





自动采样和自适应残差学习-AutoLUT:LUT-Based Image Super-Resolution with Automatic Sampling and Adaptive Residual Learning(2025 CVPR)
本文将围绕《AutoLUT:LUT-Based Image Super-Resolution with Automatic Sampling and Adaptive Residual Learning》展开完整解析。本文提出了一种AutoLUT框架,包含AutoSample和AdaRL两个即插即用模块。AutoSample 通过训练自动学习采样权重,在不增加推理成本的情况下适应像素变化并扩大感受野;AdaRL 改进残差层,增强层间信息融合与细节信息流该方法在 MuLUT 和 SPF-LUT 上效果显著,对 MuLUT 在 5 个数据集上平均提升约0.20 dB 的 PSNR,对 SPF-LUT 在存储减少超50% 、推理时间减少约2/3 的情况下仍保持相近性能,且易集成到各类基于 LUT 的超分辨率网络,适合资源受限边缘设备部署。参考资料如下:
[1]. 论文地址
[2]. 代码地址
专题介绍
Look-Up Table(查找表,LUT)是一种数据结构(也可以理解为字典),通过输入的key来查找到对应的value。其优势在于无需计算过程,不依赖于GPU、NPU等特殊硬件,本质就是一种内存换算力的思想。LUT在图像处理中是比较常见的操作,如Gamma映射,3D CLUT等。
近些年,LUT技术已被用于深度学习领域,由SR-LUT启发性地提出了模型训练+LUT推理的新范式。
本专题旨在跟进和解读LUT技术的发展趋势,为读者分享最全最新的LUT方法,欢迎一起探讨交流,对该专题感兴趣的读者可以订阅本专栏第一时间看到更新。
系列文章如下:
【1】SR-LUT
【2】Mu-LUT
【3】SP-LUT
【4】RC-LUT
【5】EC-LUT
【6】SPF-LUT
【7】Dn-LUT
【8】Tiny-LUT
【9】3D-LUT
【10】4D-LUT
【11】AdaInt-LUT
【12】Sep-LUT
【13】CLUT
【14】ICELUT
一、研究背景
该篇文章优化的是LUT的基础模块,阅读前需要有Mu-LUT的学习基础,建议读者可以首先熟悉本专栏的MuLUT文章讲解。
传统基于查找表(LUT)的 SR 方法(如 SR-LUT、MuLUT、SPF-LUT)存在缺陷:
- 依赖固定采样模式(如 MuLUT、SPF-LUT 用 3 种固定采样策略覆盖 3×3 感受野),灵活性差,难以适应数据自然变化,限制细节捕捉能力;
- 未引入残差层,因直接使用残差连接会使 LUT 输入值超出 [0,255] 范围,导致 LUT 尺寸剧增或精度损失,影响层间信息流动。
以下几点缺陷,可以通过MuLUT的基础模块来说明,如下图是MuLUT的基础模块:
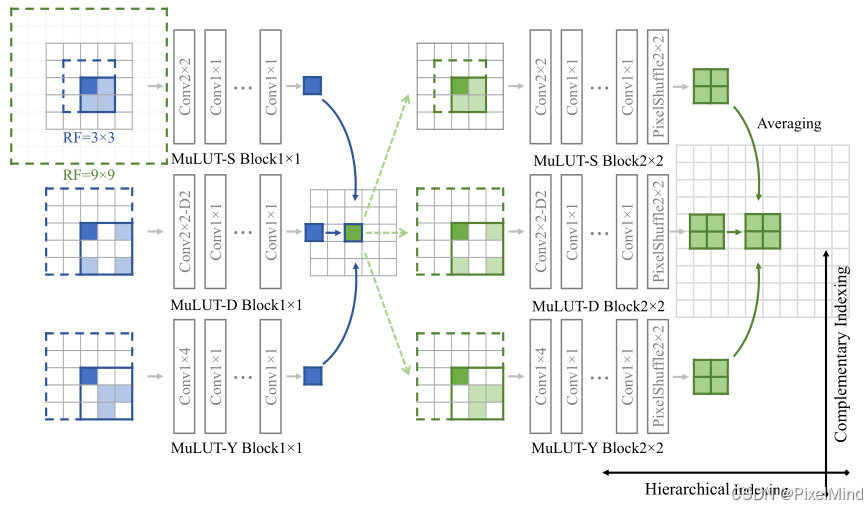
可以看到MuLUT通过选取3种不同模式的2x2 LUT来组成一个3x3感受野的模块,这种方式比较固定,这对应着第1个缺陷;同时可以看到MuLUT是一个直筒的结构,不存在残差连接,这对应了第2个缺陷。
据此,针对以上两个缺陷,作者提出了AutoLUT来进行优化,能够解决上述2个问题,同时还可以减小LUT的存储量,性能指标展示如下所示。
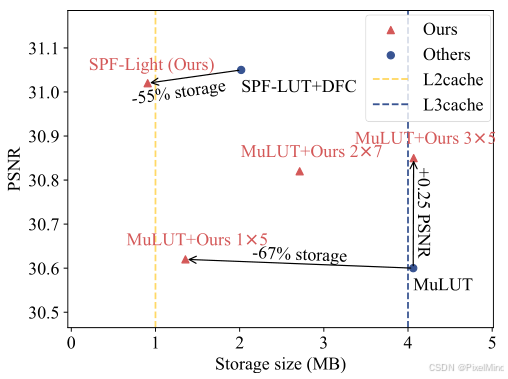
论文对比MuLUT和SPFLUT2个算法均有效果和存储量上的优势。贡献如下:
- 提出AutoSample模块,实现可学习的像素抽象,扩大感受野且无额外推理成本。
- 提出AdaRL模块,适配 LUT 网络的残差学习,增强层间信息流动。
- 两个模块均为即插即用,可灵活集成到各类基于 LUT 的 SR 网络。
- 实验证明,方法在提升性能的同时,显著减少存储(最多减少 67%)和推理时间(最多减少 2/3)。
二、AutoLUT方法
AutoLUT 框架核心是AutoSample(自动采样) 和AdaRL(自适应残差学习) 两个即插即用模块,可集成到现有 LUT-based SR 网络中。
整体流程图如下所示:

