






笔记下载
链接:https://pan.baidu.com/s/1bFz8IX6EkFMWTfY9ozvVpg?pwd=deng
提取码:deng
b站视频:408-计算机网络-笔记分享_哔哩哔哩_bilibili
包含了408四门科目(数据结构、操作系统、计算机组成原理、计算机网络)
如果链接失效了,看看b站,或者私信我
408相关资料(真题 模拟卷等)
链接: https://pan.baidu.com/s/1Qga8aMgcrVfCmrry68vqog?pwd=974t提取码: 974t
零、每天记忆的东西
1、数据结构——基础
逻辑结构:集合、线性、树形、图
存储结构:散列、索引、顺序、链式 顺序存储(顺序)和随机存储(链式)
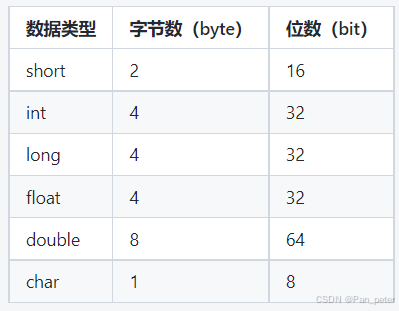
1、C语言——各种数据类型大小(int、short、double)
signed/unsigned整型数据都是按补码形式存储的,只是signed型的最高位代表符号位,而在unsigned型中表示数值位,因此这两者所表示的数据范围也有所不同
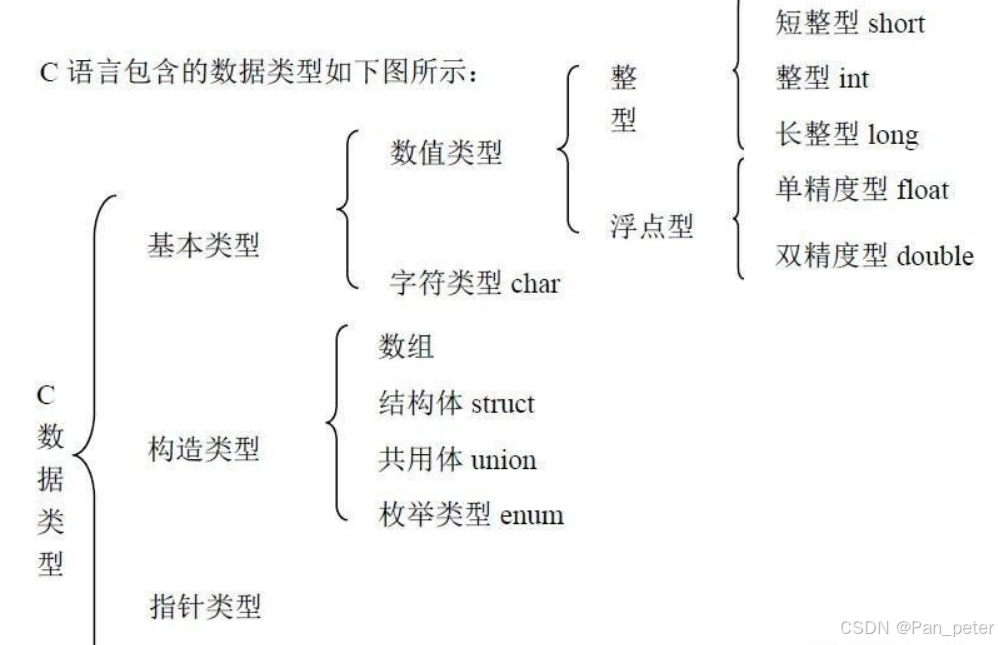
不同操作系统上不一样,位数也不一样!
64位中,long是64位,32位中,long是32位!
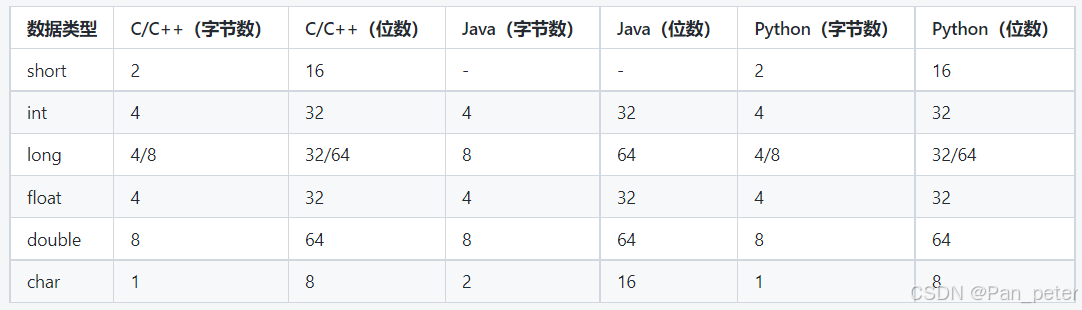
u32 = unsigned 32 位的 (还有unsigned long、 unsigned int)
u32在不同平台是不一样的
比如:你想读取4字节,你在32位里面用来unsigned long是没错的,但是你跑到64位就出问题了,导致程序不兼容
解决方法:
1、宏定义——在不同平台重新定义u32 (c语言得自己搞,cpp自带)
1、栈、队列、链表、数组、串(KMP)
进、出堆栈时——对栈顶指针的操作顺序是不同的
PUSH——先保存数据,再更新栈顶指针
POP——先更新栈顶指针,再读取数据
结构体的写法
数组索引的操作(Array[i%n])——n为长度,i++
KMP的next数组
1、二叉树(K叉树公式)、二叉树和树和森林(表示方法,遍历方法)
1、图(各种图、拓扑排序、逆拓扑、AOE、AOV)
1、图(十字链表、邻接多重表、三元组、邻接矩阵、邻接表)
1、查找(红黑树、B树、B+树、败者树——折半查找+)
B树(删除、插入)
B+树和红黑树的性质
1、排序(各种特点,时间复杂度、空间复杂度)
一、第一章——数据结构

1、基本概念和术语
- 数据:是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合.是计算机程序加工的"原料".
- 数据元素:是组成数据的,有一定意义的基本单位,在计算机中通常作为整体进行考虑和处理.
- 数据项:一个数据元素可以由若干个数据项组成.
- 数据对象:是性质相同的数据元素的集合,是数据的子集.
(1)迭代和递归
迭代 更适合于需要高效执行且不需要频繁调用函数的情况,尤其是在处理大规模数据或对性能要求较高的应用中。
递归 更适合于那些具有明显递归结构的问题,比如树形结构的遍历、图搜索算法、分治法等。如果编程语言支持尾递归优化,则可以在保持代码简洁的同时避免栈溢出。
迭代就是指使用for循环么?
- 迭代不仅仅局限于for循环,虽然for循环是实现迭代的一种常见方式。
- 实际上,迭代是一种更为广泛的概念
- 在Python中,可以使用内置的迭代器(Iterator)来遍历集合类型的数据
- 某些语言提供了像map()、filter()、reduce()这样的高阶函数,它们也可以用来实现迭代操作
1、效能的度
(1)时间复杂度
一般不特别说明,讨论的时间复杂度均是最坏情况下的时间复杂度


(2)空间复杂度

(2)习题

ABCBB
1、逻辑结构和物理结构
我们把数据结构分为逻辑结构和物理结构.
(1)逻辑结构
逻辑结构:是指数据对象中数据元素之间的相互关系
逻辑结构分为以下四种:
- 集合结构:集合结构中的数据元素除了同属于一个集合外,它们之间没有其他关系.
- 线性结构:线性结构中的数据元素之间存在一个对一个的关系.
- 树形结构:树形结构中的数据元素之间存在一种一对多的层次关系.
- 图形结构:图形结构的数据元素是多对多的关系.
逻辑结构是针对具体问题的,是为了解决某个问题,在对问题理解的基础上,选择一个合适的数据结构表示数据元素之间的逻辑关系.
(1)物理结构
数据是数据元素的集合,根据物理结构的定义,实际上就是如何把数据元素存储到计算机的存储器中.存储器主要是针对内存而言的,像硬盘,软盘,光盘等外部存储器的数据组织通常用文件结构来描述.
数据元素的存储结构形式有:顺序存储和链式存储.
- 顺序存储结构:是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的.
- 链式存储结构:是把元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的.
索引:B树与B+树那种
散列:数组+链表(哈希)
二、第二章——线性表——P74
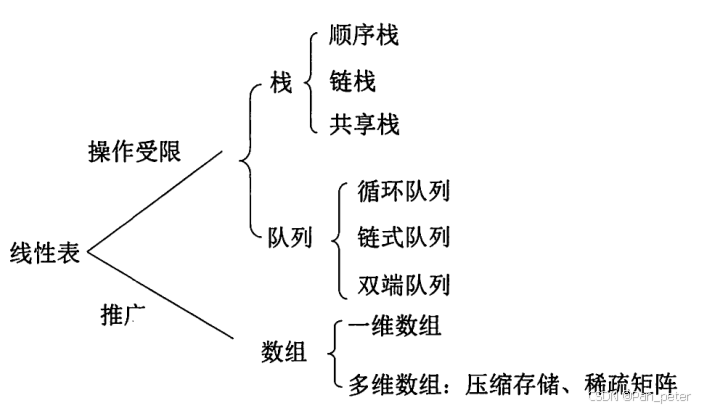
线性表的各种操作——增删改查——边界判断(空 or 满)
1、线性表 (栈、队列、链表、数组、矩阵、串)

