






 本文深入解析HDFS(Hadoop分布式文件系统)的架构、原理及操作方法。涵盖HDFS的演变历史,从谷歌GFS论文的启发到其独特的主从架构,包括NameNode和DataNode的角色与职责。详细介绍了HDFS的特点,如高容错性、流式数据访问和对超大文件的支持,同时也讨论了其局限性。此外,还提供了HDFS的Shell和Java API操作指南,包括文件的上传、下载、目录管理等实用技巧。
本文深入解析HDFS(Hadoop分布式文件系统)的架构、原理及操作方法。涵盖HDFS的演变历史,从谷歌GFS论文的启发到其独特的主从架构,包括NameNode和DataNode的角色与职责。详细介绍了HDFS的特点,如高容错性、流式数据访问和对超大文件的支持,同时也讨论了其局限性。此外,还提供了HDFS的Shell和Java API操作指南,包括文件的上传、下载、目录管理等实用技巧。
HDFS的介绍
HDFS演变
- 源于谷歌GFS论文
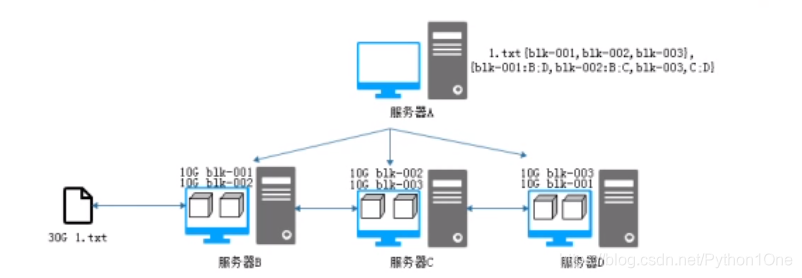
DataNode(服务器A)存储文件的分割信息,文件和目录信息。DataNode(服务器B。C。D)存储分布式文件,并且备份在不同的服务器上。
HDFS基本概念
概念
是一个易于扩展分布式文件存储系统,运行在成百上千台低成本的机器上。用于海量文件信息进行存储和管理。解决TB,PB的存储问题
- NameNode(名称节点/主节点)
是hdfs集群的主节点,NameNode关闭就无法访问Hadoop集群。用来存储元数据(大小、文件名称、文件权限、切分次数(block)、block的存储位置) - DataNode(数据节点)
从节点,用来存切分后的数据(提供磁盘空间) - block(数据块)
文件的每个切片成为一个block,hadoop2.x默认128M大小,可以修改。 - Rack(机架)
(放服务器的机柜)
用来存放部署Hadoop集群服务器的机架,不同机架的节点通过交换机通讯。hdfs通过机架感知策略,使NameNode确定每个DataNode所属机架id,使用副本存放策略,来改进数据的可靠性、可用性和网络带宽的利用率 - metadata(元数据)
