




多模态生成大模型是一类能够同时创造和合成多种数据形式的人工智能系统。这类模型基于前沿的生成式深度学习架构,不仅能理解跨模态信息,还能实现多形式内容的高质量生成与融合。近些年来,文生视频多模态大模型展现出强大的表现力,通过跨模态对齐与协同创作,可生成更丰富、连贯且符合场景逻辑的视频内容,极大拓展了创造性AI的应用边界。通过大规模Transformer架构与扩散式生成机制,这类模型实现了对视频生成质量,动态性,一致性的全面提升,广泛应用于虚拟场景合成,跨模态艺术设计、个性化内容生成等场景,为创意产业和智能化工具的发展注入全新动能。
上一期介绍了文生图的多模态扩散模型 FLUX,本期将介绍Wan2.1模型和HunyuanVideo模型,涵盖文生视频,图片生视频等方面。内容包括模型细节、训练流程、模型能力的展示,并以PaddleMIX中Wan2.1和HunyuanVideo的实现为例,对代码进行逐步解读。
wan2.1生成效果展示
HunyuanVideo生成效果展示
一、引言
自OpenAI推出Sora以来,视频生成技术引起了业界和学术界的广泛关注,推动了该领域的快速发展。能够生成与专业制作内容相媲美的视频的模型的出现,大大提高了内容创作的效率,同时降低了视频制作的成本。
HunyuanVideo是一个13B参数量的视频生成模型,模型进行了一系列针对性的设计,保证了高质量的视觉效果,运动动力学,文本-视频对齐和更好的拍摄技术。论文提出了一套完整的数据过滤,数据筛选处理的流程,生成了大量高质量的视频数据用于模型训练。评测结果显示,HunyuanVideo超越了之前最先进的模型,包括Runway Gen-3, Luma 1.6等。
Wan2.1的核心设计灵感来源于扩散变换器(DiT)与流匹配相结合的成功框架,该框架已在文本到图像(T2I)和文本到视频(T2V)任务中证明了通过扩展可实现显著的性能提升。在这一架构范式中,采用交叉注意力来嵌入文本条件,同时精心优化模型设计以确保计算效率和精确的文本可控性。为了进一步增强模型捕捉复杂动态的能力,还融入了完整的时空注意力机制。Wan2.1提供了两个功能强大的模型,即1.3B和14B参数模型,分别用于提高效率和效果。它还涵盖了多个下游应用,包括图像到视频、指令引导的视频编辑和个人视频生成,涵盖多达八个任务。同时,Wan2.1是首个能够生成中英文视觉文本的模型,显著提升了其实用价值。
