);
// 文件大小
const fileSize = +response.headers['content-length'];
// 分片大小
const chunkSize = +response.headers['buffer-size'];
// 开始节点
let start = 0;
// 结束节点
let end = chunkSize - 1;
if (fileSize < chunkSize) {
end = fileSize - 1;
}
// 所有分片
let ranges = [];
// 计算需要分多少次下载
const numChunks = Math.ceil(fileSize / chunkSize);
// 回写文件大小
progress.fileSize = fileSize;
progress.url = url;
// 保存数据库实例
await saveData(dataBaseName, fileName, baseDataBase);
if(!progress.progress){
// 保存进度数据
await saveData(progressKey, progress, dataBase);
}
// 保存下载状态至localstorage 如果页面刷新 可重新读取状态 判断是否需要继续下载
sessionStorage.setItem(dataBaseName,"downloading");
// 组转参数
for (let i = 0; i < numChunks; i++) {
// 创建请求控制器
const controller = new AbortController();
const range = `bytes=${start}-${end}`;
// 如果是续传 先判断是否已下载
if(progress.type == 'continue'){
// 先修改状态
store.commit('setProgress', {
dataInstance: dataBaseName,
status: 'downloading'
})
let isContinue = false;
await getData(range, dataBase, async function(res){ if(res) isContinue = true});
if(isContinue){
ranges.push(range);
// 重置开始节点
start = end + 1;
// 重置结束节点
end = Math.min(end + chunkSize, fileSize - 1);
continue;
}
}
let cancel;
const config = {
headers: {
Range: range
},
responseType: 'arraybuffer',
// 绑定取消请求的信号量
signal: controller.signal,
// 文件下载进度监听
onDownloadProgress: function (pro){
if(progress.type == 'stop' || progress.type == 'cancel'){
// 终止请求
controller.abort();
}
// 已加载大小
// progress对象中的loaded表示已经下载的数量,total表示总数量,这里计算出百分比
let downProgress = (pro.loaded / pro.total);
downProgress = Math.round( (i / numChunks) * 100 + downProgress / numChunks * 100);
progress.progress = downProgress;
// 设置为异常 如果是正常下载完 这个记录会被删除 如果合并失败 则会显示异常
progress.status = downProgress == 100 ? 'error' : 'stopped';
store.commit('setProgress', {
dataInstance: dataBaseName,
fileName: fileName,
progress: downProgress,
status: 'downloading',
cancel: cancel,
url: url,
dataBaseName: dataBaseName
})
}
};
try {
// 开始分片下载
const response = await axios.get(url, config);
// 保存分片数据
await saveData(range, response.data, dataBase);
ranges.push(range);
// 重置开始节点
start = end + 1;
// 重置结束节点
end = Math.min(end + chunkSize, fileSize - 1);
} catch (error) {
console.log("终止请求时catch的error---", error);
// 判断是否为取消上传
if (error.message == "canceled"){
// 进行后续处理
if(progress.type == 'stop'){
// 暂停
await controlFile(fileName, progress.type, dataBaseName);
sessionStorage.setItem(dataBaseName,"stop");
// 终止请求
console.log("stopped");
return;
} else if(progress.type == 'cancel'){
// 取消
await controlFile(fileName, progress.type, dataBaseName);
sessionStorage.removeItem(dataBaseName);
// 终止请求
console.log("canceled");
return;
}
};
}
}
console.log("开始合入");
// 流操作
const fileStream = streamSaver.createWriteStream(fileName, {size: fileSize});
const writer = fileStream.getWriter();
// 合并数据
// 循环取出数据合并
for (let i=0; i < ranges.length; i++) {
var range = ranges[i];
// 从数据库获取分段数据
await getData(range, dataBase, async function(res){
if(res){
// 读取流
const reader = new Blob([res]).stream().getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 写入流