三种形式:- 维护HDFS文件系统中文件和目录的信息,如,文件名、目录名、父目录信息、文件大小、修改时间、创建时间等。
- 记录文件内容存储的相关信息,如,文件分块情况、副本个数、每个副本所在的DataNode信息。
- 记录HDFS中所有的DataNode信息,用于DataNode管理。
HDFS特点
优点
- 高容错:数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 流式数据访问:一次写入,多次读取。文件一旦写入不能修改,只能追加。它能保证数据的一致性。
- 支持超大文件:将大文件切分成小文件
- 高数据吞吐量:不支持随机修改,只支持追加修改
缺点
- 高延迟:数据多,需要切片,需要做副本
- 不适合小文件存取:一个文件就占150字节,会增加namenode压力
- 不适合并发写入
HDFS结构和原理
HDFS存储架构
- 采用主从架构(Master/Slave架构)
- HDFS集群是由一个NameNode和多个DataNode组成
- NameNode:存储元数据在内存中,fsimage和edits用来将元数据持久化(将内存中的元数据放到磁盘中)fsimage放到磁盘,edits从磁盘中取出到内存。
- DataNode每隔一段时间向NameNode发送心跳包来证明我还活着,若没有收到心跳包,NameNode认为DataNode宕机了就会检查副本文件完整性。集群继续正常工作。
HDFS文件读写原理
- HDFS写数据
- 客户端发出rpc,请求上传文件
- NN检查元数据的目录树(检查文件是否存在,存在不上传,不存在返回数据可以上传)
- NN告诉客户端可以上传
- 请求上传第一个block
- NN检查DN信息池(存储量),找出可用的DN。
- NN返回可用DN列表。
- 客户端和DN之间建立管道(Pipeline),各个DN之间都建立Pipeline。
- DN返回管道建立完毕信息
- 客户端和DN之间建立数据流开始发送数据
- 客户端以package(64k)为单位发送数据 ,DN之间也以package(64k)为单位发送数据。(没发送一次,DN之间也会互相发送)
- DN向前返回ACK确认信息(收到了)
