



 VisualDL是百度PaddlePaddle团队推出的一款深度学习可视化工具,支持模型训练过程的指标趋势、参数分布、图像、音频、文本、模型结构及高维数据可视化,通过简单集成即可提升模型调试与优化效率。
VisualDL是百度PaddlePaddle团队推出的一款深度学习可视化工具,支持模型训练过程的指标趋势、参数分布、图像、音频、文本、模型结构及高维数据可视化,通过简单集成即可提升模型调试与优化效率。
引言:
当使用PaddlePaddle训练大量深层的神经网络时,开发者希望跟踪整个神经训练过程的信息,例如loss的变化趋势,迭代过程中参数的变化、分布及背后的原因、模型的网络结构等。PaddlePaddle推出的可视化工具VisualDL,只需要以下两个简单步骤,即可更好的调试和优化神经网络的训练过程:
调用Paddle Fluid的模型接口save_inference_model进行模型保存
使用VisualDL提供的命令行工具加载模型,在浏览器中访问
具体应用方式,请听小编为你详细解读:
工具简介
VisualDL由百度PaddlePaddle团队研发,是一个面向深度学习任务设计的可视化工具,与PaddlePaddle一样,VisualDL原生支持Python的使用, 只需要在模型中增加少量的代码,对VisualDL接口进行调用,便可以为训练过程提供丰富的可视化支持。除了PythonSDK之外,VisualDL底层采用C++编写,其暴露的C++ SDK也可以集成到其他框架中使用, 实现原生的性能和定制效果。用户也可以通过对C++SDK进行封装,提供其他脚本语言的SDK。
组件功能
VisualDL 目前支持以下可视化组件:
scalar
histogram
image
audio
text
graph
high dimensional
scalars
用于记录和展示过程中的指标趋势,如准确率或者训练损失,以便观察损失是否正常收敛,又或者用于不同超参数下模型的性能对比等

histogram
用于可视化任何tensor中数值的变化趋势,例如,可以用于记录参数在训练过程中的分布变化趋势,分析参数是否正常训练,有无异常值,分布是否符合预期等

image
可用于查看输入或生成的图片样本,辅助开发者定位问题

audio
可用于播放输入或生成的音频样本,辅助开发者定位问题

text
用于可视化输入或者模型处理完成的文本样本,辅助开发者定位问题

graph
用于可视化模型的网络结构。可帮助分析模型结构是否符合预期

目前VisualDL支持ONNX和Paddle program两种格式的模型文件。对于使用Pytorch/MXNet等框架的用户,可以将模型结构转为ONNX格式后使用VisualDL展示。而对于PaddlePaddle模型文件的展示,VisualDL则支持直接展示。用户只需要进行以下两步操作,即可查看搭建的paddle网络结构是否正确 :
1. 在paddle代码中,调用fluid.io.save_inference_model()接口保存模型
2. 在命令行界面,使用visualdl --model_pb [paddle_model_dir] 加载paddle模型,接着就能在浏览器上查看模型结构图
high dimensional
用于将embedding数据映射到二维/三维展示,从而使数据更加直观,便于开发者理解和分析。例如在文本领域,可以用于分析深度学习与词或者句子的语义建模是否合理。
目前该组件支持PCA/T-SNE两种降维方式
快速体验
开发者如果想要快速体验一下此工具,可以使用下面的命令进行试用
# 安装VisualDL,建议使用anaconda或者virtualenv等环境下 pip install --upgrade visualdl # vdl_create_scratch_log将会自动生成一份测试的log vdl_create_scratch_log # 在localhost:8080上启动一个visualdl服务,该服务加载scratch_log目录中的日志进行展示 visualdl --logdir=scratch_log --model_pb scratch_log/mnist_model.onnx --port=8080 # 访问 http://127.0.0.1:8080
工具安装
VisualDL支持windows/linux/mac等主流平台的安装使用,用户可以通过pip直接进行安装
pip install visualdl
工具使用
VisualDL的使用流程归纳为以下两步:
1. 在模型文件中,调用VisualDL SDK提供的接口,记录日志
2. 使用VisualDL提供的命令行工具,加载日志,在浏览器中查看
为了保证高效的性能,VisualDL 使用了C++实现了日志数据的记录和读取。除了C++ SDK之外,VisualDL同时提供了基于C++ SDK进行封装的Python SDK,用户也可以根据自己的需求,对C++ SDK进行封装,以支持其他语言的SDK。
下面给出Python SDK的使用示例
pythonSDK
下面我们结合PaddlePaddle和VisualDL,以mnist手写数字识别为例,给大家展示下用法:
1. 先导入必要的包
import paddle import paddle.fluid as fluid from visualdl import LogWriter
2. 定义一个函数,用于构建LeNet-5网络
# 构建一个LeNet-5网络 def lenet_5(img, label): conv1 = fluid.nets.simple_img_conv_pool( input=img, filter_size=5, num_filters=20, pool_size=2, pool_stride=2, act="relu") conv1_bn = fluid.layers.batch_norm(input=conv1) conv2 = fluid.nets.simple_img_conv_pool( input=conv1_bn, filter_size=5, num_filters=50, pool_size=2, pool_stride=2, act="relu") predition = fluid.layers.fc(input=conv2, size=10, act="softmax", param_attr = "fc_w")
cost = fluid.layers.cross_entropy(input=predition, label=label) avg_cost = fluid.layers.mean(cost) acc = fluid.layers.accuracy(input=predition, label=label) return avg_cost, acc
3. 定义img和label,构建网络
img = fluid.layers.data(name="img", shape=[1, 28, 28], dtype="float32") label = fluid.layers.data(name="label", shape=[1], dtype="int64") avg_cost, acc = lenet_5(img, label)
4. 获取mnist数据集
train_reader = paddle.batch(paddle.dataset.mnist.train(), batch_size=64)
5. 选择优化器,添加反向图
optimizer = fluid.optimizer.Adam(learning_rate=0.001) optimizer.minimize(avg_cost)
6. 设置运行环境
place = fluid.CPUPlace() feeder = fluid.DataFeeder(feed_list=[img, label], place=place) exe = fluid.Executor(place)
7. 添加visualdl组件
log_writter = LogWriter("./vdl_log", sync_cycle=10) with log_writter.mode("train") as logger: # 分别用两个scalar来记录loss和accuracy的趋势 scalar_loss = logger.scalar(tag="loss") scalar_accuracy = logger.scalar(tag="accuracy") # 用histogram来记录fc层的参数分布变化趋势 histogram = logger.histogram(tag="histogram", num_buckets=50)
8. 初始化参数
exe.run(fluid.default_startup_program()) step = 0 epochs = 5 param_name = "fc_w"
9. 开始训练
for i in range(epochs): for batch in train_reader(): cost, accuracy, param = exe.run( feed=feeder.feed(batch), fetch_list=[avg_cost.name, acc.name, param_name]) step += 1 # 将数据写入记录中 scalar_loss.add_record(step, cost) scalar_accuracy.add_record(step, accuracy) histogram.add_record(step, param.flatten()) print("epoch %d: step %d, acc is %.2f%% and loss is %.2f" % (i, step, accuracy * 100, cost)) # 保存模型到model_save目录中,接着可以用visualdl --model_pb model_save来加载该模型fluid.io.save_inference_model(dirname = "model_save", feeded_var_names = [img.name], target_vars = [avg_cost, acc], executor = exe)
10.训练完成后,执行下面的命令,通过命令行启动VisualDL服务
visualdl --logdir "vdl_log" --model_pb "model_save"
11.在浏览器打开localhost:8040,选择METRICS查看accuracy和loss的变化趋势