writer.write(value)
}
// 结束写入
if(i==ranges.length-1){
writer.close();
// 清空数据库
dropDataBase(dataBaseName);
// 基础数据库删除数据库实例
removeData(dataBaseName, baseDataBase);
// 清除store
store.commit('delProgress', {
dataInstance: dataBaseName
})
}
}
});
}
}
二,VUE页面
<script>
import { downloadByBlock } from "上面的js";
export default {
name: "suspension",
data() {
return {
// 下载列表
downloadDialog: false,
fileStatus: {}
};
},
watch: {
"$store.state.progressList": function() {
this.$nextTick(function() {
let progressList = this.$store.state.progressList;
progressList.forEach(item => {
// 获取之前下载状态 还原操作
const status = sessionStorage.getItem(item.dataInstance);
if (status == "downloading" && item.status != status) {
this.startDownload(item);
}
});
});
}
},
methods: {
/**
* @description 重试
* @param {Object} row
*/
retryDownload(row) {
this.startDownload(row);
},
/**
* @description 开始下载
* @param {Object} row
*/
startDownload(row) {
this.fileStatus[row.dataInstance] = {
type: "continue",
progress: row.progress
};
downloadByBlock(
row.fileName,
row.url,
row.dataInstance,
this.fileStatus[row.dataInstance]
);
},
/**
* @description 暂停下载
* @param {Object} row
*/
stopDownload(row) {
this.$set(this.fileStatus[row.dataInstance], "type", "stop");
},
/**
* @description 删除下载
* @param {Object} row
*/
delDownload(row) {
if (this.fileStatus[row.dataInstance] && row.status != "stopped") {
this.$set(this.fileStatus[row.dataInstance], "type", "cancel");
} else {
this.fileStatus[row.dataInstance] = { type: "cancel" };
downloadByBlock(
row.fileName,
row.url,
row.dataInstance,
this.fileStatus[row.dataInstance]
);
}
},
/**
* @description 分片下载文件
*/
downloadByBlock(fileName, url, dataBaseName, type) {
this.fileStatus[dataBaseName] = { type: type };
downloadByBlock(
fileName,
url,
dataBaseName,
this.fileStatus[dataBaseName]
);
this.btnDownload();
},
/**
* @description 下载列表
*/
btnDownload() {
// 通过路由信息判断当前处于哪一个页面
const page = this.$route.name;
this.downloadDialog = true;
},
/**
* @description 取消弹窗
*/
downloadBtnCancel() {
this.downloadDialog = false;
}
}
};
</script>
小结
这只是一个基本示例。在实际应用中,你可能需要考虑以下问题:
并发下载: 如果多个用户同时下载相同的大文件,可能会对服务器造成很大的压力。可以使用并发下载来提高性能。
安全性: 确保只有授权用户可以下载文件,并且不会泄漏敏感信息。
性能优化: 使用缓存、压缩等技术来提高下载速度和用户体验。
服务器资源管理: 下载大文件可能会占用服务器的网络带宽和内存资源,需要适当的管理。
总之,大文件分片下载和合并是一个复杂的任务,需要综合考虑性能、安全性和用户体验。在实际项目中,你可能会使用更高级的工具和技术来处理这些问题。
2025开年,AI技术打得火热,正在改变前端人的职业命运:
阿里云核心业务全部接入Agent体系;
字节跳动30%前端岗位要求大模型开发能力;
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
大模型正在重构技术开发范式,传统CRUD开发模式正在被AI原生应用取代!
最残忍的是,业务面临转型,领导要求用RAG优化知识库检索,你不会;带AI团队,微调大模型要准备多少数据,你不懂;想转型大模型应用开发工程师等相关岗,没项目实操经验……这不是技术焦虑,而是职业生存危机!
曾经React、Vue等热门的开发框架,已不再是就业的金钥匙。如果认为会调用API就是懂大模型、能进行二次开发,那就大错特错了。制造、医疗、金融等各行业都在加速AI应用落地,未来企业更看重能用AI大模型技术重构业务流的技术人。
如今技术圈降薪裁员频频爆发,传统岗位大批缩水,相反AI相关技术岗疯狂扩招,薪资逆势上涨150%,大厂老板们甚至开出70-100W年薪,挖掘AI大模型人才!
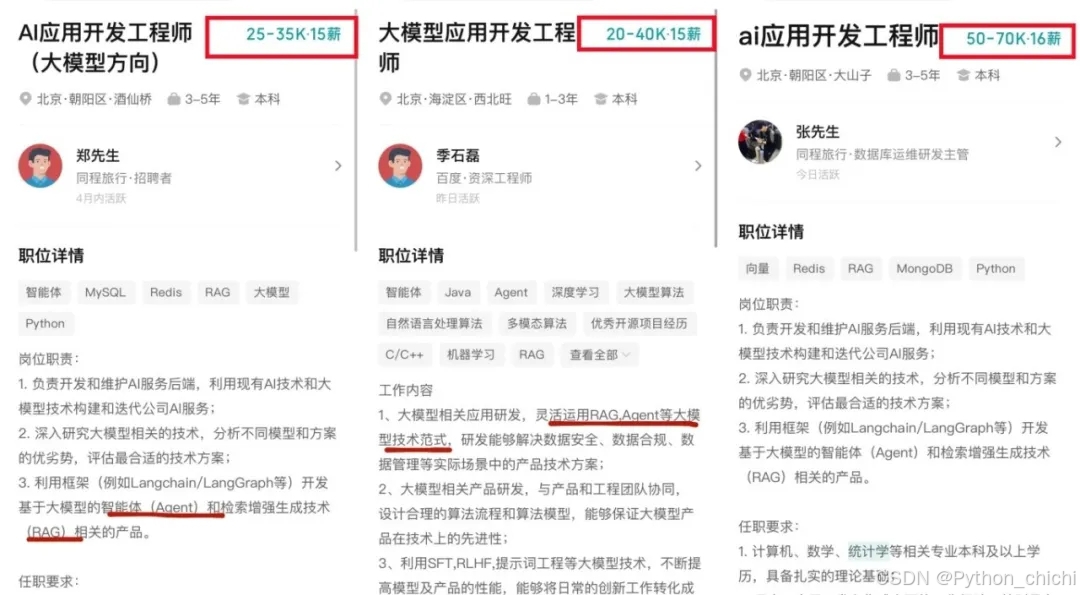
不出1年 “有AI项目开发经验”或将成为前端人投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
2025最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