(1)数组(顺序表)——考察方式

(1)数组(顺序表)——查找、删除





DC
(1)数组(顺序表)——压缩矩阵(三角矩阵、对称矩阵、带状矩阵、稀疏矩阵)




(1)链表——逻辑结构 & 物理结构(了解)

(1)链表——尾插法 & 头插法(了解)

(1)链表——带头结点的(头结点 & 头指针)
- 首元结点:就是链表里“正式”的第一个结点,即链表的开始结点
- 头结点:(为了方便操作链表而附设的)头结点数据域保存链表的相关信息(比如链表长度)
- 头结点指针(头指针):头指针是指向链表的基地址
异同点:(是否带有有效数据)
- 头指针和头结点都与链表相关,但是功能上有所不同。
- 头指针是指向链表中第一个节点的指针,用于标识和操作整个链表。
- 头结点是一个虚拟节点,不存储有效数据,方便处理链表的插入、删除等操作
异点:
- 头指针可以为空指针,表示链表为空,而头结点是必需的,用于连接链表中的节点。
- 头指针可以动态修改指向的节点,而头结点的位置是固定的

(1)链表——带头结点的循环链表

考察:带头结点的非空循环单链表的删除过程
- q临时指针指向第一个结点,h连接q的下一个
- 如果第一个结点=最后结点,那么就让p指向头结点,再释放q

(1)链表——指针变量 & 指针类型
指针变量:指针变量是指存放地址的变量
- 指针指向的就是一个地址(地址就是固定的位数),
- 指针存的就是一个地址(不管结构体再怎么长,在内存里面的起始位置还不是内存里面的一个单位)
- 指针变量——就是操作系统给你的一个虚拟地址起始位置
- 指针的大小是固定的,它们所能存储的地址空间的大小取决于系统的位数
指针类型
- 决定了内存访问的字节数以及指针加减运算时移动的字节数
- 说到底,就是你解引用的时候,知道是什么类型的(知道这个数据应该读取多大范围)

(1)链表——双指针、快慢指针、循环

(循环链表)这道题是最恶心的,给你绕来绕去的:

(1)栈——基本操作(真题)
送分题



(1)栈——前缀、中缀、后缀表达式
进、出堆栈时——对栈顶指针的操作顺序是不同的
PUSH——先保存数据,再更新栈顶指针
POP——先更新栈顶指针,再读取数据

Reverse Polish notation (逆波兰表达式=后缀表达式 )
Polish notation (波兰表达式=前缀表达式)

(1)栈——习题(表达式转换)



(1)栈——卡塔兰数(公式)卡特兰数


(1)栈——共享栈(一定要记得画图)
- 共享栈:两个栈共享同一片存储空间,这片存储空间不单独属于任何一个栈
- 某个栈需要的多一点,它就可能得到更多的存储空间
- 两个栈的栈底在这片存储空间的两端,当元素入栈时,两个栈的栈顶指针相向而行。
- 与普通栈一样,共享栈——出栈入栈的时间复杂度仍为O(1)
判断:
判断情况在不同题目下是不一样的!具体得看栈顶指针在哪里


(1)栈——进制转换
我们以十进制数 233 为例,将其转换为二进制。
- 用 2(二进制的基数)除以 233,得到商 116 和余数 1
- 然后,将商 116 除以 2,得到商 58 和余数 0
- 继续这个过程,直到商为 0
- 最后,将所有的余数从下往上排列,得到二进制表示为 11101001
这个转换过程可以轻松地使用栈来实现
(1)栈——函数调用(应用)
为什么递归导致栈溢出?
递归导致栈溢出的原因在于每次函数调用自身时,都会在调用栈中创建一个新的栈帧(stack frame)来存储该次调用的局部变量、参数和返回地址。当递归深度过大时,这些栈帧会占用大量的内存空间,最终超过操作系统或语言运行环境为每个线程分配的栈空间限额,从而引发栈溢出错误
解决栈溢出的方法
优化递归算法、使用迭代代替递归、增加栈大小、分治法等等


(1)队列——简单介绍
队列的特点是按照元素加入的先后顺序进行操作,先加入队列的元素会先被取出,后加入的元素会后被取出。
这种特性常常被用于模拟实际生活中的排队场景,例如银行柜台排队、CPU任务调度等。
(1)队列——循环队列(两种方式)
- 长度 = (尾指针 – 头指针 + n)% n
- 队列初始化——front=rear=0 或者(Q.front=0,Q.rear=maxsize-1)
- 队空条件——front==rear (队头指针和队尾指针指向同一个结点)
- 队满条件——(rear+1)%maxSize==front (408一般都考这个)
- 元素入队——Q.rear=(Q.rear+1)%MaxSize
再重复一遍:
①初始队列:Q.front == Q.rear (队列初始化)
②入队操作:Q.rear = (Q.rear+1)%maxSize(队尾+1)
③出队操作:Q.front = (Q.front+1)%maxSize(队首+1)
④队空条件:Q.front == Q.rear (队头指针和队尾指针指向同一个结点)
⑤队满条件:(Q.rear+1)%maxSize == Q.front (408一般都考这个)
⑥队列长度:(Q.rear+maxSize-Q.front)%maxSize 长度 = (尾指针 – 头指针 + n)% n

队满:两种方法
① 牺牲一个空间,当队尾指针(rear)加1取模 等于 队头指针(front)时,队满!
(Q.rear + 1) % MAX_SIZE == Q.front // 队满
② 增加一个变量size,记录队列的长度即可!
size == MAX_SIZE // 队满
队头指针(front)——出(清除元素)
队尾指针(rear)——进(加入元素)

(1)队列——循环队列(真题)


2011真题——让人困惑的点在于:
- 因为front和rear指向了一个结点,并且那个结点上有值
- 【队空判断】就不是我们熟悉的那个(front==rear)
- 因此,既然【队空判断】可以修改,那【入队操作】是不是也可以修改?
- 我是不是可以先写入元素,再移动rear指针?
- 那么答案是不是可以为(0,0)
- 如果是(0,0)的话,那么rear就跑到front前面去了,所以舍去,只有选B


(1)队列——4种(FIFO、双端队列、优先级、循环)

(1)队列——真题(实际运用)

(1)静态、动态——(静态链表、动态链表)(静态数组、动态数组)

2、非线性表 (树、图、堆、散列表)
线性表也可以表示非线性数据——比如树

三、第三章——串

1、串(基本)
详细信息:https://blog.youkuaiyun.com/2301_80031203/article/details
- 串(或字符串)是由零个或多个字符组成的有限序列
- 串 属于 线性表
- 串中所含字符的个数称为该串的长度(或串长),含零个字符的串称为空串,用Ф表示
- 串相等:当且仅当两个串的长度相等并且各个对应位置上的字符都相同时,这两个串才是相等的
- 所有空串是相等的
- 子串:一个串中任意个连续字符组成的子序列(含空串)称为该串的子串。例如, “abcde”的子串有: “”、“a”、“ab” 、“abc”、“abcd”和“abcde”等
- 真子串是指不包含自身的所有子串
串和线性表有什么异同?
串中元素逻辑关系与线性表的相同,串可以采用与线性表相同的存储结构。

“abcde”有多少个子串 ?
解: 空串数:1
- 含1个字符的子串数:5
- 含2个字符的子串数:4
- 含3个字符的子串数:3
- 含4个字符的子串数:2
共有1+2+3+4+5=15个子串
(1)抽象数据类型定义
串抽象数据类型=逻辑结构+基本运算(运算描述)

串的基本运算如下:
- StrAssign(&s,cstr):将字符串常量cstr赋给串s,即生成其值等于cstr的串s。
- StrCopy(&s,t):串复制。将串t赋给串s。
- StrEqual(s,t):判串相等。若两个串s与t相等则返回真;否则返回假。
- StrLength(s):求串长。返回串s中字符个数。
- Concat(s,t):串连接:返回由两个串s和t连接在一起形成的新串。
- SubStr(s,i,j):求子串。返回串s中从第i(1≤i≤n)个字符开始的、由连续j个字符组成的子串。
- InsStr(s1,i,s2):插入。将串s2插入到串s1的第i(1≤i≤n+1)个字符中,即将s2的第一个字符作为s1的第i个字符,并返回产生的新串。
- DelStr(s,i,j):删除。从串s中删去从第i(1≤i≤n)个字符开始的长度为j的子串,并返回产生的新串。
- RepStr(s,i,j,t):替换。在串s中,将第i(1≤i≤n)个字符开始的j个字符构成的子串用串t替换,并返回产生的新串。
- DispStr(s):串输出。输出串s的所有元素值。
1、串的模式匹配

