




 谷歌研究团队的FixMatch算法简化SSL,结合一致性正则和伪标签,使用弱强数据增强。通过飞桨实现,FixMatch在CIFAR-10上展现SOTA性能,核心在于伪标签筛选和优化策略。
谷歌研究团队的FixMatch算法简化SSL,结合一致性正则和伪标签,使用弱强数据增强。通过飞桨实现,FixMatch在CIFAR-10上展现SOTA性能,核心在于伪标签筛选和优化策略。

背景
半监督学习(SSL)提供了一种利用无标签数据提高模型性能的有效方法,这一领域最近取得了快速进展,但以往的算法需要借助复杂的损失函数和大量难以调整的超参数。本文介绍了谷歌的研究团队提出的FixMatch[1],这是一种大大简化现有 SSL 方法的算法。FixMatch是SSL的两种方法的组合:一致性正则和伪标签。
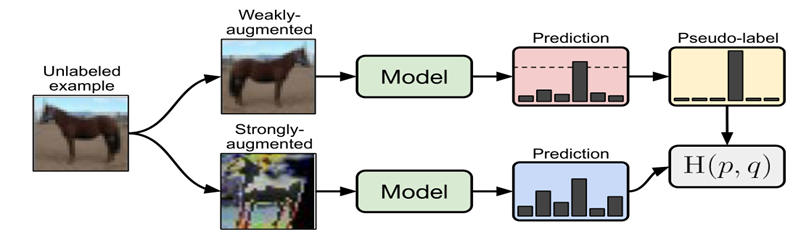
如图所示为FixMatch的流程图。FixMatch的新颖之处在于,对于无标签的样本:
-
FixMatch首先对弱增强的无标签图像预测伪标签,对于给定的图像,只有当模型产生高于阈值的预测时,才会保留作为伪标签;
-
再对同一图像的强增强版本预测出分类概率,通过交叉熵损失衡量强弱二者的预测的一致性。
我们首先回顾一下利用了一致性正则和伪标签方法的经典SSL算法,然后再详细描述FixMatch算法,并穿插关键部分的飞桨代码实现(采用飞桨最新稳定版本)。
一致性正则
一致性正则是许多SSL算法的重要组成部分。一致性正则的思想是——即使在无标签的样本被注入噪声之后,分类器也应该为其输出相同的类分布概率。即强制一个无标签的样本 应该被分类为与自身的增强 相同的分类[2]。
伪标签
指使用模型本身为无标签数据获取标签的方法。具体而言,将模型输出的softmax概率分布视为软伪标签;或将经过argmax或者one_hot得到的预测视为硬伪标签。利用这些伪标签作为监督损失进一步训练模型。
SSL算法的比较
下表提到了与生成伪标签(Artificial label)相关的SSL算法。其中列出了用于伪标签的数据增强、模型的预测以及应用于伪标签的后处理。
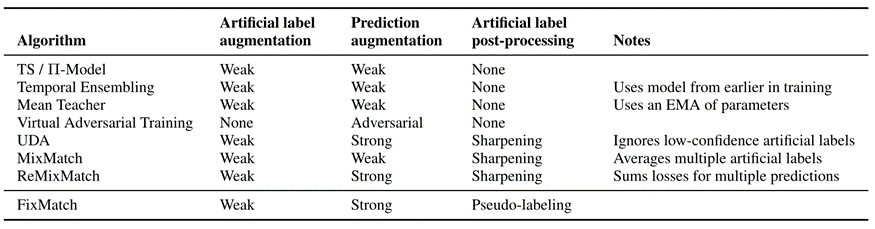
FixMatch的核心是一致性正则和伪标签方法的简单组合,无标签模型预测与UDA一样采用RandAugment[3]进行强增强,详细实现见AI Studio项目。

FixMatch
FixMatch的损失函数
FixMatch的损失函数由两个交叉熵损失项组成:一个是应用于有标签数据的全监督损失,另一个是用于无标签数据的一致性正则损失。
令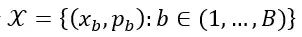 表示batch size为 的有标签样本,其中 是训练样本, 是相应的one-hot标签。
表示batch size为 的有标签样本,其中 是训练样本, 是相应的one-hot标签。
令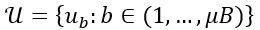 是batch size为 μ 的无标签样本,其中 μ 是决定
是batch size为 μ 的无标签样本,其中 μ 是决定 和
和 的数量关系的超参数。令 表示输入样本 时模型输出的类概率分布。将两个概率分布 和 之间的交叉熵表示为 。强增强表示为 ,弱增强表示为 α 。
的数量关系的超参数。令 表示输入样本 时模型输出的类概率分布。将两个概率分布 和 之间的交叉熵表示为 。强增强表示为 ,弱增强表示为 α 。
-
对于有标签样本,FixMatch均采用弱增强,其损失函数为:
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 1855
1855



 到【灌水乐园】发言
到【灌水乐园】发言