- 通知客户端block发送完毕,请求发送下一个block,向上循环直到全部block发送完毕。
- HDFS读数据
- 客户端向NN发送RPC请求,获取文件每个block数据所在位置
- DN返回每个block的DN地址列表
- 客户端收到地址列表后,挑出排序靠前(离DN进的)
HDFS的Shell操作
hadoop fs <args>:可以操作任何人间系统如,本地文件系统,HDFS等
hadoop dfs <args>主要针对HDFS已被hdfs dfs代替
hdfs dfs <args>
| 参数名称 | 功能 |
|---|---|
| -ls | 查看指定目录结构 |
| -du | 统计目录下所有文件大小 |
| -mv | 移动 |
| -cp | 复制 |
| -put | 上传文件 |
| -cat | 查看文件内容 |
| -text | 将文件输出为文本格式 |
| -mkdir | 创建文件夹 |
| -help | 帮助 |
ls
hadoop fs -ls [-d] [-h] [-R] <args>
| 参数 | 说明 |
|---|---|
| [-d] | 将目录显示为普通文件 |
| [-h] | 人类可读的显示方式 |
| [-R]递归显示目录树 |
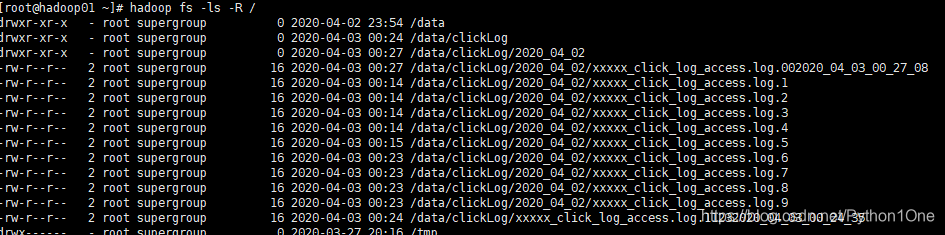
[root@hadoop01 ~]# hadoop fs -ls -R /
mkdir命令
hadoop fs -mkdir [-p] <路径>
| 参数 | 说明 |
|---|---|
| [-p] | 递归创建 |
put命令
hadoop fs -put [-f] [-p] <要上传的文件的路径> <上传位置>
| 参数 | 说明 |
|---|---|
| [-f] | 覆盖目标文件 |
| [-p] | 保留访问和修改时间、权限 |
案例–Shell定时采集数据到HDFS
- 在/export/data/logs下创建文件
# 配置环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_212
export HADOOP_HOME=/opt/hadoop