所谓字符串匹配算法,简单地说就是在一个目标字符串中查找是否存在另一个模式字符串。如在字符串 "ABCDEFG" 中查找是否存在 “EF” 字符串。
- 可以把字符串 "ABCDEFG" 称为原始(目标)字符串,“EF” 称为子字符串或模式字符串
- 模式串——相对于文本很短,可能等于100或者1000;
- 目标串(文本)——相对于模式是很长的(N可能等于100万或者10亿
模式匹配问题有什么特点?
1) 算法的一次执行时间:问题规模通常很大,常常在大量信息中进行匹配
2) 算法改进所取得的积累效益:模式匹配操作经常被调用,执行频率高
(1)BF暴力算法
BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,
BF算法,亦称简单匹配算法。采用穷举的思路。BF是指暴力的意思!
BF算法分析:
- 算法在字符比较不相等,需要回溯(即i=i-j+1):即退到s中的下一个字符开始进行继续匹配
- 最好情况下的时间复杂度为O(m)
- 最坏情况下的时间复杂度为O(n×m)
- 平均的时间复杂度为O(n×m)
1、KMP算法
KMP算法: 学不会KMP算法,这是个好事儿啊_哔哩哔哩_bilibili
- KMP算法是D.E.Knuth、J.H.Morris和V.R.Pratt共同提出的,简称KMP算法
- 该算法较BF算法有较大改进,主要是消除了主串指针的回溯
(1)Next数组
Next数组求值:KMP算法动画(next数组求值)_哔哩哔哩_bilibili
Next数组的作用
next数组指示了当前模式串在该位置匹配冲突(即失配)时,应该将模式串的哪一位与此位对齐。
Next数组的注意事项
- 当next数组的前2位是(0,1),匹配失败时,需要把匹配索引修改为next[i]-1
- 当next数组的前2位是(-1,0),匹配失败时,需要把匹配索引修改为next[i]
- 真题都是考的next[i]-1
next数组或nextval数组里面的0是什么意思?
- 数组的值为1,在执行了next[i]-1后,指针会移动到数组索引号0的位置
- 数组的值为0,在执行了next[i]-1后,那么指针会移动到数组索引号-1的位置
- 有-1这个索引号么?当然没有啦~但我们可以理解为就是在索引0的前面
- 当为-1的时候,主串的指针一定会往后移动1位

(1)Nextval数组
为什么会有Nextval数组
nextval数组是next数组的优化版 (他是修改后的next数组)2024真题
当一个字母失配时,根据Next数组进行调整后,可能会再次失配,所以我们可以直接一步到位么?
当然可以!优化后的nextval数组,他提前预判,让你直接一步回到解放前
Nextval求法

(1)习题
求Next数组

求Nextval数组

(1)从有限状态自动机(AC自动机)看KMP(拓展)
详细文章: 图解KMP算法(next数组、nextval数组、有限自动机【AC自动机】)———附带模版代码和完整示例-优快云博客
- 通俗来讲,可以把有限状态机看作一个有向图,其中顶点表示不同的状态(类似于动态规划中的状态),边表示状态之间的转移。
- 有限状态机有一个起始状态和终止状态,从起始状态出发,最终转移到终止状态,那状态机就会正常停止。
- 对KMP算法来讲,就相当于对模式串pattern构造一个有限状态机,然后将文本串text的字符从头到尾一个一个送入这个机器,如果自动机可以从初始状态到达最终状态,那么说明pattern是text的子串。

- 如上图所示,起始状态是0,终止状态是6。如果在状态0,输入字符‘a’,就会进入状态1,如果在状态1,输入字符‘b’,就会进入状态2,如果文本串中有"ababab"这个子串,状态就会不断的从0转移到6,自动机就成功停止了。
- 如果图中碰到了意外情况,例如在状态4送入自动机的不是‘a’,它就沿一条回退的边转移到转台2 。如果初始状态0,送入自动机的不是字符‘a’,它就会从一条自己转移到自己的边绕圈,这样自动机就会一直处于初始状态。
图中所有回退箭头就是next数组代表的位置,其中-1和0和统一合并为起始位置
注意:
- 如果把这个自动机推广为树形,就产生字典树(前缀树),可以解决多维字符串匹配问题(即一个文本匹配多个模式串使得匹配问题)。
- 通常把解决多维字符串匹配问题的算法称为AC自动机。
- 而KMP算法只不过是AC自动机的特殊形式。
四、第四章——树

"高度"通常指从子节点到根节点的距离,也就是从下往上测量二叉树的深度;
"深度"通常指从根节点到某个节点的距离,也就是从上往下测量二叉树的深度。
非终端结点(中间结点或内部结点或分支结点)——度不为零的结点
终端结点(叶子结点、叶结点)——度为零的结点
根结点、非根结点、双亲结点、祖先结点、左孩子、右孩子、左兄弟、右兄弟
右孩子——X是双亲结点的右孩子

1、树
(1)普通树
总结点数 = 叶子结点 + 其他结点(度为1、2…)
总结点数 = 总边数(总度数)+ 1
树的高度 = 根节点到最远叶子节点的路径长度
树的深度 = 树的高度 – 1
树的路径长度 = 从根结点到树中每个结点的路径长度之和。
(1)k叉树
当为k叉树时:
1、最大节点数 = k^(树的高度) – 1 / k-1 (等比数列求和)【满K叉树】
2、最少结点数 = k*(h-1) + 1
满k叉树:
总边数 = 非叶子结点 * 度数k
总结点数 = 总边数(总度数)+ 1
叶子结点 = 1+ 大于1度的结点 * 个数(并求和)——本质:度>1,则会增加叶子结点
(1)树的存储结构(孩子、双亲、孩子兄弟表示法)
双亲——数组——存储父亲id(数据库中常用:pid)——【父亲表示法】
孩子——数组+链表——存储儿子id
孩子兄弟——二叉链表——左边存储【孩子id】——右边存储【兄弟id】



(1)相关公式 (总结)

(1)真题

2、二叉树(线索二叉树、哈夫曼树、完全二叉树、红黑树…)

(1)等长编码(定长编码)
- 等长编码(Equal Length Code)是一种编码方法,它将不同长度的数据划分为固定长度的编码序列。
- 在等长编码中,每个输入数据都被分配一个固定长度的编码,无论输入数据的长度如何
特点:
- 所有关键字都是叶子结点
- 所有关键字都在同一层(最底层)
优点:
- 译码简单:由于每个字符的编码长度固定,译码过程可以直接按位进行,不需要复杂的解码算法。
- 唯一性:每个码字的长度相同,确保了译码的唯一性,不会出现歧义。
缺点:
- 编码长度可能不是最优:等长编码的编码长度是固定的,无法根据字符出现的频率进行优化,可能导致编码结果较长,占用更多的存储空间或传输带宽
应用场景
等长编码在计算机中广泛应用,例如ASCII码就是一种等长编码。

(1)变长编码
它将不同长度的数据划分为不固定长度的编码序列
哈夫曼编码就是变长编码
特点:
- 所有关键字都是叶子结点
- 根据字符出现的频率分配不同长度的编码,频率高的字符使用较短的编码
(1)哈夫曼树(构建方法)
构建哈夫曼树的步骤如下:
1.根据给定的权值列表,创建一组树节点。
2.将节点按照权值从小到大的顺序排序。
3.选取权值最小的两个节点作为新节点的左右子节点,并将它们的权值相加作为新节点的权值。
4.将新节点插入到节点列表中,并删除原来的两个节点。
5.重复步骤3和步骤4,直到节点列表中只剩下一个节点,即为根节点。
(1)哈夫曼树(前缀编码、哈夫曼编码)
哈夫曼编码是一种前缀编码
设计目的:让使用频次更高的字符,编码长度更短,这样可以节省存储空间且效率更高。
- 哈夫曼树——只有度为0的点 & 度为2的点
- 总结点数 = 度为0的点 + 度为2的点
- 度为2的点 = 度为0的点 – 1
哈夫曼树的公式:
- 总结点数 = (n个符号 * 2) – 1
- 总叶子结点(度为0的结点) = 符号数
58 x 2 -1 = 115

编码出来的——没有歧义!

(1)哈夫曼树(加权路径长度、带权路径长度)
- 带权路径长度WPL(Weighted Path Length)
- 加权

算术平均:3次考试(80分、90分、100分)——平均分:90分
加权平均:观众打分(100分)权重为0.2,评委打分(80分)权重为0.8——加权平均:20+64=84
说人话:就是乘上一个权重,再求和就行了



(1)哈夫曼树(k叉)
忘记公式了,记得凑,保障是满叉的,就行了

例题:
(6-1)%(3-1) = 1
则需要补1个权重为0的结点

(2)AVL树 (平衡二叉树)
文章:数据结构 —— 图解AVL树(平衡二叉树)-优快云博客
AVL 什么意思 ?(英语:Balanced Binary Tree (BBT))
AVL 是大学教授 G.M. Adelson-Velsky 和 E.M. Landis 名称的缩写,他们提出的平衡二叉树的概念,为了纪念他们,将 平衡二叉树 称为 AVL树。
AVL树——本质上是一颗二叉查找树(又称:二叉排序树、二叉搜索树)
AVL树——可以是二叉排序树,二叉排序树不一定是AVL树
AVL树——可以是空树
中序遍历——可以得到有序序列
在AVL树中,任何节点的两个子树的高度最大差别为 1 ,所以它也被称为平衡二叉树 。
平衡因子 = 左子树高度 – 右子树高度
- 当平衡因子为0时,表示节点的左子树和右子树的高度相等,节点处于平衡状态。
- 当平衡因子为正数时,表示左子树的高度大于右子树的高度,节点处于左重状态。
- 当平衡因子为负数时,表示右子树的高度大于左子树的高度,节点处于右重状态。