图中可以看出核心模块是AutoLUT Group和残差连接,从输入
X
0
X_0
X0一直到输出
X
n
X_n
Xn。而AutoLUT Group如下所示:
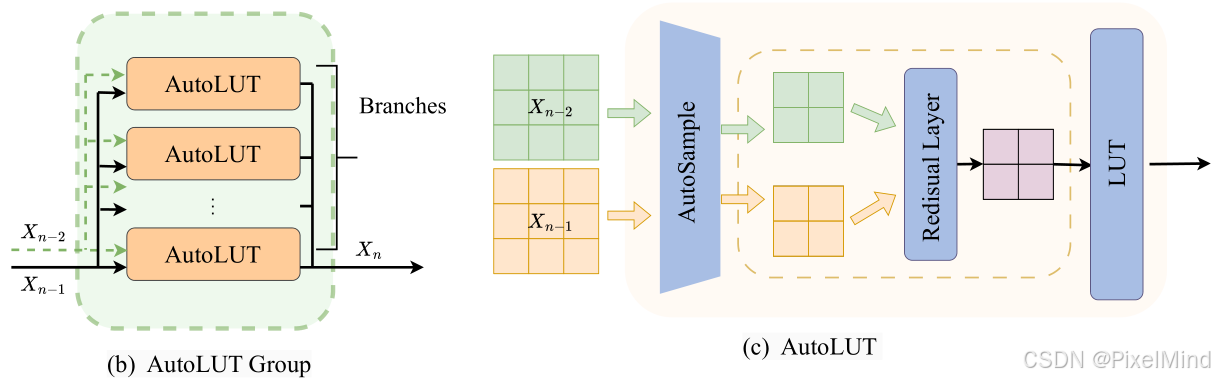
由多个AutoLUT构成,输入有2个包含上一个AutoLUT Group的输入和输出,其中AutoLUT的个数定义为Branches,AutoLUT是最核心的模块,包含了前面讲到的AutoSample和Residual,两个输入经过这两个模块后,特征图的分辨率会减小,最后经过LUT查表得到结果。
这里需要读者类比MuLUT的过程,此为论文最核心的部分,MuLUT的输入只有一个,这个输入经过3个不同的LUT查表后得到一个输出,也就是说AutoLUT是1个LUT+AutoSample+Residual Layer替换了3个LUT,这个Residual Layer可能不存在,当输入为最开始的输入时。
更具体的AutoLUT模块流程如下所示,包含以下几步:
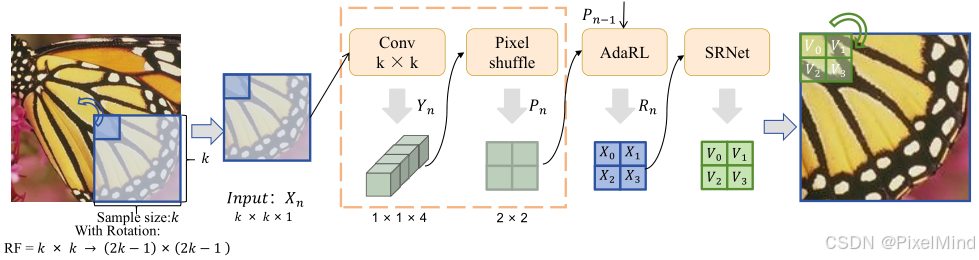
- 选取一个sample size k,使用一个unfold操作,对图像进行折叠,折叠后我们只需要观察其中一个窗口即可(其他的同理),因此此时图中显示 I n p u t : X n Input:X_n Input:Xn的shape是 k × k × 1 k\times k \times 1 k×k×1。
- 使用一个 C o n v k × k Conv \ k \times k Conv k×k对图像进行处理,这里的输出通道个数会是4,因此卷积完的输出 Y n Y_n Yn会变成 1 × 1 × 4 1\times 1 \times 4 1×1×4。
- 使用Pixelshuffle处理后,可以将通道给到空间上输出是 P n P_n Pn,shape会是 2 × 2 × 1 2\times 2 \times 1 2×2×1,该步处理完完成了AutoSample,可以看到这步通过结合卷积完成了感受野的扩展。
- 使用AdaRL,融合前一个AutoSample模块的输入 P n − 1 P_{n-1} Pn−1,得到 R n R_n Rn,这里shape保持不变。
- 最后经过一个标准的SRNet,是一个标准的LUT模块,在这个模块中可以做放大或者不放大,图中显示的是放大的LUT。
下面讲解AutoSample和AdaRL如何设计能够保证不超出范围送入SRNet中完成查表。
2.1 Automatic Sampling (AutoSample)
前面已经讲过了,AutoSample需要经过一个卷积和一个Pixelshuffle,用下式表示:
Y
n
=
Conv
(
X
n
,
W
)
Y_{n} = \text{Conv}\left(X_{n}, W\right)
Yn=Conv(Xn,W)对于每一个输出通道
c
c
c来说,可以表示为:
Y
n
(
c
)
=
∑
i
=
1
k
∑
j
=
1
k
X
n
(
i
,
j
)
⋅
W
(
i
,
j
,
1
,
c
)
Y_{n}^{(c)} = \sum_{i=1}^{k} \sum_{j=1}^{k} X_{n}^{(i, j)} \cdot W^{(i, j, 1, c)}
Yn(c)=i=1∑kj=1∑kXn(i,j)⋅W(i,j,1,c)为了不超出范围,需要
W
W
W满足下列要求:
W
(
i
,
j
,
1
,
c
)
=
exp
(
W
(
i
,
j
,
1
,
