



启动靶机和Kali后进行扫描

使用namp -A -sV -T4 -p- 靶机ip 查看靶机开放的端口
发现开放了21的ftp,、80的http、55077的ssh服务端口
先查看一下ftp端口,有文件

查看一下cred
Y2hhbXA6cGFzc3dvcmQ= 解码得到 champ:password
访问 80 端口,发现是一个登陆页面
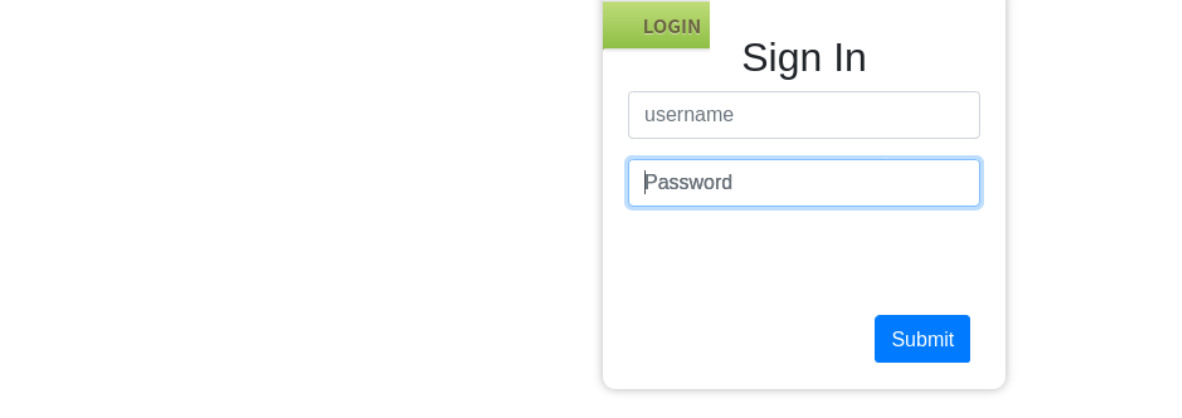
使用上面的密码试一下,登录成功

点击about us会下载一个文件,解压后

sudo内容为
Did you notice the file name? Isn't is interesting?
使用 steghide 工具,查看一下info
bmp文件盲猜pass为sudo,jpg文件没密码成功得到信息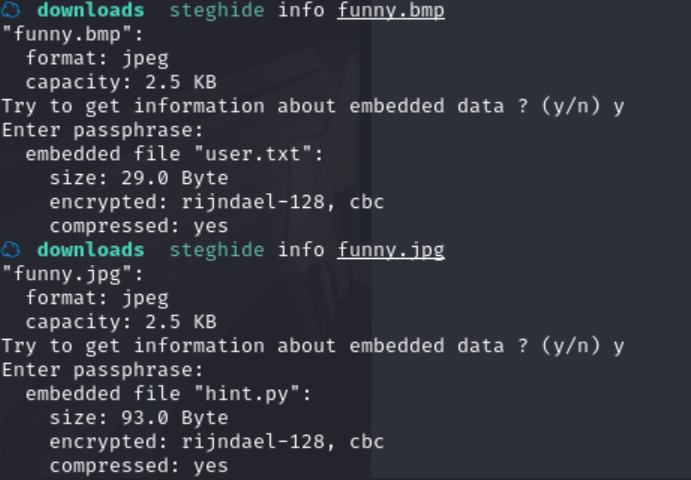
可以看到,两张图都隐藏有文件
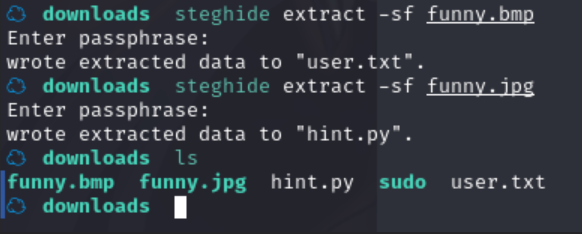
分别查看其内容
This is_not a python file but you are revolving around. well, try_ to rotate some words too.
jgs:guvf bar vf n fvzcyr bar
user.txt是一串密文, hint.py提示rotate
解密网址:http://www.rot13.de/index.php,成功解密
55677是一个ssh服务,上边解出来的东西就是账号密码,登录
在Documents发现了一个backup.sh文件
分析脚本发现了账户密码n00b:aw3s0m3p@$$w0rd
在 Downloads发现了个flag-1.txt
VGhlIGZsYWcgaXMgdGhlIGVuY29kZWQgc3RyaW5nIGl0c2VsZg
base64解密结果The flag is the encoded string itself
在pictures发现了个echo.sh
#!/bin/bash #find something related #It may help you echo "All the best :)"
回到最开始的那个脚本,利用其中的账户密码,切换成n00b用户

















 1828
1828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