注意——平衡因子的计算!!!(看子树的高度)

(2)AVL树 (平衡二叉树)——旋转(调整)
视频讲解:平衡二叉树(AVL树)_哔哩哔哩_bilibili
注意:
- 失衡结点的平衡因子
- 如何判断类型(4种)


插入23后,就是RL型,先右旋,再左旋(answer:25)

(2)AVL树 (平衡二叉树)——习题




(3)二叉树 & 完全二叉树 & 满二叉树
二叉树:(度为0和度为2是有关联的!)
总结点数 = 度为0的结点(叶子结点) + 度为1的结点 + 度为2的结点
叶子结点 = 度为2的结点 + 1
二叉树的最大节点数 = 2^(树的高度) – 1 (二进制才有的!!!)
二叉树的最小高度 = log2(节点数+1)【最大高度 = 结点数】
满二叉树:
总边数 = 非叶子结点 * 度数2
总边数 = 总结点数 – 1

若对含n个结点的完全二叉树:(层序遍历进行存储【存储在数组中】)
完全二叉树的特点
完全二叉树i结点的左孩子为2i,右孩子为2i+1 (从1开始编号)
非叶子结点(非终端结点)—— i≤(n/2)向下取整(一半都是:非叶子结点)
i的左孩子 —— 2i
i的右孩子 ——2i+1
i的父节点 ——i/2
完全二叉树的结点关系:
度为1的结点——要么为1个,要么为0个
当总结点数为偶数时,度为1的结点有1个
当总结点数为奇数时,度为1的结点有0个

第四题:是384个(纠错)
(4)二叉树的遍历(前序、中序、后序、层序遍历)
给出【遍历顺序】——让我们构造【二叉树】

前序——入栈
中序——出栈(重点)
后序——入栈
层次——入栈
(5)线索二叉树
- 二叉树是一种逻辑结构,但线索二叉树是加上线索后的链表,
- 即它是二叉树内部的一种存储结构,故是一种物理结构
- 引入线索二叉树正是为了加快查找结点前驱和后继的速度

为什么后序线索二叉树仍不好找后继、先序线索二叉树仍不好找前驱?
在后序线索二叉树中,有后继线索指针的结点的后继很容易找到,直接指向其后继即可。
难找的主要是没有线索指针的结点(即左右子树都不为空)
因为是后序遍历,那么该结点一定是最后被被访问到的,其后继就是它的双亲结点,而它的左右指针都指向了孩子,且没有指向双亲的指针,那么找到它的后继就很困难。

同理,我们可以知道——先序线索二叉树不好找前驱
(5)三叉链表(表示三叉树)
三叉链表:每个结点有3个指针,分别指向左子结点、中子结点和右子结点
如果某个子结点不存在,对应的指针就是空的。
- 空指针——每个结点最多有3个指针,指向3个子结点。
- 空指针——如果某个结点没有子结点,那么它的3个指针都是空的
- 具有n个结点的三叉树用三叉链表表示时,树中空指针的总数是[2n + 1]
(5)三叉链表(表示二叉树)
三叉链表:每个结点有3个指针,分别指向左子结点、右子结点、父节点
为什么用三叉链表?
在二叉链表的存储方式下,从某结点出发可以直接访问到它的孩子结点,但要找到某个结点的父节点需要从根节点开始搜索,最坏情况下,需要遍历整个二叉链表。
三叉链表的好与坏
- 在二叉链表的基础上加了一个指向父结点的指针域,使得即便于查找孩子结点,又便于查找父结点
- 相对二叉链表而言,加大了空间开销

结构体代码:

3、树、森林、二叉树(转换 & 遍历)
树——结点比度数(比边数)多1
森林——每多一棵树,那么度数就会-1(根据总结点树与总度数,可以判断森林中有多少树)
(1)树的存储结构
双亲表示法——父亲表示法(PID)——数组 (多对一)
孩子表示法——儿子表示法(CID)——数组+链表 (一对多)
孩子兄弟表示法——把树转为二叉树(左孩子,右兄弟)——链表
(1)树 & 二叉树

(2)森林 & 二叉树

(3)遍历
树和森林——都是转换为【二叉树】再进行遍历的
树的遍历是指用某种方式访问树中的每个结点,且仅访问一次。主要有两种方式


森林的中序遍历 = 二叉树的中序遍历 = 森林的后序遍历
森林的前序变量 = 二叉树的前序遍历
(4)例题

4、并查集(选择题容易考 ※※※)
存储方式:数组——双亲(父亲)表示法
查找效率:与树的高度有关!
集合操作:Union操作(合并操作)、Find操作(查找操作)

判断无向图(连通性 & 是否有环)

(1)判断两个元素是否在同一个集合

五、第五章——图



Graph(G)——V表示图中的顶点集合(Vertices),E表示图中的边集合(Edges)。
0、专业术语
有向边 = 弧
箭头 = 弧头 | 出度那一边 = 弧尾


(1)公式
完全图——就是边全部都连接完了
无向完全图(边最多,顶点最少)——边数的总数 = n(n-1)/2
有向完全图(边最多,顶点最少)——边数的总数 = n(n-1)
无向图:
度数之和——为偶数!

有向图:


(1)连通图(极小连通子图、极大连通子图)
- 极小是边尽量少,并且保持连通——极小连通子图
- 极大是边尽量多,并且保持连通——极大连通子图



(1)连通图(有向图、无向图)


(1)习题

1、图的存储结构——邻接矩阵、邻接表、十字链表、邻接多重表、三元组

邻接矩阵、邻接表——可以存储(有向图)(无向图)
十字链表——只能存储(有向图)——适合(稀疏图)
邻接多重表——只能存储(无向图)

(1)邻接表——(数组+链表)——(适合稀疏图)

邻接表——是一种顺序分配和链式分配相结合的存储结构
表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。
对于无向图来说,使用邻接表进行存储也会出现数据冗余,表头结点A所指链表中存在一个指向C的表结点的同时,表头结点C所指链表也会存在一个指向A的表结点。
边表结点包含边的起点和终点信息,以及可能的权值或其他附加信息。
边表结点通常存储在单链表中,每个结点代表图中的一条边
(2)邻接矩阵——(二维数组)——(适合稠密图)
邻接矩阵A——就是记录了顶点之间的距离为1
邻接矩阵A2——就是记录了顶点之间的距离为2的路径条数
无向图——可以只存储(上三角 or 下三角)【压缩存储】

有向图:列是出度、行是入度
(4)十字链表 (存储有向图 – 稀疏矩阵)
思维方法
在美国,晚上需要保安通过视频监控对商场、超市、码头仓库和办公写字楼等场所进行安保工作。由于值夜班的成本很高,这成为了一个问题。
一位中国的创业者发现,美国的黑夜正好是中国的白天。他灵机一动,创建了一家公司,承接美国客户的夜间视频监控任务。利用互联网,他的员工可以在白天上班时监控美国的夜间情况。如果发生火灾或偷盗等突发事件,他们可以立即通知美国当地的相关部门处理。
由于充分利用了时差和较低的人力成本优势,这位创业者取得了巨大的成功。这个创意展示了如何通过正向思维、逆向思维和资源整合来创造更大的价值
- 十字链表(Orthogonal List)是有向图的另一种链式存储结构。
- 看成是将有向图的邻接表和逆邻接表结合起来得到的(正向+逆向)
- 十字链表中的每个节点对应图中的一条边
- 只能存储有向图
画法:数据结构|十字链表|简单粗暴零失误画出十字链表_哔哩哔哩_bilibili
步骤:1、画出度 2、画入度 3、画自己

- Tail Vertex(弧尾):表示边的起点。
- Head Vertex(弧头):表示边的终点。
- Head Link(头链域):指向与当前弧头相同的下一个节点(指向同一个终点的下一条边)。
- Tail Link(尾链域):指向与当前弧尾相同的下一个节点(从同一个起点出发的下一条边)。
- Info(信息域):存储该边的相关信息,例如权重
(5)邻接多重表 (存储无向图)
有多少个边,就有多少个结点(邻接多重表中的每个节点对应图中的一条边)
邻接多重表进阶版画法 三步秒杀:邻接多重表进阶版画法 三步秒杀 数据结构_哔哩哔哩_bilibili
- 邻接多重表画法不唯一
- 只能存储无向图


(6)三元组(边集数组 存储有向图- 稀疏矩阵)
边集数组是由两个一维数组构成。一个是存储顶点的信息;另一个是存储边的信息,这个边数组每个数据元素由一条边的起点下标(begin)、终点下标(end)和权(weight)组成


(5)习题



(5)总结
十字链表在查找边时效率较高,但空间利用率较低
邻接多重表在查找顶点时效率较高,但查找边时效率较低。

2、图的遍历——广度遍历、深度遍历(BFS、DFS)


V表示顶点数,E表示边数。
(1)广度遍历(BFS)

(2)深度遍历(DFS)