数据方面,Wan2.1和HunyuanVideo都提出了一套完整的数据筛选,过滤,处理的流程,得到了大量高质量视频数据,为模型效果提供了保障。模型方面,Wan2.1和HunyuanVideo都由Causal 3D VAE,diffusion backbone和Text Encoder共3部分组成,都对VAE部分进行了重新训练,diffusion backbone部分都使用DiT架构构建时间和空间上的注意力机制,其中HunyuanVideo的diffusion backbone部分使用了Dual-stream to Single-stream模型架构。
二、Hunyuanvideo模型介绍
2.1 Hunyuanvideo方法介绍
2.1.1 模型架构
HunyuanVideo网络架构由3部分组成如下图所示,Causal 3D VAE,Large Language Models以及diffusion backbone
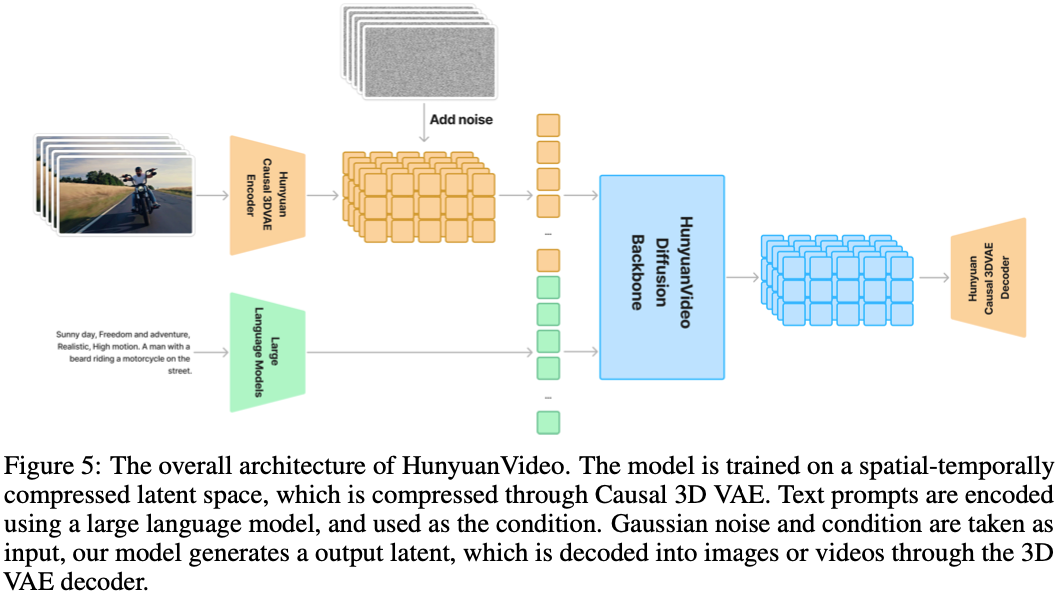
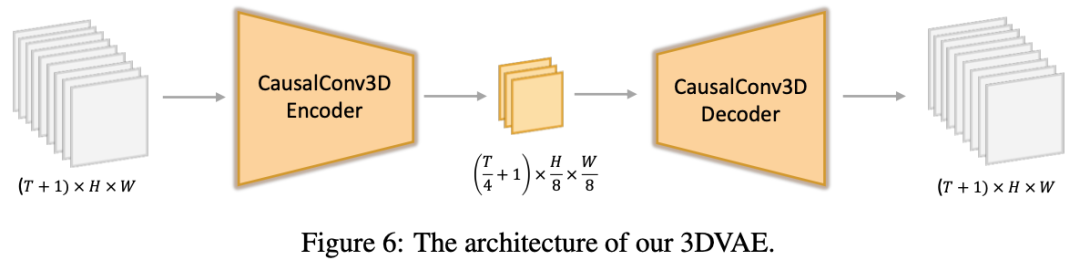
Causal 3D VAE。首先Causal 3D VAE encoder将视频和图像从pixel空间压缩到latents空间。具体来说,使用CausalConv3D将形状为 的视频数据压缩为 的latents,其中。经过VAE压缩后的视频latents形状为 ,使用卷积核为 3D convolution对视频latents进行处理,随后展平为1D向量,就得到了长度为的1维tokens。
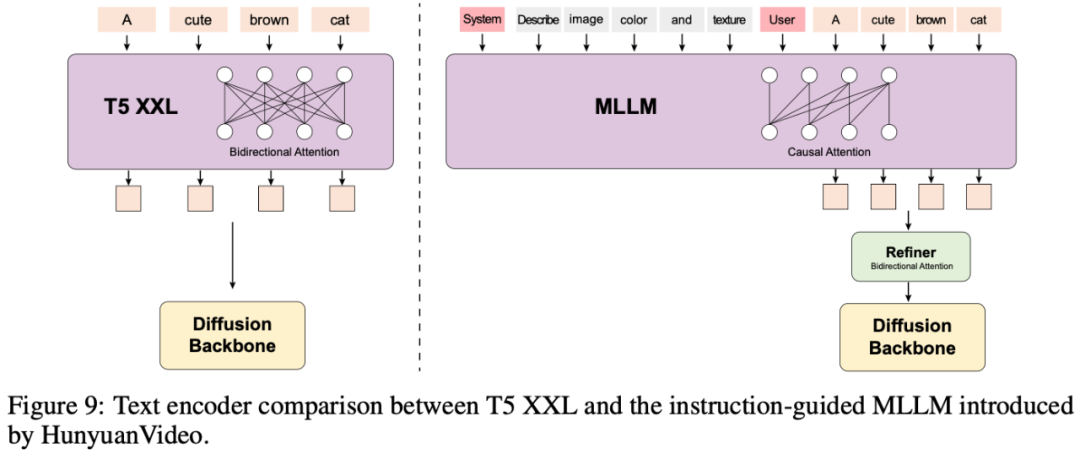
Large Language Models。prompt输入text encoder得到prompt embeddings。HunyuanVideo使用了一个预训练好的多模态大语言模型(MLLM) Llama作为text encoder,这种设计具有如下优势:(1)与T5相比,MLLM经过visual instruction finetuning后其特征空间中的图像-文本对齐更好,(2)与CLIP相比,MLLM具有更好的图像细节描述和复杂推理能力,(3)MLLM可以作为一个zero-shot learner,通过跟随用户提供的prompt,帮助文本特征更多地关注关键信息。