c
)
)
∑
i
′
=
1
k
∑
j
′
=
1
k
exp
(
W
(
i
′
,
j
′
,
1
,
c
)
)
W^{(i, j, 1, c)} = \frac{\exp\left(W^{(i, j, 1, c)}\right)}{\sum_{i'=1}^{k} \sum_{j'=1}^{k} \exp\left(W^{(i', j', 1, c)}\right)}
W(i,j,1,c)=∑i′=1k∑j′=1kexp(W(i′,j′,1,c))exp(W(i,j,1,c))用一个softmax对
W
W
W进行处理,这样子确保权重非负且和为1,约束
Y
n
Y_n
Yn在[0,255]。这里作者有给出证明,但这是显然的,感兴趣的读者可以看原文。
后续经过下式的PixelShuffle得到2x2的输出。
P
n
=
Pixelshuffle
(
Y
n
)
P_{n} = \text{Pixelshuffle}\left(Y_{n}\right)
Pn=Pixelshuffle(Yn)这样完成了AutoSample。
2.2 Adaptive Residual Learning (AdaRL)
AdaRL需要接受2个输入,分别是 X n − 1 X_{n-1} Xn−1和 X n − 2 X_{n-2} Xn−2,他们经过Autosample模块进行采样: P n − 2 = AutoSample ( X n − 2 ) P_{n-2} = \text{AutoSample}\left(X_{n-2}\right) Pn−2=AutoSample(Xn−2) P n − 1 = AutoSample ( X n − 1 ) P_{n-1} = \text{AutoSample}\left(X_{n-1}\right) Pn−1=AutoSample(Xn−1)采样后进行自适应残差融合: R n − 1 ( i , j ) = ( 1 − W Residual ( i , j ) ) ⊙ P n − 1 ( i , j ) + W Residual ( i , j ) ⊙ P n − 2 ( i , j ) R_{n-1}^{(i, j)} = \left(1 - W_{\text{Residual}}^{(i, j)}\right) \odot P_{n-1}^{(i, j)} + W_{\text{Residual}}^{(i, j)} \odot P_{n-2}^{(i, j)} Rn−1(i,j)=(1−WResidual(i,j))⊙Pn−1(i,j)+WResidual(i,j)⊙Pn−2(i,j)其中, W R e s i d u a l ∈ [ 0 , 1 ] 2 × 2 W_{Residual} ∈ [0,1]^{2×2} WResidual∈[0,1]2×2(学习的2×2空间权重)。显然由于 W R e s i d u a l W_{Residual} WResidual做了约束,因此范围合理,输出会满足下式: R n − 1 ∈ [ min ( P n − 1 , P n − 2 ) , max ( P n − 1 , P n − 2 ) ] R_{n-1} \in \left[\min\left(P_{n-1}, P_{n-2}\right), \max\left(P_{n-1}, P_{n-2}\right)\right] Rn−1∈[min(Pn−1,Pn−2),max(Pn−1,Pn−2)]也就是说不会超出8bit的范围。
三、实验结果
首先讲一下定量实验。