3、最小生成树(普利姆算法、克鲁斯卡尔算法)
最小生成树(Kruskal(克鲁斯卡尔)和Prim(普里姆))算法动画演示:最小生成树(Kruskal(克鲁斯卡尔)和Prim(普里姆))算法动画演示_哔哩哔哩_bilibili
- 普利姆算法:加点法
- 克鲁斯卡尔算法:加边法
普利姆算法(Prim's Algorithm)和克鲁斯卡尔算法(Kruskal's Algorithm)都是贪心算法的经典应用。


(1)普利姆算法——贪心

(2)克鲁斯卡尔算法——贪心

(1)总结


4、最短路径(弗洛伊德算法、迪杰斯特拉算法)



(1)弗洛伊德算法——动态规划
动态规划——背包问题、皇后问题

(2)迪杰斯特拉算法——贪心

(2)总结

BCBC
5、拓扑排序(AOV网)——有向无环图
在计算机科学和网络领域,拓扑结构是指将网络中的计算机和通信设备抽象为点,把传输介质抽象为线,由点和线组成的几何图形来描述计算机网络的连接和结构关系。
拓扑排序是一种对有向无环图(DAG)进行排序的算法——常见应用:
1. 任务调度
2. 课程安排
不是环就可以!
- 拓扑序列唯一并不能唯一确定该图


(0)有向无环图
- DAG(有向无环图,Directed Acyclic Graph)
- 能拓扑排序的图,一定是有向无环图
- 有向无环图,一定能拓扑排序

(0)有向无环图——判断是否有环
如何判定一个图是否是有向无环图呢?
检验它是否可以进行拓扑排序即可

(3)有向无环图——存储算术表达式(习题)

(1)拓扑排序(拓扑序列)

拓扑排序:记录出度(邻接表)【选入度为0的开始,踢出队列】
(2)逆拓扑排序(※——易考)
逆拓扑排序——DFS算法(反正输出的结果:和拓扑排序结果相反)

逆拓扑排序:记录入度
拓扑排序:记录出度

(2)总结

6、关键路径 (最长路径)

- 有序拓扑序列的图的邻接矩阵是三角矩阵(有序是人为的)
- 只有缩短才会导致出现不同的关键路径(缩短的不是所有关键路径上的公共边)
- DAG(有向无环图)最长路一定是关键路径,因此画好图后直接找最长路即可
(0)AOE网

- 从源点到汇点的有向路径可能有多条,所有路径中,具有最大路径长度的路径称为关键路径,而把关键路径上的活动称为关键活动
- 完成整个工程的最短时间就是关键路径的长度,若关键活动不能按时完成,则整个工程的完成时间就会延长
(1)最早完成时间 & 最晚完成时间


(1)关键路径 & 关键活动

关键路径的特点
①缩短关键活动的时间,可以缩短整个工程的工期。但也不能任意缩短关键活动,因为一旦缩短到一定的程度,该关键活动就可能会变为非关键活动
②网中的关键路径并不一定唯一,对于有几条关键路径的网,只提高一条关键路径上的关键活动速度并不能缩短整个工程的工期。加快那些包括在所有关键路径上的关键活动才能更有效地达到缩短工期的目的。
(1)关键路径 & 关键活动——如何计算


(1)总结

(1)练习


六、第六章——查找——P260

1、平均查找长度

1、顺序查找、折半查找
(1)顺序

(1)折半查找——代码一定要会(※※※※※)
选取中间结点时,既可以采用向下取整,又可以采用向上取整(每次查找的取整方式必须相同)
折半查找树、红黑树、B树,为了便于对他们的实现和理解,引入了n+1个外部叶结点(也就是空节点)
- 折半查找判定树一定是平衡二叉树(注意树高)
- 折半查找判定树一定是二叉排序树(失败结点个数)
- 折半查找,又称“二分查找”仅适用于有序的顺序表


(1)折半查找——特点1(习题)
- 有序
- 可以向前和向后遍历

(1)折半查找——特点2(习题)
- 因为选取中间结点时,既可以采用向下取整,又可以采用向上取整
- 所以,子树会统一向左偏,或者向右偏(自己画图看看)
- 向上取整——左边比右边多一个(向右偏)
- 向下取整——左边比右边少一个(向左偏)



(1)分块查找(索引顺序查找)
分块查找又称索引顺序查找,它吸取了顺序查找和折半查找各自的优点,既有动态结构,又适于快速查找。

虽然索引表占用了额外的存储空间,索引查找也增加了一定的系统开销,但由于其分块结构,使得在块内查找时的范围较小,因此与顺序查找相比,分块查找的总体效率提升了不少。
(1)附——跳表(多个链表)
跳表使用的是空间换时间的思想,通过构建多级索引来提高查询效率,实现基于链表的“二分查找”
跳表的空间复杂度是 O(n),不过跳表可以通过改变索引策略,动态的平衡执行效率和内存消耗。
跳表是一种动态的数据结构,支持快速的查找、插入和删除操作,时间复杂度是 O(logn)。
跳表查找任意数据的时间复杂度为O(logn)
跳表插入的时间复杂度为:O(logn),支持高效的动态插入。
跳表的删除操作时间复杂度为:O(logn),支持动态的删除。
跳表是通过随机函数来维护“平衡性”。
性质:
跳表由很多层结构组成,level是通过一定的概率随机产生的;
每一层都是一个有序的链表,默认是升序 ;
最底层(Level 1)的链表包含所有元素;
如果一个元素出现在Level i 的链表中,则它在Level i 之下的链表也都会出现;
每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。


2、树形查找(平衡二叉树、二叉查找树、红黑树、B树、B+树)
查找树——元素都在叶子结点上
(1)二叉排序树(BST)(二叉搜索树)
- 二叉排序树的查找效率,主要取决于树的高度
- 极端情况下,就会变成链表的样子



时间复杂度默认指最坏的情况下

(1)二叉排序树(BST)(二叉搜索树)——删除操作(重点)

(2)平衡二叉树(也可以是搜索树、排序树)——左旋、右旋(LL、LR、RR、RL)
AVL树(自平衡)、红黑树(自平衡)…
LL——右旋
RR——左旋
LR——先左旋、再右旋
RR——先右旋、再左旋

LL——右转
RR——左转
LR——左转——LL——右转
RL——右转——RR——左转




(3)红黑树——考前看看!!!(12字真言)
红黑树 - 定义, 插入, 构建_哔哩哔哩_bilibili
为什么这里要把空结点当成叶子结点呢?
因为为了利用红黑的特性——加上空节点,就可满足【黑路同】
最长路径不超过最短路径的两倍(通过最长路径去找红色结点)一黑一红(黑红相间的路径)
为什么他的查询效率比不过平衡二叉树(AVL)?
因为红黑树是平衡二叉树——但在树高方面没有AVL严格
但是他们的CRUD,都是log2n(这里没有C)
为什么插入的结点默认是红色?
因为这样,也只可能破坏了【不红红】 or 【黑路同】
被破坏了之后,如何调整?(有三种情况)
在调整的时候,可能需要多次旋转,但只需要一次变色





C++中的map、set是通过红黑树(Red-Black Tree)实现的
(4)B树
B树(B-树) - 来由, 定义, 插入, 构建_哔哩哔哩_bilibili (定义、插入、调整,请看视频)
- 折半查找树、红黑树、B树,为了便于对他们的实现和理解,引入了n+1个外部叶结点(也就是空节点)
- 外部结点 = 失败结点 = 叶子结点 = 空结点 (意味着查找失败)
- 有些教材称呼不一样!这里要注意!408中的将B树的叶结点定义为最底层的终端结点
B树——注意:
- M阶B树 = M叉B树 ——(多叉平衡搜索树)二阶B-树是一棵满二叉树
- 叶子结点是空的(就是失败结点)408真题中却常将B树的叶结点定义为最底层的终端结点。
- 叶子结点数 = 关键字个数+1
- 终端结点(含有关键字)
- 每一层的结点数与分支数相关(等比数列,3阶树-就是成3的比例)
- 关键字的个数一般用代入法~


3阶B树:——直接记忆分支的公式就行了,元素就是分支数-1
最多3个分支,2元素
最少2个分支,1元素
5阶B树:
最多5个分支、4个元素 (元素多了叫上溢出)
最少3个分支、2个元素 (元素少了叫下溢出)
(4)B树 ——删除
删除操作——最终都会转换到删除【终端结点】(必然引起叶子结点变化)
删除操作——找到对应的【终端结点】左子树中最大的,右子树最小的(左大、右小)
缺钱了,先找兄弟借,兄弟合起来(合并)找爹借钱
如果导致爹缺钱了,爹去找他的兄弟借…以此类推

(4)B树 ——习题


DADDBBA
(5)B+树 (B树的拓展)
为什么叫B+树(方便记忆,因为他的结点关键字数比B树多1个)
5阶B+树:
最多5个分支、5个元素 (元素多了叫上溢出)
最少3个分支、3个元素 (元素少了叫下溢出)
B+树:
- 有两个头指针(一个指向根节点,用于随机查找,一个指向叶子结点,用于顺序查找)
- 可以结合两个头指针,进行范围查找(先通过根节点找到开头的叶结点,然后顺序查找)
- M个分支 = M个叉B+树 (5阶B+树 = 最多有5个叉、最少3个叉,这个和B树一样)
- 一个结点的子树个数 = 当前结点的关键字个数(根节点2个关键字 = 2个分支)
- 所有结点的子树个数 = 所有结点的关键字个数(下图8个分支 = 8个子树 = 8个关键字)
- 叶子结点包含(全部关键字+记录指针)

B+树作为【索引文件】存储在硬盘中——实际应用当中,关键字不一定是ID【操作系统要学】
【索引文件的特点】一个表的关键字可以是其他的,可以是年龄、姓名等
【索引文件的特点】一个表可以有多个索引(MySQL中也有说)
(5)B+树 & B树——(对比、总结)
相同点:
- 叶子结点都在同一层(最底层)
- 分支数相同——最多有m个分支,最少有m/2向上取整(注意:关键字个数不一样!)