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 日志存放目录
log_src_dir=/export/data/logs/log/
# 待上传温江存放目录
log_toupload_dir=/export/data/logs/toupload/
# 设置日期
date1=`date -d last-day +%Y_%m_%d`
# 日志上传hdfs 的路径
hdfs_root_dir=/data/clickLog/$date1/
# 打印环境变量信息
echo "envs:hadoop_home:$HADOOP_HOME"
# 读取日志文件目录判断是否有上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]];then
date=`date +%Y_%m_%d_%H_%M_%S`
# 将文件移动到待上传目录并改名
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
# 将上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
# 找到列表文件
ls $log_toupload_dir | grep will | grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
# 打印信息
echo "toupload is in file:"$line
# 将上传文将列表改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
# 读取列表文件中的内容(待上传文件的path)
cat $log_toupload_dir$line"_COPY_" | while read line
do
echo "puting.......$line to hdfs path..........$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
定期执行:
0 0 * * * /shell/xxxxxx.sh
参数6个意义:分 时 。。。。执行xxxxx.sh
直接执行:
sh 程序名.sh
HDFS的Java API操作
下载winutils解压
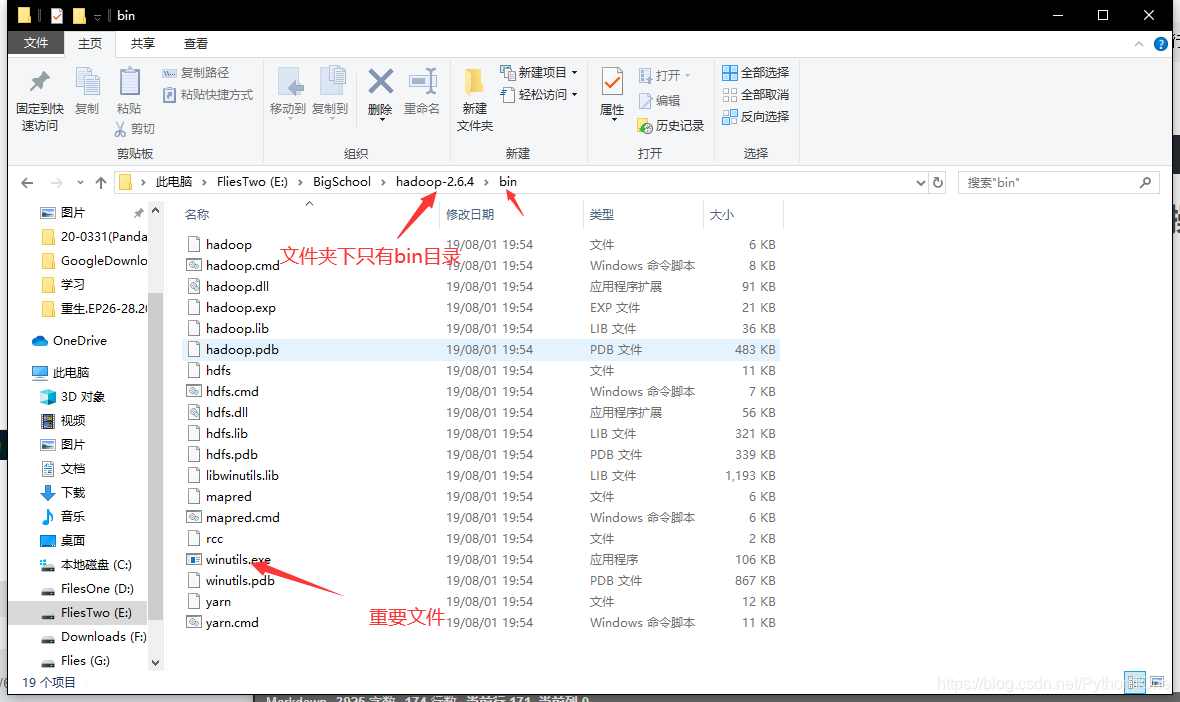
添加hadoop的win环境变量
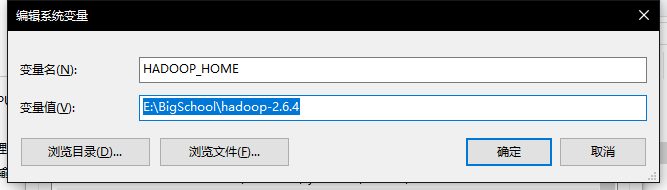
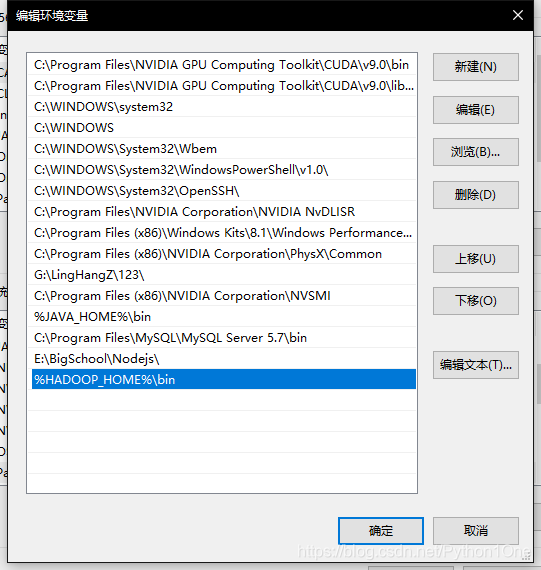
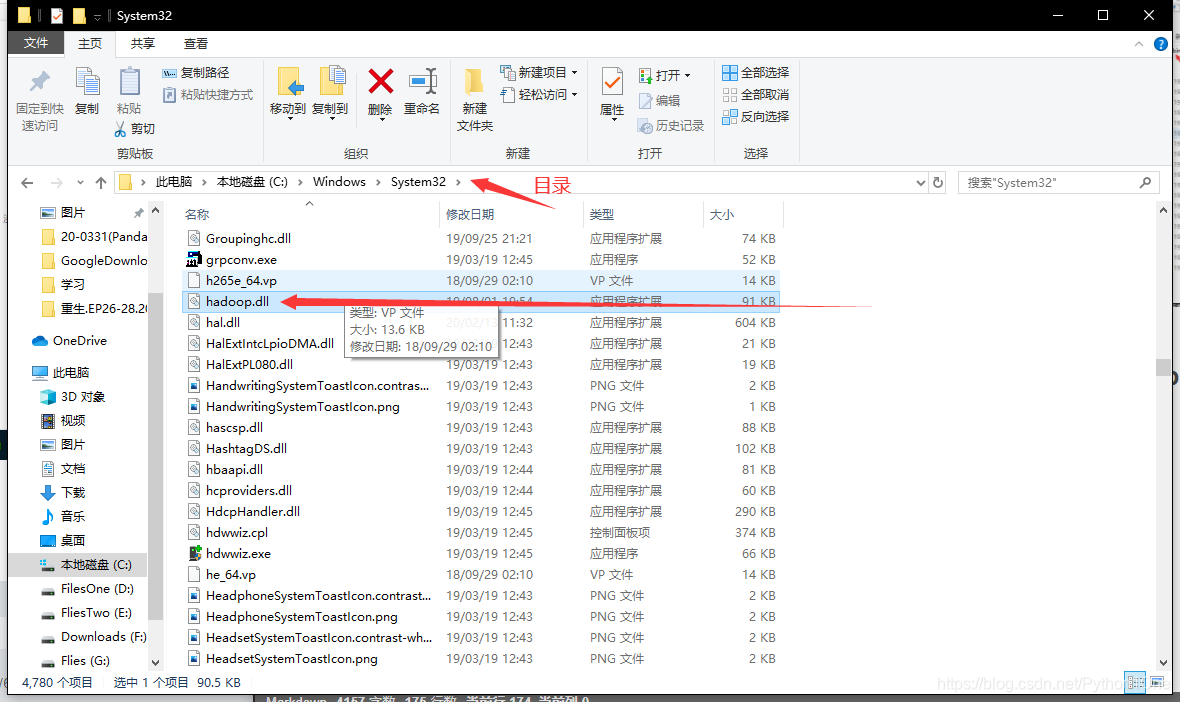
复制文件下的hadoop.dll到System32下
API概念
通过Windows的Java编程语句访问HDFS,对HDFS进行增删查改
API
| API | 说明 |
|---|---|
| org.apache.hadoop.fs.FileSystem | 表示文件系统是文件系统的基类,可以被分布式文件系统集成,有很对实现类 LocalFileSystem本地文件系统,DistributedFileSystem分布式文件系统,FtpFileSystemFTP文件系统 |
| fs.FileStatus | 向客户展示系统中文件和目录的元数据,如包含文件大小、块大小、副本信息、修改时间 |
| fs.FSDataInputStream | 文件输入流,用于读取Hadoop文件 |
| fs.FSDataOutputStream | 文件输出流,用于写hadoop 文件 |
| conf.Configuration | 访问配置项,默认在core-site-xml中,用户可以添加相应配置项 |
| fs.Path | 表示Hadoop文件系统中的一个文件或者一个目录的路径 |
在Java操作HDFS中,首先要创建一个客户端实例,主要涉及一下类
| 类名 | 说明 |
|---|---|
| Configuration | 封装了客户端或者服务器的配置。每一个配置都是以键值对存在, Configuration 会自动加载core-site-xml的HDFS配置文件 |
| FileSystem | 是一个文件系统的对象,可以对文件进行操作常用方法如下表 |
FileSystem中常用方法
| 方法名 | 说明 |
|---|---|