12.切换GRAPHS,查看模型结构图
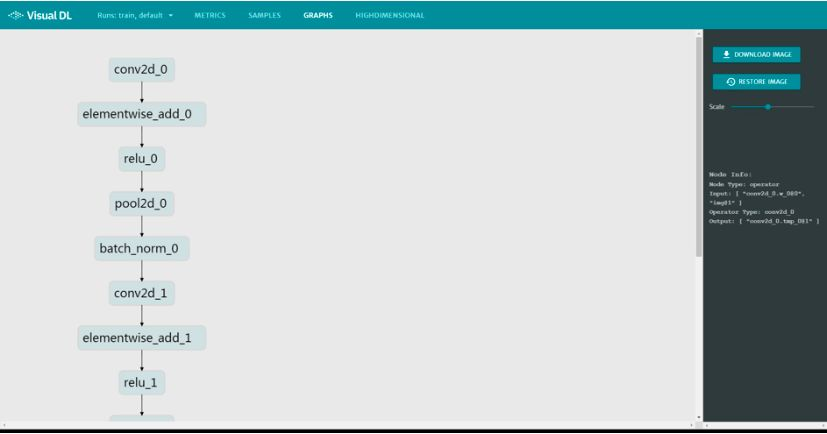
更多参数:
在执行完上述演示后,通过命令行启动VisualDL服务
visualdl --logdir "vdl_log" --model_pb "model_save"

board还支持以下参数
--host 设定IP --port 设定端口 -m / --model_pb 指定 ONNX 格式的模型文件或者paddle模型文件 -L / --language 指定界面使用的语言,目前支持en和zh两种,默认为en
举个例子,使用下述命令,将在192.168.0.2:8888上启动一个VisualDL的服务,前端页面以中文展示(注意,这里的192.168.0.2只是示例,实际使用过程要换为实际ip)
visualdl --logdir "vdl_log" --model_pb "model_save" --host 192.168.0.2 --port 8888 --language zh
详细的选项内容,可以通过以下命令查看
visualdl -h
如果想在线体验, 可以在Baidu AI Studio上遵照示例工程的步骤, 运行并观察效果:
http://aistudio.baidu.com/aistudio/#/projectDetail/35249
进入后fork这个项目, 点击运行项目即可. 无需准备任何代码或环境配置.

总结:
VisualDL作为深度学习的可视化工具,具有功能全面、易集成、易使用等优势,引用一位用户的评价:“像玩具一样易用,像工具一样有用”。随着版本的开发,我们会不断优化已有的功能,同时会加入更多与PaddlePaddle深度结合的功能,敬请期待~
更多了解,请登录:
https://github.com/PaddlePaddle/VisualDL




















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