MangoDB使用的是B树进行索引(不用从根节点开始访问,单次查询速度更快)
MySQL关系型数据库采用B+树进行(区间遍历和全部遍历较为频繁,方便进行查询)
(5)附——B+树(存储在磁盘中)
- B+树会更矮,查询起来更高效
- 一个节点包含了多个数据域,适应于操作系统成块访问磁盘的特性,可以一次读取多个节点的数据。
- 最好高度不要超过3层!(这样查询效率比较高)
为什么MySQL单表数据量不要超过两千万?
- 因为在MySQL 采用了索引组织表的形式组织数据,基于B+树结构的索引
- 假设一条行记录占用的空间大小为1K,那么一个数据页就可以存储15条行记录,即 Y=15;
- 假设 B+树是两层的:则 N=2,即 M=1280的(2-1)次方 * 15 ≈ 2w
- 假设 B+树是三层的:则 N=3,即 M=1280的2次方 * 15 ≈ 2.5 kw;
- 假设 B+树是四层的:则 N=4,即 M=1280的3次方 * 15 ≈ 300亿
综上所述,建议单表数据量大小在两千万。
当然这个数据是根据每条行记录的大小为 1K 的时候估算而来的,而实际情况中可能并不是这个值,
所以这个建议值两千万只是一个建议,而非一个标准。
(1)附——倒排索引(文件查找、搜索引擎)
(1)附——前缀树
前缀树、字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。
利用apple,app,api,banana,bus这5个单词来举例子
构建出一颗前缀树,这颗前缀树就像下图这样:

(1)附——后缀树(Suffix Tree)
它在数据库中被用于高效的文本搜索(能快速解决很多关于字符串的问题)
- 可以在大量文档集合中快速找到一个搜索词的所有出现位置
- 后缀树的概念最早由Weiner于1973年提出
- 既而由McCreight在1976年和Ukkonen在1992年和1995年加以改进完善

(1)附——R树(B树的拓展)空间索引结构
R树是B树 向多维空间发展的另一种形式:
- 它将对象空间按范围划分,每个结点都对应一个区域和一个磁盘页
- 非叶结点的磁盘页中存储其所有子结点的区域范围,非叶结点的 所有子结点的区域都落在它的区域范围之内;
- 叶结点的磁盘页中存储其区域范围之内的所有空间对象的外接矩形。R树是一种动态索引结构
- 允许快速空间查询,并广泛被用于PostGIS、MongoDB和Elasticsearch等空间数据库

(1)附——LSM-Tree(Log Structured Merge Tree)
LSM-Tree(Log Structured Merge Tree)是很多高度可扩展的分布式 KV 类型数据库的底层数据结构

3、散列查找(散列查找 / hash表 / 散列表)——P310
- 对哈希表一般只做查找和新增操作,如果要做删除操作最好是额外开一个bool类型的数组来打标记(逻辑删除)
散列函数(也称哈希函数):
一个把查找表中的关键字映射成该关键字对应的地址的函数,
记为Hash(key)=Addr(这里的地址可以是数组下标、索引或内存地址等)。
散列函数需要设计,尽量减少这样的冲突;但是冲突不可避免,所以要设计好处理冲突的方法。
散列表(也称哈希表):
根据关键字而直接进行访问的数据结构。
散列表建立了关键字和存储地址之间的一种直接映射关系
理想情况下,对散列表进行查找的时间复杂度为0(1),即与表中元素的个数无关。

(1)散列函数(哈希函数)——4种
构造散列函数时,必须注意以下几点:
1)散列函数的定义域必须包含全部关键字,而值域的范围则依赖于散列表的大小。
2)散列函数计算出的地址应尽可能均匀地分布在整个地址空间,尽可能地减少冲突。
3)散列函数应尽量简单,能在较短的时间内计算出任意一个关键字对应的散列地址。
4种方法:
1.直接定址法 ——(直接取关键字的某个线性函数值为散列地址)
H(key)= key 或 H(key)= a * key + b
优点:
计算最简单,且不会产生冲突
合关键字的分布基本连续的情况
缺点:
关键字分布不连续,空位较多,则会造成存储空间的浪费
2.除留余数法
H(key) = key % p ——关键是选好p,使得每个关键字通过该函数转换后等概率地映射到散列空间上
的任意一个地址,从而尽可能减少冲突的可能性
3.数字分析法
4.平方取中法
(1)冲突处理(2种方法)
散列查找(Hash表、散列表)是一种数据结构,用于实现键值对之间的映射关系。
- 拉链法(要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。)
- 线性探测法(一定要保证tableSize大于dataSize),我们需要依靠哈希表中的空位


在Java中,HashMap和HashSet等集合类使用散列表来存储元素。当散列表中的某个桶(bucket)中的链表长度达到一定阈值时,为了提高搜索效率,Java会将链表转换为红黑树
(1)冲突处理(开发地址法)
开放定址法——开放表中可存放新表项的空闲地址
- 开放定址——不能随便删除散列表中的某个元素,否则可能会与导致搜索路径被中断
- 开放定址——删除做法是在要删除的地方做删除标记(逻辑删除)
- 开放定址——删除的副作用是表面上看起来散列表很满,实际上有许多位置未利用

解决冲突(碰撞)的方法:
- 线性探测法 【线性探测再散列】(看表中的下一个元素)
- 平方探测法 【二次探测】(缺点是不能探测到散列表上的所有单元,但至少能探测一半单元)
- 再散列法(再哈希法,双散列法)——当使用第一个哈希函数计算出的哈希值对应的存储位置已经被占用时,就利用第二个哈希函数计算出的哈希值来寻找下一个可能的存储位置,以此类推,直到找到一个空的位置为止

线性探测法——造成聚集:
可能使第i个散列地址的同义词存入第i+1个散列地址,这样本应存入第i+1个散列地址的元素就争夺第i+2个散列地址的元素的地址从而造成大量元素在相邻的散列地址上聚集(或堆积)起来,大大降低了查找效率。
- 同义词之间或非同义词之间发生冲突
(1)冲突处理(拉链法)——(数组+链表)
- 链表判断指针为空则不计入比较次数(注意!)
- 链表法的元素删除——确确实实把结点删了(不是逻辑删除)


(1)ALS成功 & ALS失败 & 装填因子 (记得复习!)
散列表的查找效率取决于3个因素:散列函数、处理冲突的方法、装填因子
装填因子a =(元素个数n / 表长m)
散列表的装填因子一般记为α,定义为一个表的装满程度(这个表格装得有多满)
散列表的平均查找长度依赖于散列表的装填因子a,而不直接依赖于 n 或 m


1、注意哈希函数(他到桶的范围)
2、线性探测的逻辑删除
3、哈希函数中,空结点要不要算!
4、链表的多少

(1)存储效率(空间利用率)
- 存储效率通常是指数据结构能够有效利用内存的能力
- 它涉及到实际存储的数据量与理论上最大可能存储数据量的比例
- 例:
- 如果一个哈希表能存储100个元素,但只填充了50个,那么其存储效率就是50%,装填因子是0.5
- 他就是在装填因子的基础上,乘了一个百分比
ABC都不变

(1)总结


DDC
七、第七章——排序


自制-排序动画:冒泡排序与快速排序-动画演示_哔哩哔哩_bilibili
1、插入排序 & 希尔排序 (折半插入排序)
直接插入排序动画

希尔排序动画

插入排序:
插入排序——n个元素,在最坏情况的比较次数是n(n-1)/2
插入排序——n个元素,在最好情况的比较次数是n-1
插入排序——最好情况可以到达线性情况(冒泡、直插可以到达线性!)