T5-XXL使用的是bidirectional attention,MLLM使用的是causal attention,后者可以为扩散模型提供更好的文本引导。为此,HunyuanVideo引入了一个额外的bidirectional token refiner来增强文本特征。同时使用CLIP模型提取包含全局信息的pooled prompt embeddings,随后加到timestep embedding中输入到网络中。
Diffusion Backbone。为了更加高效地整合文本和图像信息,HunyuanVideo使用了Dual-stream to Single-stream模型架构。在dual-stream阶段,视频token和文本token独立地使用多个transformer blocks进行处理,更好地学习各自模态的信息。在single-stream阶段,将视频token和文本token拼接起来共同输入到transformer blocks中高效地进行多模态信息融合。为了适应不同分辨率,不同比例,不同时长的视频生成,HunyuanVideo在每个transformer block中使用Rotary Position Embedding (RoPE)。RoPE使用一个rotary frequency matrix对相对位置和绝对位置进行编码。HunyuanVideo将RoPE扩展到了3个维度,分别为时间T,高度H,宽度W,在3个维度分别计算一个rotary frequency matrix,然后将query和key的特征维度划分为3个区间,每个区间的特征乘以对应的rotary frequency matrix然后再拼接起来,这样就得到了position-aware的key和value特征。
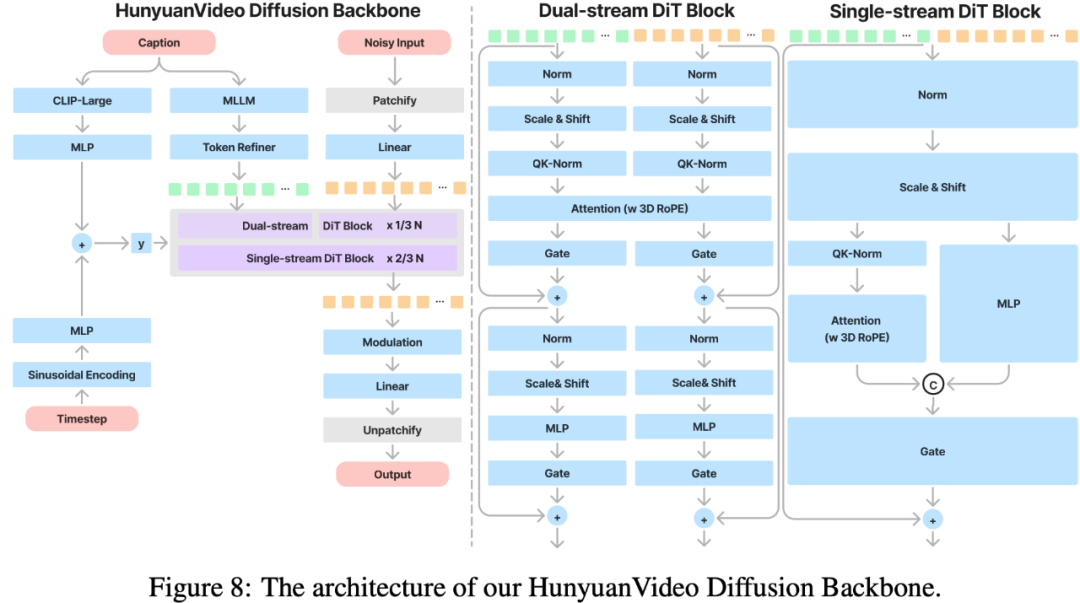
HunyuanVideo中使用了Full Attention机制,具有如下的优势:
- 相比分离的spatio-temporal attention,具有更好的效果
- 支持同时生成图像和视频,简化了模型训练过程,提升了模型的可扩展性
- 能够更加高效地使用目前LLM相关的加速技术,提升了训练和推理的效率
2.1.2 数据处理
该部分主要介绍训练数据的处理流程。