| copyFromLocalFile(Path src,Path dst) | 从本地磁盘复制文件到HDFS。src是本地文件目录+文件名,dst是HDFS的路径+重置文件名 |
| copyToLocalFile(Path src , Path dst) | 从HDFS复制文件到本地磁盘。src是HDFS文件目录+文件名,dst是本地的下载路径 |
| mkdirs(Path f) | 建立HDFS的子目录 |
| rename(Path src, Path dst) | 重命名文件或者文件夹,前者是要修改文件或者文件夹,后者是目标文件名或者文件夹名 |
| delete(Path f) | 删除指定文件 |
Hadoop API学习网址点击前往
API案例
搭建项目环境
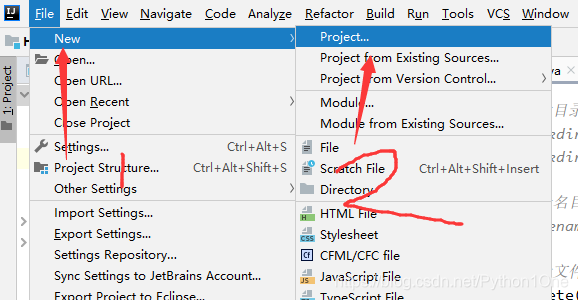
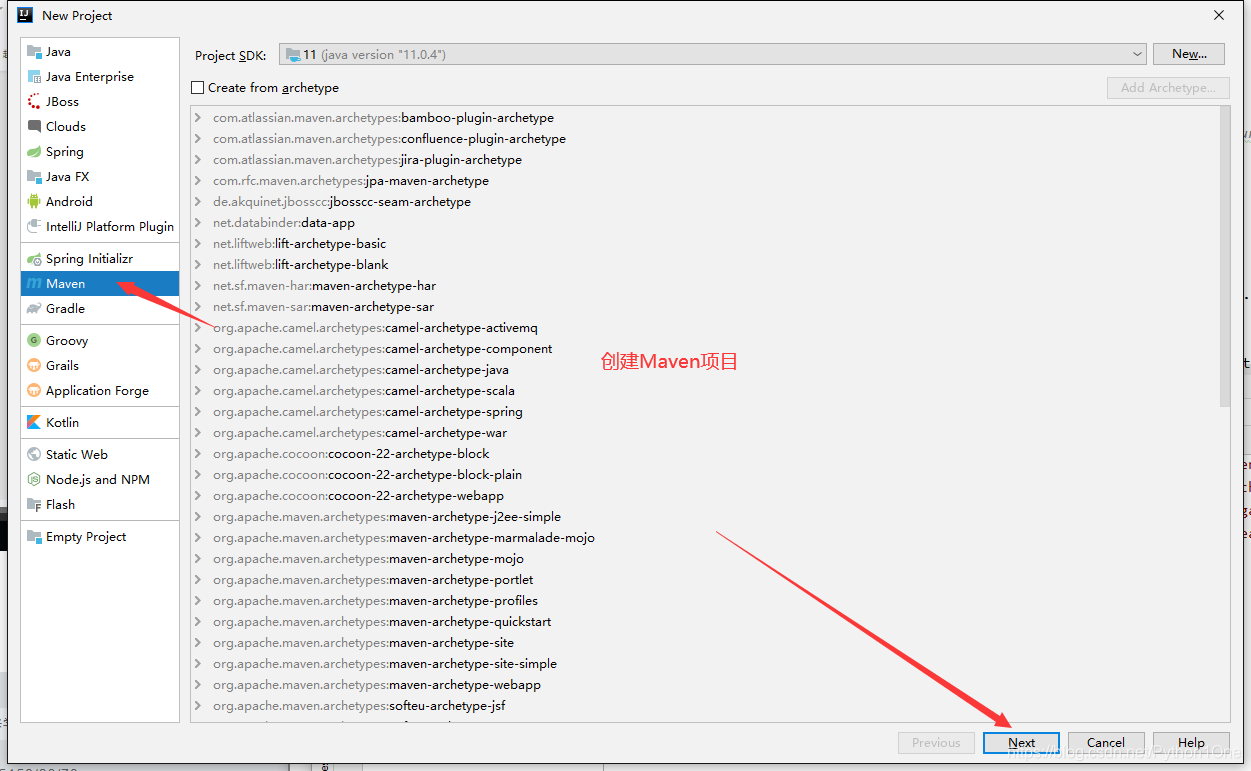
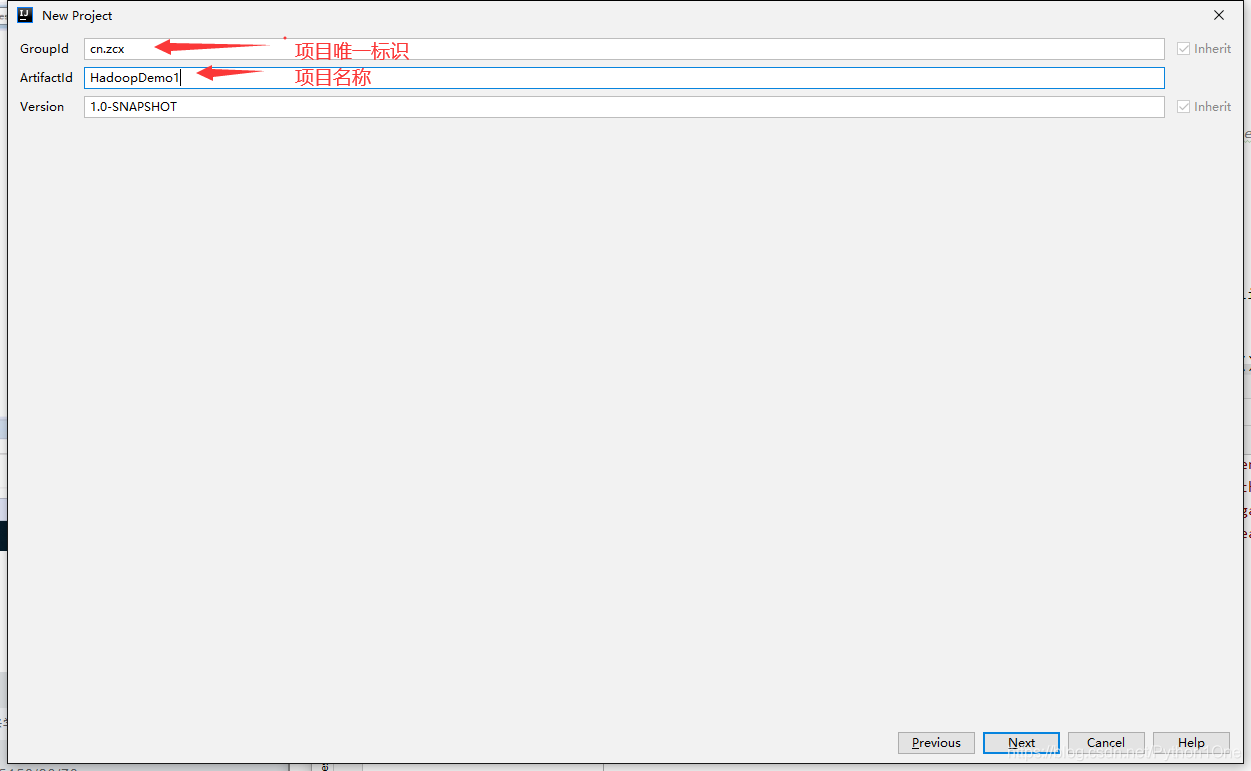
- 修改pom.xml文件
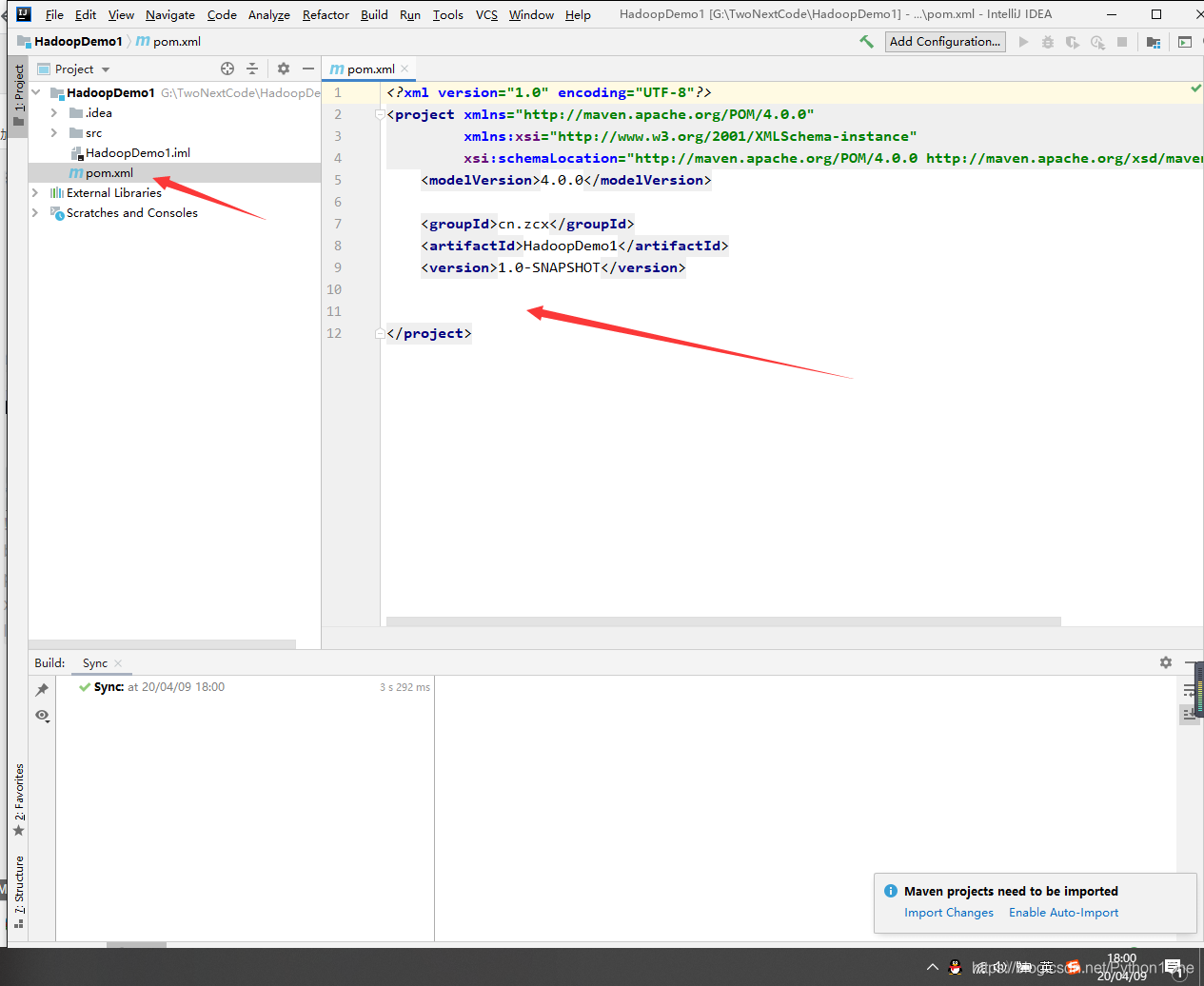
添加以下内容(保存后所需jar包会自动下载)
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
在src/main/java下创建包-类
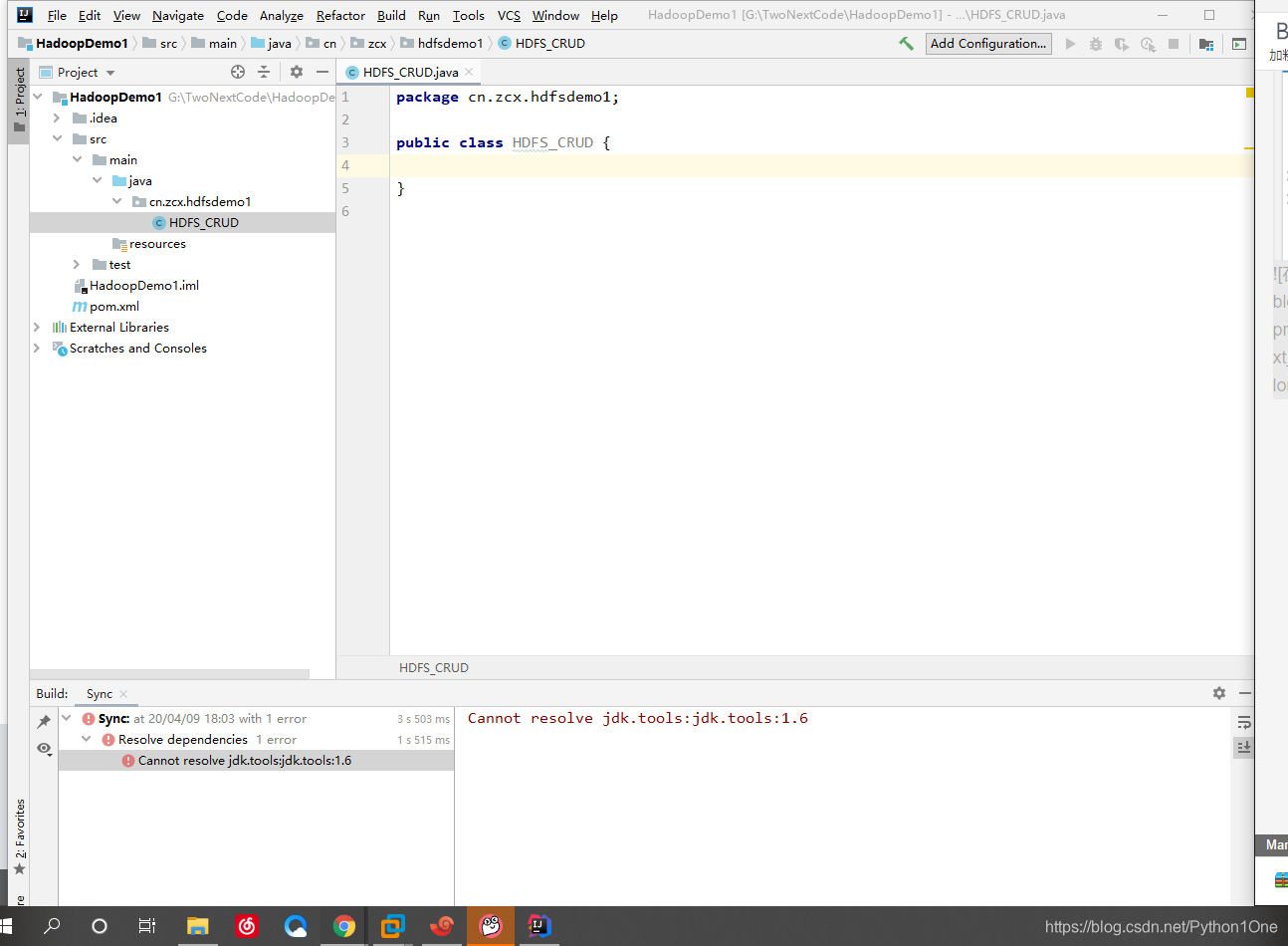
编写代码
- 获取fs操作对象
public class HDFS_CRUD {
FileSystem fs = null; // 定义全局变量fs操作对象
@Before // 表示下面的@Test执行之前先执行这个
public void init() throws IOException {
// 创建配置参数构造对象Configuration
Configuration conf = new Configuration();
// 设置参数指定文件系统类型
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 设置客户端的访问身份,root身份访问