折半插入排序:
- 在插入的时候,不是从头开始进行比较,而是从中间开始比较!
- 与原始的方法,他们的不同点是:比较次数不一样!
- 时间复杂度还是O(N2)



2、冒泡排序 & 快速排序
冒泡排序动画:

快速排序动画:

- 快速排序——真正消耗空间的就是递归调用(因为每次递归就要保存一些数据)
- 快速排序——空间复杂度取决于分划基准的选择,每次都选在中间则退化为冒泡
- 快速排序——是一种原地排序,只需要一个很小的栈作为辅助空间
最坏的情况时间复杂度O(n^2):
看枢轴(pivot)的选择策略
1)数组已经是正序排过序的。
2)数组已经是倒序排过序的。
3)所有的元素都相同(1、2的特殊情况)
时间复杂度 & 空间复杂度
快速排序——平均时间复杂度O(nlog2n)和空间复杂度O(log2n)
快速排序——最坏时间复杂度O(n^2)和空间复杂度O(n)
快速排序——平均空间复杂度O(1)——常数级


双向冒泡排序——注意排序次数

3、选择排序 & 堆排序
选择排序动画:

堆——完全二叉树(不是二叉排序树,兄弟之间的顺序有问题)
堆——适合用来排序(但不适合用来查询)查找时它是无序的
堆——升序采用大顶堆,降序采用小顶堆
特点:
复杂度和顺序无关、原地排序、不稳定、不消耗空间、
不是排序树(不适合查找)、是完全二叉树,
删除会转换为删除叶子结点(类似B树),插入是放屁股后面开始
- 创建堆的时候——要和兄弟比较大小(再和爹比较)
- 插入后——调整堆的时候——不用和兄弟比较大小(只用和爹比较)
- 删除后——调整堆的时候——要和兄弟比较大小(再和爹比较)
小根堆与大根堆的区别
- 小根堆是一种特殊的堆数据结构,在小根堆中,每个节点的值都小于等于其子节点的值。
- 由于每个节点的值都小于等于其子节点的值,因此根节点(即最小值)总是在堆顶部。
- 大根堆是一种特殊的堆数据结构,在大根堆中,每个节点的值都大于等于其子节点的值。
- 由于每个节点的值都大于等于其子节点的值,因此根节点(即最大值)总是在堆顶部。
- 在小根堆中,最小值总是在堆顶,而在大根堆中,最大值总是在堆顶。这就是小根堆和大根堆的主要区别
时间复杂度
构建堆——时间复杂度O(n)
调整堆——时间复杂度O(log2n)
堆排序——最好、最坏、平均O(nlog2n)——复杂度和序列无关
堆排序——空间复杂度:O (1)
堆排序——原地排序算法(不需要额外的存储空间来辅助排序过程,除了原数组本身)
堆排序——兼具选择排序和插入排序的优点


完全二叉树——构建堆——堆调整


删除堆元素:

4、归并排序 & 外部排序 (一个)
归并排序动画

- 归并排序是建立在归并操作上的一种有效,稳定的排序算法
- 该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
- 将已有序的子序列合并,得到完全有序的序列(即先使每个子序列有序,再使子序列段间有序)
- 归并排序可用于链式结构,且不需要附加存储空间,但递归实现时仍需要开辟相应的递归工作栈。
- 用顺序表实现归并排序时,需要和待排序记录个数相等的辅助存储空间,所以空间复杂度为 O(n)
合并——时间复杂度、空间复杂度
归并排序——总的平均时间复杂度为O(nlogn)
归并排序——总的平均时间复杂度 = 每次合并操作的平均时间复杂度为O(n) * 完全二叉树的深度为|log2n|
归并排序——最好、最坏、平均时间复杂度均为O(nlogn)
归并排序——空间复杂度O(N)
合并问题:(数组长度分别为 m 与 n, 合并成一个长度位 m+n 的有序数组)
最好情况下:比较次数为 min{m, n}
Java中Arrays.sort()采用了一种名为TimSort的排序算法,就是归并排序的优化版本。
外部排序:
- 数据元素太多,无法一次全部读入内存
- 排序过程中需要多次进行内存外存之间的交换


5、基数排序 & 计数排序(一个)
基数排序动画

- 下图中,建立了10个队列
- 遵循“先进先出”原则

8、内部排序(总结)

9、外部排序
- 外部排序指的是大文件的排序
- 待排序的记录存储在外存储器上待排序的文件无法一次装入内存
- 需要在内存和外部存储器之间进行多次数据交换,以达到排序整个文件的目的。
外部排序最常用的算法是多路归并排序,即将原文件分解成多个能够一次性装入内存的部分分别把每一部分调入内存完成排序。然后,对已经排序的子文件进行归并排序
详细内容:数据结构——外部排序-优快云博客
- 外部排序总时间=内部排序时间+外存信息读/写时间+内部归并时间
- 由于外存的读写时间远大于内部排序、内部归并时间,因此要减少IO次数
9、外部排序——归并排序(传统方法)
外部排序步骤
1、生成初始归并段
按照可用内存的大小分批次将外存上的文件分成若干子文件,将其依次读入内存并利用有效的内部排序方法对它们进行排序得到归并段(有序的子文件),在对归并段进行逐趟归并,使其逐渐由小增大,直到获得整个有序文件
2、将初始归并段,进行归并
对m个初始归并段进行k路平衡归并时,归并次数s = logkm
如何减少归并次数(趟数)?
增加k,或者减少m
比如:8个归并段,进行2路排序,需要3趟归并(如果进行4路排序,2趟就可以了)
优化方法
1、降低归并次数,来减少总体I/O次数,降低归并次数可以通过采取多路归并操作(败者树)
2、减少初始归并段的个数,使用置换选择排序(突破内存空间的限制)
注意点
- 内存的缓冲区空间决定了初始归并段的个数(初始归并段个数=所有数据N/内存缓冲空间向上取整)
- 总体I/O操作:2*总体文件块数+2*总体文件块数*归并次数(趟数)
练习1
有一文件含有20个记录(每个记录有100个值),每个记录占用1个磁盘块,内存缓冲可容纳200个值
产生多少个归并段?(IO为多少?)
内存缓冲区可容纳2个记录,即2个磁盘块
20/2 = 10个归并段(2个记录合成1个归并段)
20/1 * 2 = 40次 (期间,读了20次磁盘块,写了20次磁盘块)
若进行2路归并,归并次数为多少?
归并次数s = log210 = 4次
总体IO次数是多少?
2*总体文件块数+2*总体文件块数*归并次数(趟数) = 2*20 + 2*20*4 = 200 次
练习2
文件共10000个记录,每个物理块可容纳200个记录,内存缓冲区可容纳5个物理块,
产生多少个归并段?(IO为多少?)
5个物理块可容纳1000个记录,10000/100 = 10个初始归并段,10000/200 * 2 = 100访存次数

9、外部排序——败者树
败者树是选择排序的一种变体,可视为一棵完全二叉树。
败者树是胜者树的一种变体,它也是一棵完全二叉树。和胜者树不同的是,败者树的节点存储的是败者。
- 使用败者树后,内部归并的比较次数与k无关了。
- 只要内存空间允许,增大归并路数k将有效地减少归并树的高度,从而减少I O次数(提升速度)
为什么要选择败者树?
- 采用败者树可以简化重构的过程。
- 在用胜者树的时候,每个新元素上升时,首先需要获得父节点,然后再获得兄弟节点,然后再比较。
- 在使用败者树的时候,每个新元素上升时,只需要获得父节点并比较即可。
- 所以总的来说,减少了访存的时间。(其实现在程序的主要瓶颈在于访存了,计算倒几乎可以忽略不计了。)

升序排序(从小到大),那么就先找最小的

9、外部排序——赢者树(拓展)
有 n 个选手的一棵赢者树是一棵完全二叉树,它有 n 个外部结点和 n - 1 个内部结点,每个内部结点记录的是在该结点比赛的赢者,根结点保存的是所有输入序列中的最小(或最大)元素
- 在最小赢者树(min winner tree)中,分数小的选手获胜。
- 在最大赢者树(max winner tree)中,分数大的选手获胜。
- 在分数相等,即平局的时候,左孩子表示的选手获胜。

赢者树的一个优点:
当一名选手的分数改变时,修改竞赛树比较容易。在一棵 n 个选手的赢者树中,当一个选手的分数发生变化时,需要修改的比赛场次介于 1 到 ⌈log2n⌉ 之间,因此,赢者树的重构需耗时 O(logn) 。
此外, n 个选手的赢者树可以在 Θ(n) 时间内初始化,方法是沿着从叶子到根的方向,在内部结点进行 n - 1 场比赛。也可以采用后序遍历来初始化,每访问一个结点,就进行一场比赛。

赢者树:保留胜利者,便于快速提取当前最优元素,并在合并时保持高效。
败者树:保留被淘汰者,在更新时具有一定的灵活性
9、外部排序——选择置换排序(内存工作区)
通过置换选择排序可以突破内存空间的限制,减少初始归并段的个数

9、外部排序——哈夫曼树(最佳归并树)
由长度不等的归并段,进行多路平衡归并,需要构造最佳归并树
- 按照归并排序,会产生一个归并树,会发现总的I/O磁盘总数会刚好等于这个树的WPL两倍
- 为了减少I/O次数可以改变原有归并策略,让这个二叉树的WPL达到最小。
- 如果使用m路归并就是m叉树,要使WPL最小那么就需要使用哈夫曼树


9、外部排序——总结
- 归并路数k并不是越大越好。归并路数k增大时,相应地需要增加输入缓冲区的个数。
- 若可供使用的内存空间不变,势必要减少每个输入缓冲区的容量,使得内存、外存交换数据的次数增大。当k值过大时,虽然归并趟数会减少,但读写外存的次数仍会增加