关键结论:
- MuLUT+Ours 相比 MuLUT,存储仅从 4.062MB 增至 4.067MB,平均 PSNR 提升0.20 dB,其中 Set5 提升 0.25 dB、Manga109 提升 0.37 dB。
- SPF-Light 相比 SPF-LUT+DFC,存储减少55%(从 2.018MB 降至 0.907MB),PSNR 性能几乎持平。
接着是定性实验。

整体效果更有优势。
然后是消融实验,如下表对比了网络中的一些参数。

- Sample Size:即前面讲到的AutoSample的 k k k参数, k = 5 k=5 k=5 时性能最优, k = 7 k=7 k=7时因引入无关信息,PSNR 降至 30.82 dB。
- Branches:即前面讲到的AutoLUT并联个数,分支数增加提升性能,但存储也增加;3 分支兼顾性能与存储。
后续是AutoSample 与 AdaRL 的单独 / 组合效果。

结论:两者组合效果最佳,AdaRL 单独提升更显著(+0.10 dB),AutoSample 单独提升 0.03 dB。
最后作者对比了实际的推理性能:

MuLUT+Ours 1×5 推理时间减少约 2/3,PSNR 略升;SPF-Light 推理时间减少约 2/3,有优势。
四、总结
AutoLUT 框架有效解决了现有 LUT-based SR 方法的缺陷,兼顾性能、存储与推理效率,特别适合资源受限的边缘设备部署。博主的通俗总结是,AutoLUT提出了一种将常规卷积网络模块应用到基于LUT网络中的方法,实际应用的性能表现上有优势(因为卷积的参数相比较LUT是少的多的多的,计算速度也不慢),就是不知道加入计算的卷积后在功耗上会不会有明显提升。
感谢阅读,欢迎留言或私信,一起探讨和交流,如果对你有帮助的话,也希望可以给博主点一个关注,谢谢。

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