数据筛选。使用PySceneDetect将原始视频切分为视频片段,使用VideoCLIP模型计算这些视频片段的embeddings,根据embeddings过滤掉相似度高的视频片段和重采样。定义了一系列过滤器用于过滤数据,包括:美学过滤器,光流过滤器,OCR过滤器,运动过滤器等,用于筛选出美学质量高,高动态性,清晰,不包括文本和字幕的视频片段。数据过滤pipeline如下所示,总共产生了5个数据集,对应着5个训练阶段,同时视频分辨率也在逐步增加。为了在最后一个阶段提升模型性能,论文构建了一个包括1M高质量视频片段的数据集,用于微调模型。
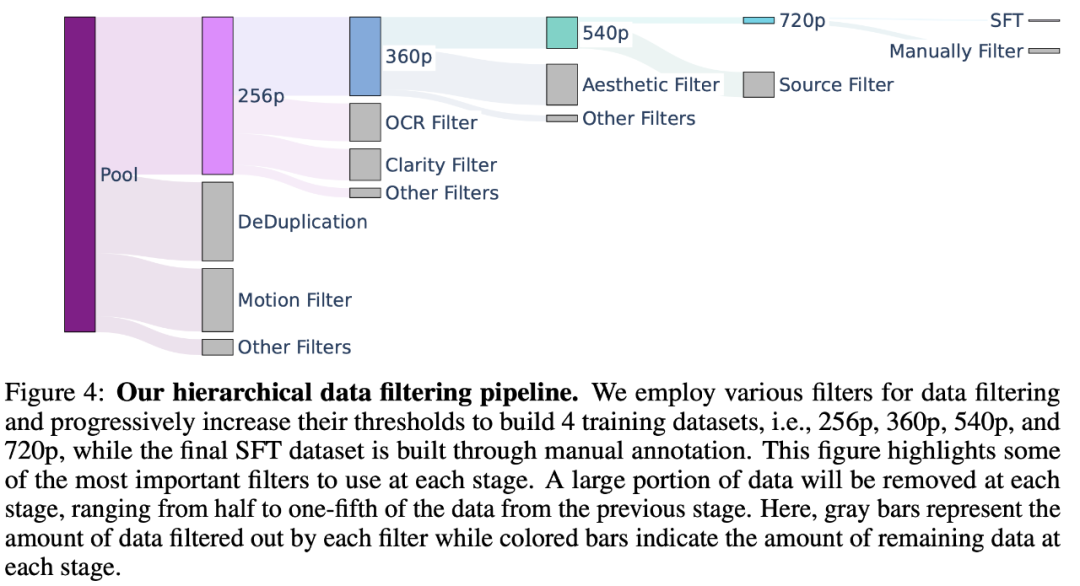
数据标注。开发了一个Vision Language Model(VLM)用于生成结构化的注释,包括:简短的描述、详细的描述、背景、风格、拍摄风格、光照、氛围。训练了一个相机运动分类器,能够预测14种不同的相机运动类型,有助于实现生成模型的摄像机移动控制能力。
2.1.3模型训练
- 图像预训练:
- 第一阶段:使用低分辨率256px图像进行预训练,同时采用多比例训练multi-aspect training,能够有助于模型生成各种比例的图像,同时可以避免在图像预处理阶段裁剪操作导致的文本-图像不对齐的问题
- 第二阶段:使用更高分辨率512px图像进行训练,为了保证低分辨率图像的生成效果,采用混合尺度训练,也即同时将256px和512px图像混合后进行训练
- 视频-图像联合训练:
- 经过处理后的视频数据有不同的比例和长度,为了更加高效地使用这些数据,根据视频长度和比例将数据划分到不同的buckets中。由于每个bucket中token的数量都不一样,为此为每个bucket分配了一个最大的批次大小,以防止训练时超出显存的问题。训练之前,所有数据都会根据视频长度和比例被分配到最近的bucket中,训练时,每个rank都会随机从一个bucket中获取一个批次的数据。这种随机选择机制可以保证模型训练的每一步都是用不同的尺寸的数据,从而提升模型的泛化能力。
- 为了生成更高质量的长视频,加快模型收敛,huyuanvideo提出了一种课程学习策略curriculum learning strategy,使用T2I模型权重进行初始化,随后逐步增加视频长度和分辨率,主要分为以下3个阶段:
·低分辨率,短视频阶段:该阶段模型能够建立文本和视觉信息之间的基本映射关系,在较短的视频中可以保证一致性和连贯性
·低分辨率,长视频阶段:该阶段模型学习更加复杂的时间动态和场景变换,能够在较长的视频中保证时间和空间的一致性