9、外部排序——习题

归并排序习题

选择置换排序习题

最佳归并树习题

1、排序算法(总结)——并行处理(3个)
具有分而治之的特性:
快速排序、归并排序、双调排序
内部排序算法是否并行执行
- 直接插入排序:需要基于上次排序好的序列继续排序,不能并行执行。
- 折半插入排序:折半插入排序需要在已排序好的部分找到正确的插入位置,不能并行执行。
- 希尔排序:无法并行执行,需要基于上一次已经排序好的序列排序。
- 冒泡排序:每趟对未排序的元素进行一趟处理,无法并行执行。
- 快速排序算法:快速选择排序每趟划分子序列互不影响,可以并行执行。
- 简单选择排序:不可以并行执行,因为需要在上一个排序序列的基础上找到次大(次小)的元素。
- 堆排序:可以并行执行,因为根结点的左右子树构成的子堆在执行过程中互不影响。
- 归并排序:各个归并段可以并行执行。
- 基数排序: 基数排序每趟需要利用前一趟已排序好的序列,无法并行执行。
1、排序算法(总结)——初始序列(影响)
冒泡、快排:
快速排序 的排序趟数就是它的递归深度。
当 快排 的数据是有序时候,会退化为冒泡,所以【快排趟数】也与初始序列顺序有关
直接插入排序
比较次数 与序列初态 有关 。初始序列基本有序时,移动元素最少(效率最高)
选择排序
元素总移动次数 与初始状态 有关。
比较次数 与序列初态 无关 的算法是:二路归并排序、简单选择排序、基数排序
比较次数 与序列初态 有关 的算法是:快速排序、直接插入排序、冒泡排序、堆排序、希尔排序
排序趟数 与序列初态 无关 的算法是:直接插入排序、折半插入排序、希尔排序、简单选择排序、归并排序、基数排序
排序趟数 与序列初态 有关 的算法是:冒泡排序、快速排序
四种排序方法的算法复杂度与数组的初始状态无关:
一堆(堆排序)乌龟(归并排序)选(选择排序)基(基数排序)友
1、排序算法(总结)——链式存储(替换)
- 直接插入排序:换为链式存储时间复杂度仍为O(n)。
- 折半插入排序:利用顺序存储随机访问的特性,不能使用链式存储。
- 希尔排序:利用顺序存储随机访问的特性,不能使用链式存储。
- 冒泡排序:可以使用链式存储,时间复杂度仍为O(n)。
- 快速排序算法:一般不使用链式存储。
- 简单选择排序:可以更换为链表存储。时间复杂度仍然为O(n^2)
- 堆排序:利用顺序存储随机访问的特性,不能使用链式存储。
- 归并排序:可以使用链表存储,在合并两个有序子链表时,创建一个新的链表来保存合并后的结果即可。
- 基数排序:就是用链式存储结构实现的。
1、排序算法(总结)——稳定性 & 复杂度
408不考桶排序和计数排序:
结合咸鱼的——我的口诀是插帽龟,基你太稳
插帽龟、统计鸡——稳定(其他都是不稳定)
选帽插,有点方(n平方)
恩老哥,快归队(nlogn、快排、归并、堆)


附——知识点汇总记忆
1、排序算法(10种)




计算机算法中,哪些用了分而治之的思想?
归并排序、 快速排序、堆排序、二分查找
| 中文名称 | 英文名称 | 平均时间复杂度 | 空间复杂度 | 稳定性 |
| 插入排序 | Insertion Sort | O(n^2) | O(1) | 稳定 |
| 希尔排序 | Shell Sort | O(n log^2 n) | O(1) | 不稳定 |
| 冒泡排序 | Bubble Sort | O(n^2) | O(1) | 稳定 |
| 快速排序 | Quick Sort | O(n log n) | O(log n) | 不稳定 |
| 选择排序 | Selection Sort | O(n^2) | O(1) | 不稳定 |
| 堆排序 | Heap Sort | O(n log n) | O(1) | 不稳定 |
| 基数排序 | Radix Sort | O(kn) | O(n + k) | 稳定 |
| 归并排序 | Merge Sort | O(n log n) | O(n) | 稳定 |
插帽龟,基你太稳
2、数据结构(10种)

3、排序算法(最容易忘记的东西——考前必看)
- B树——性质+插入+删除
- B+树——性质
- 红黑树性质
- 拓扑排序(AOV、逆拓扑排序)
- 关键路径(AOE)
3、C语言基本语法
int a[10]= { 1, 2, 3 };
int a[10]= { 0 };
//方式一 结构体初始化
typedef struct stu
{
char name[20];
int age;
char sex;
} student;
student stu1;
附——解决了一些疑惑
1、C语言——结构体【内存大小】及【内存对齐】【边界对齐】
学习文章:c语言中关于结构体所占内存大小及内存对齐详解_结构体类型占几个字节-优快云博客
这里的知识点——与计算机组成原理中的【边界对齐】一样!
C语言中——unsigned若省略后一个关键字,大多数编译器都会认为是unsigned int
结构体内变量的字节对齐需要符合一下三种规则:
- 结构体变量的首地址能够被其最宽基本类型成员大小所整除
- 结构体每个成员相对结构体首地址的偏移量(offset)都是自身有效对齐字节数的整数倍
- 结构体内变量的自身有效对齐字节数为自身对齐字节数与系统对齐字节数的较小者(即两者中的最小值);结构体的大小为成员最大自身对齐字节数的倍数

不对齐,会怎么样?

- 虽然不对齐可以减少空间开销,但访问c1的时候,就需要两次访问(并拼接数据),消耗更多时间
- 内存对齐——空间换时间

缓存为啥也要对齐?(附)
因为32位架构里所有的CPU内部的总线和寄存器包括缓存全是32位,每次访问都是32位为最小单位,所以如果你需要访问不对齐的32位地址,就只能取两次再拼接了。
那有的小伙伴就会问了,如果本身是64位和32位都兼容的CPU,是不是代表不对齐的内存数据也不会有损失?答案是看情况。CPU既然都有了64位硬件了,大多数时候还是会用这多余的64位硬件给32位做优化的,这样的情况下如果没对齐的32位地址在一个64位对齐的地址内,因为CPU本身一次能取一个64位且对齐的数据,就不用访问内存两次,只是进行拼接移位就好。但如果没对齐的这32位地址也不在一个64位对齐的数据内,CPU就只能访问两次64位,然后拼接出一个32位的数据了。 同样的,这个也是一个简化过的单发射CPU,而实际的多发射的CPU性能更强,位宽也比32和64位宽,也能够在不损失性能的时候处理一些不对齐的数据
1、C语言——各种类型大小(int、short、double)

短整型:short
长整型:long
单精度:float
双精度:double


1、C语言——如何查看数据在内存中的存在形式
1. 打断点,在Debug模式下运行程序
2.当运行到程序时,在右下方显示当前变量的窗口,单击右键,选择加入监视;
3. 然后查看内存,show in memory view
1、C语言——把二进制数和十六进制数赋值给变量
把二进制数和十六进制数赋值给变量——不用变为补码!
这个就是真值!!


1、C语言——如何变成一個可执行文件的?

第一步:main.c à 编译器 à main.s文件 (.s文件就是汇编文件,文件内是汇编代码)
第二步:我们的main.s汇编文件 à 汇编器 à main.obj
第三步:main.obj文件 à 链接器 à 可执行文件exe
四个步骤对应的在linux下的命令
gcc -E main.c -o main.i #预处理,生成main.i文件
gcc -S main.i #编译,生成main.S文件
gcc -c main.S #汇编,生成main.o文件
gcc main.o -o main #链接,生成可执行文件
1、C语言——为什么会有构建工具(Make file)?
我们每次编译,都需要敲一些命令,太麻烦
并且随着代码文件(头文件、库文件)越来越多,手动编译就不太现实了!
我们可以借助一些自动化构建工具:
- 不同语言和不同平台的项目会使用不同的构建工具
- Java——使用Maven或Gradle (清理、编译、测试、运行、打包、安装整个过程)
- WebPack——用于现代 JavaScript 应用程序的静态模块打包工具
- C++——使用CMake(可以指定动态库、静态库)

1、C语言——CMake为什么需要指定动态库、静态库(操作系统要考)
动态库(Dynamic Library):
在CMake中,通过设置BUILD_SHARED_LIBS变量为ON
动态库——是一种在运行时被加载的库文件,
动态库——包含了一组预先编译好的函数和过程可以被多个程序共享
在不同的操作系统中有着不同的文件扩展名:
- Windows:.dll(动态链接库)
- Linux/Unix:.so(共享对象)
- macOS:.dylib(动态库)
动态库的优点
- 节省内存:多个程序可以共享同一个动态库的实例,从而节省内存资源。
- 易于更新:只需要替换动态库文件,而无需重新编译和链接使用该库的应用程序。
- 模块化:应用程序可以动态加载和卸载动态库,从而实现模块化的开发和部署。
静态库(Static Library):
在CMake中,通过设置BUILD_SHARED_LIBS变量为OFF
静态库——是一种包含预编译代码的库文件,它在编译阶段被链接到可执行文件中。
静态库——通常以.a(在Linux/Unix/macOS上)或.lib(在Windows上)为扩展名
- 在编译时被链接到可执行文件中。
- 无需担心依赖问题,因为库代码已经嵌入到可执行文件中。
静态库 vs 动态库
- 静态库:
- 在编译时被链接到可执行文件中。
- 优点:无需担心依赖问题,因为库代码已经嵌入到可执行文件中
- 缺点:更新库时需要重新编译所有依赖该库的可执行文件
- 动态库:
- 在运行时被加载
- 优点:多个可执行文件可以共享同一个库文件,节省内存
- 缺点:需要确保动态库文件存在于运行时的路径中


















 5978
5978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











