







 Pandas是Python中的核心数据分析库,提供高性能、易用的数据结构如Series和DataFrame。Series是一维数组,可存储各种类型数据,并通过index和value获取索引和值。DataFrame是二维表格型数据结构,具有行和列索引,可以由字典、Series或2D-Numpy数组创建。通过列索引或ix可方便地访问数据。
Pandas是Python中的核心数据分析库,提供高性能、易用的数据结构如Series和DataFrame。Series是一维数组,可存储各种类型数据,并通过index和value获取索引和值。DataFrame是二维表格型数据结构,具有行和列索引,可以由字典、Series或2D-Numpy数组创建。通过列索引或ix可方便地访问数据。
Padas是用于数据分析的最流行的python库。它提供了高度优化的性能,后端源代码纯粹是用C或Python。可以用来分析:Series、DataFrames。
Series系列是在熊猫中定义的一维(1-D)数组,可用于存储任何数据类型。
代码1:创作系列
# Program to create series
# Import Panda Library
import pandas as pd
# Create series with Data, and Index
a = pd.Series(Data, index = Index)
- 标量值可以是整值、字符串
- Python字典可以是键,值对
- Ndarray
可以通过Series的两个属性,index 和 value 来分别获取索引和值
obj.index
Out[5]: RangeIndex(start=0, stop=4, step=1)
obj.values
Out[7]: array([2, 9, 5, 6], dtype=int64)
代码2:当数据包含标量值时
# Program to Create series with scalar values
# Numeric data
Data =[1, 3, 4, 5, 6, 2, 9]
# Creating series with default index values
s = pd.Series(Data)
# predefined index values
Index =['a', 'b', 'c', 'd', 'e', 'f', 'g']
# Creating series with predefined index values
si = pd.Series(Data, Index)
输出量:

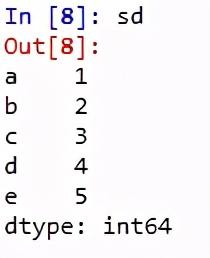
代码3:当数据包含字典时
# Program to Create Dictionary series
dictionary ={'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
# Creating series of Dictionary type
sd = pd.Series(dictionary)
输出量:
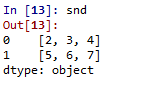
代码4:当数据包含Ndarray时
# Program to Create ndarray series
# Defining 2darray
Data =[[2, 3, 4], [5, 6, 7]]
# Creating series of 2darray
snd = pd.Series(Data)
输出量:
Series 索引的 name 和 值的 name(相当于这两个向量的名字)
obj3.name
obj3.name="population"
obj3.index.name="ind"
obj3
Out[23]:
ind
b 2.0
a 1.0
d NaN
Name: population, dtype: float64
DataFrames:
DataFrames是在熊猫中定义的由行和列组成的二维(2-D)数据结构。是一个典型的表格型数据,既有行索引,又有列索引。相当于一个大字典,字典的键是列索引,字典的值是一个Series; 构成这些索引的每一个值的Series都是共用一个 Series 索引的。
代码1:创建DataFrame
# Program to Create DataFrame
# Import Library
import pandas as pd
# Create DataFrame with Data
a = pd.DataFrame(Data)
在这里,数据可以是:
- 一个或多个字典
- 一个或多个系列
- 2D-Numpy Ndarray
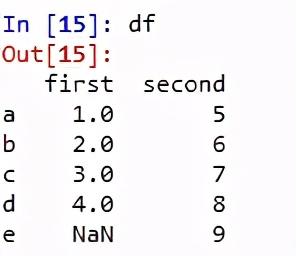
代码2:当数据是字典时
# Program to Create Data Frame with two dictionaries
# Define Dictionary 1
dict1 ={'a':1, 'b':2, 'c':3, 'd':4}
# Define Dictionary 2
dict2 ={'a':5, 'b':6, 'c':7, 'd':8, 'e':9}
# Define Data with dict1 and dict2
Data = {'first':dict1, 'second':dict2}
# Create DataFrame
df = pd.DataFrame(Data)
输出量:
DataFrame 默认通过 列索引获取一个series;(在series中默认通过索引获取一个值)
df["popular"] 或者 df.popular
Out[37]:
0 8
1 9
2 10
3 11
Name: popular, dtype: int64
代码3:当数据是序列时
# Program to create Dataframe of three series
import pandas as pd
# Define series 1
s1 = pd.Series([1, 3, 4, 5, 6, 2, 9])
# Define series 2
s2 = pd.Series([1.1, 3.5, 4.7, 5.8, 2.9, 9.3])
# Define series 3
s3 = pd.Series(['a', 'b', 'c', 'd', 'e'])
# Define Data
Data ={'first':s1, 'second':s2, 'third':s3}
# Create DataFrame
dfseries = pd.DataFrame(Data)
输出量:

DataFrame 通过 ix 间接获取行向量,行向量也是一个series,它的索引是原来DF的列索引。
df.loc[2]
Out[40]:
cities bj
year 2003
popular 10
Name: 2, dtype: object
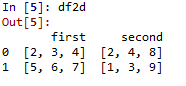
代码4:当数据为2D-numpy ndarray时
注:在创建2D数组的DataFrame时,必须维护一个约束--2D数组的维数必须相同。
# Program to create DataFrame from 2D array
# Import Library
import pandas as pd
# Define 2d array 1
d1 =[[2, 3, 4], [5, 6, 7]]
# Define 2d array 2
d2 =[[2, 4, 8], [1, 3, 9]]
# Define Data
Data ={'first': d1, 'second': d2}
# Create DataFrame
df2d = pd.DataFrame(Data)
输出量:

















 3975
3975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