·高分辨率,长视频阶段:该阶段模型主要增强视频分辨率和细节质量 - 同时,在每个阶段会按照不同的比例将图像数据加入进来,使用图像和视频的混合数据进行训练,从而解决高质量数据数据缺失的问题,进一步提升模型生成效果
- 提示词重写:用户提供的提示词的长度和风格往往差异较大,为此论文使用Hunyuan-Large模型作为提示词重写模型,将用户提供的prompt转换为model-preferred prompt。该方法可以在无需重新训练模型的前提下,利用详细的提示词和上下文学习样例来提升生成效果,主要功能如下:
- 多语言输入适配:该模块将通过各种语言处理和理解用户的prompt,确保保留prompt的含义和上下文信息
- 提示词结构标准化:将prompt重新组织为标准的格式,类似于训练数据的captions
- 复杂术语的简化:在保留用户原始含义的前提下,将用户复杂的用词简化为更简单直接的表达
- 高性能微调:在预训练阶段使用了大量的数据进行训练,虽然这些数据足够丰富但是质量参差不齐,为此论文从这些数据中精心挑选了4个特定的子集数据,并使用这些数据对模型进行微调,从而使模型可以生成更高质量,动态性的视频结果。在该阶段会随机开启或者关闭tiling策略,保证训练阶段和推理阶段结果的一致性。
2.1.4 模型加速
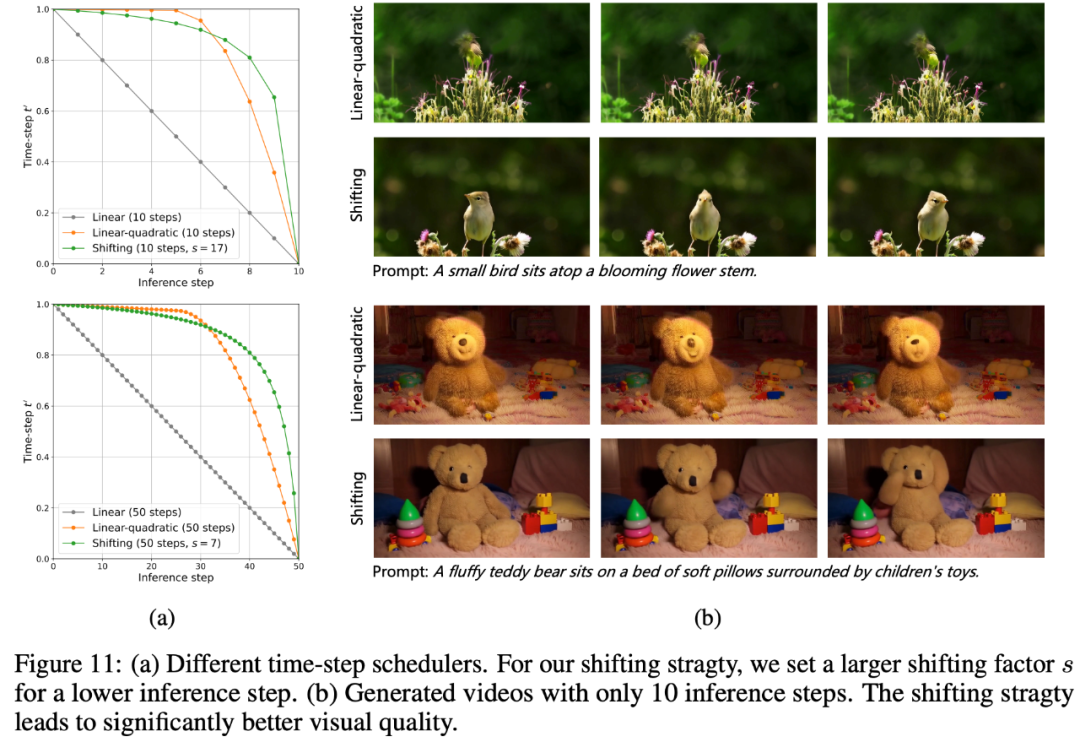
推理步数减少:之前的一些工作表明,去噪过程中前期的时间步尤为重要,为此hunyuanvideo会在使用较少推理步数时使用time-step shifting,具体来说,当给定一个时间步 t 之后,会将其映射为 ,其中s表示偏移系数。当偏移系数s>1时,模型会更加依赖前期的时间步,同时论文发现越少的推理步数需要越大的偏移系数s,例如50步时s设置为7,当推理步数减少到20步时s需要增大到17.
CFG蒸馏:Classifier-free guidance (CFG) 显著提升了文本引导生成模型的生成质量,但由于需要同时输入有条件输入和无条件输入,所以需要耗费更多的计算资源。为此hunyuanvideo使用了CFG蒸馏技术,具体来说,将CFG训练得到的模型视为教师模型,然后定义一个学生模型,该学生模型网络结构和初始化参数和教师模型一致,学生模型接收guidance scale作为输入参数,直接输出教师模型的CFG的结果。实验表明,CFG蒸馏后的学生模型不需要同时输入有条件输入和无条件输入,可以实现1.9倍的推理加速。