System.setProperty("HADOOP_USER_NAME","root");
// 获取客户端对象
fs = FileSystem.get(conf);
}
.
.
.
.
}
- 传送本地文件到HDFS
// 传送本地文件到HDFS
@Test
public void testAddFileToHdfs() throws IOException {
// 创建本地路径Path对象
Path src = new Path("G:\\test.txt");
// 创建HDFS路径Path对象
Path dst = new Path("/user/root/testFile");
// 实现资源上传
fs.copyFromLocalFile(src,dst);
// 资源关闭
fs.close();
}
- 从HDFS下载文件到本地
@Test
public void testDownloadFileToLocal() throws IOException {
// 实现文件下载
fs.copyToLocalFile(new Path("/user/root/testFile"),
new Path("G:\\"));
fs.close();
}
- 创建删除重命名目录
@Test
public void testMkdirAndDeleteAndRename() throws IOException {
// 创建目录
// fs.mkdirs(new Path("/a/b/c"));
// fs.mkdirs(new Path("/a1/b1/c1"));
// 重命名目录
// fs.rename(new Path("/a"),new Path("/a3"));
// 删除文件夹,如果文件夹非空,删除时第二个参数必须为ture
fs.delete(new Path("/a1"),true);
}
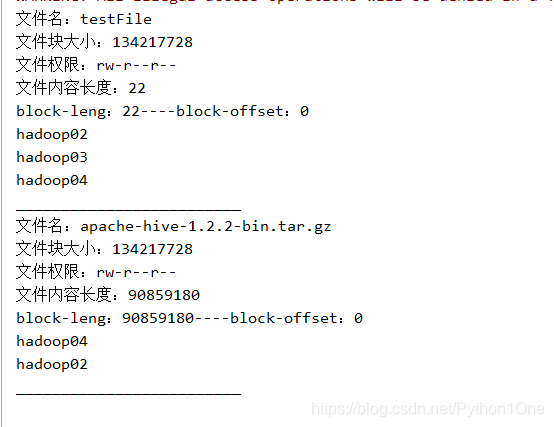
- 查看目录信息(只显示文件)
@Test
public void testListFiles() throws IOException {
// 获取迭代器对象true:递归获取
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/user/root"), true);
// 变量迭代器
while (listFiles.hasNext()){
// 一个个获取listFiles中的内容
LocatedFileStatus fileStatus = listFiles.next();
// 打印当前文件名称
System.out.println("文件名:"+fileStatus.getPath().getName());
// 打印当前文件块大小
System.out.println("文件块大小:"+fileStatus.getBlockSize());
// 打印当前文件权限
System.out.println("文件权限:"+fileStatus.getPermission());
//打印当前文件内容长度
System.out.println("文件内容长度:"+fileStatus.getLen());
// 获取block块的信息(长度,DataNode信息)
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
// 得到元数据的一个序列
for (BlockLocation bl: blockLocations
) {
System.out.println("block-leng:"+ bl.getLength()+"----"+"block-offset:"+bl.getOffset());
// 获取DataNode信息
String[] hosts = bl.getHosts();
// 得到文件在DataNode的序列
for (String host:hosts
) {
System.out.println(host);
}
}
System.out.println("_________________________");
}
}




















 6400
6400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