2.2 Hunyuanvideo 代码解读
2.2.1 HunyuanVideoTransformerBlock
-
类名: HunyuanVideoTransformerBlock
-
主要功能: 分两个stream对图像模态特征和文本模态特征进行计算
-
初始化参数 (init):
- num_attention_heads: attention时的head个数
- attention_head_dim: attention时特征的维度
- mlp_ratio: FFN中inner_dim扩大的比例
- qk_norm: query和key的norm方式
- 前向传播参数 (forward):
- hidden_states: paddle.Tensor 类型的输入张量,表示image embeddings
- encoder_hidden_states:paddle.Tensor 类型的输入张量,表示prompt embeddings
- temb:paddle.Tensor 类型的输入张量,表示timestep embeddings
- attention_mask:可选参数,paddle.Tensor 类型的注意力掩码,用于屏蔽不需要关注的位置。
- freqs_cis:可选参数,由paddle.Tensor组成的Tuple类型,表示图像rotary embeddings
- 前向传播 (forward):
- hidden_states输入AdaLayerNormZero,对hidden_states进行norm,shift,scale计算,并计算后续的gate,shift,scale参数
- encoder_hidden_states输入AdaLayerNormZero,对encoder_hidden_states进行norm,shift,scale计算,并计算后续的gate,shift,scale参数
- 将hidden_states和encoder_hidden_states输入Attention模块
- 对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1921
1921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









