 飞桨模型到鲲云星空X3加速卡的高效部署实战
飞桨模型到鲲云星空X3加速卡的高效部署实战




 本文介绍了如何利用Paddle2ONNX将飞桨模型转换为ONNX格式,然后通过鲲云的RbCompiler工具链在星空X3加速卡上进行高效部署。通过CAISA数据流架构,实现了高芯片利用率和接近理论峰值性能的推理。文章还展示了从模型训练、转换到推理测试的完整流程,验证了在联想扬天M400s上的优秀性能。
本文介绍了如何利用Paddle2ONNX将飞桨模型转换为ONNX格式,然后通过鲲云的RbCompiler工具链在星空X3加速卡上进行高效部署。通过CAISA数据流架构,实现了高芯片利用率和接近理论峰值性能的推理。文章还展示了从模型训练、转换到推理测试的完整流程,验证了在联想扬天M400s上的优秀性能。
点击左上方蓝字关注我们


在端侧和边缘端推理需求日渐蓬勃的今日, 边缘端AI专用推理加速硬件遍地开花;而传统架构下设计的硬件多是采用CPU大小核搭配(比如2大核4小核), 加上GPU和自行研发的NPU组合而成的SoC。这样的架构往往无法最有效的确保芯片的利用率,也造成芯片的实测性能远低于理论的芯片算力的情况,浪费了企业在硬件上的资金投入。因此,CAISA的数据流架构应运而生,这样的架构使用数据流取代了传统的指令集方式计算,具有高度可拓展性且适用于多种深度学习算法, 实测下能够实现硬件 76%~95.4%的理论峰值性能,可以最有效的确保企业的投入产出比。
加速卡和编译器工具介绍
本次部署示例使用的是鲲云星空X3加速卡, 搭配鲲云自行研发的RainBuilder编译器,能无缝地在离线状态将ONNX等模型格式转换成IR格式后在RainBuilder Runtime上部署,支持ResNet, YOLO, DeepLab 等各种CNN类主流算法推断模型。

架构:
定制数据流架构 CAISA 3.0
芯片利用率:
高达 95.4%
峰值性能:
10.9 TOPS
RainBuilder编译器
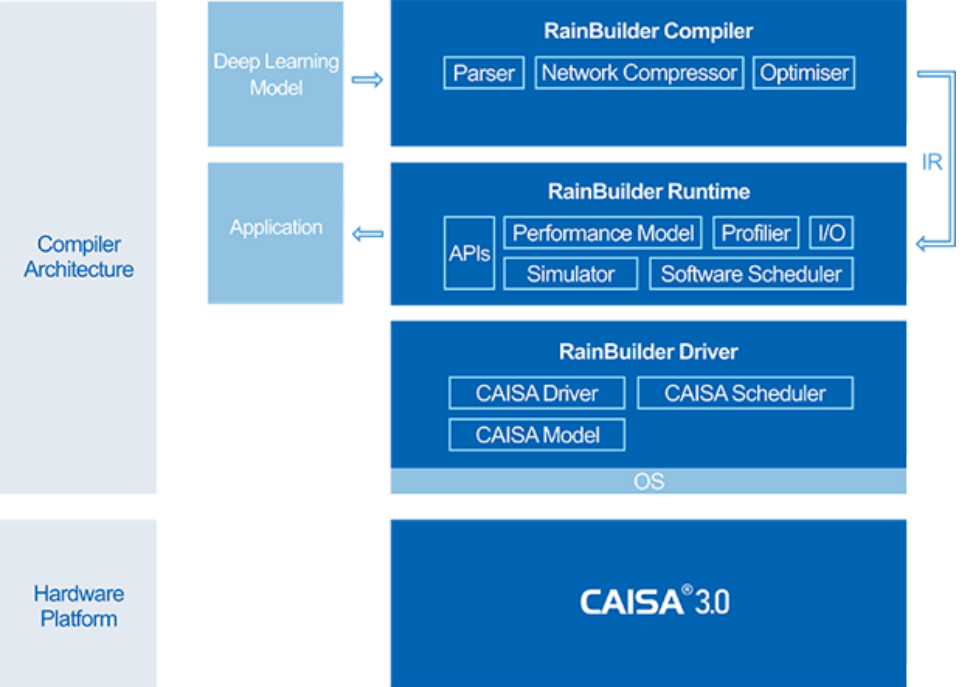
端到端编译工具链,开发者只需两步,即可实现神经网络模型推演在鲲云星空X3加速卡上的高效部署及运行。
RbCompiler:
算法编译器组件,主要负责将其他深度学习框架的模型转译为适用于 CAISA 的中间表达(SG-IR)模型。
RbRuntime:
为 CAISA 加速引擎的软件运行时,负责加载 SG-IR 并使用 CAISA 加速引擎对深度学习网络 进行运行加速。
RbDriver :
为 CAISA 加速引擎的软件驱动层,与 CAISA 加速引擎相同,驱动层作为底层组件。
Paddle2ONNX介绍
Paddle2ONNX支持静态图和动态图模型转为ONNX格式,在飞桨框架升级2.0后,框架已经内置paddle.onnx.export接口,用户在代码中可以调用接口以ONNX协议格式保存模型。此外,用户已经保存的飞桨模型,也可以通过Paddle2ONNX加载后进行转换。
Paddle2ONNX支持多达103个Paddle OP算子。在转换过程中,支持用户指定转换为ONNX 1到12任意版本的模型,提升模型的适配能力。
转换部署流程
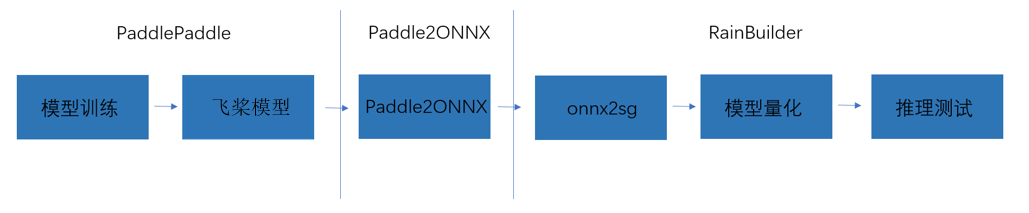
a 模型训练-PaddleX
PaddleX是基于飞桨核心框架、开发套件和工具组件的深度学习全流程开发图形化工具。具备全流程打通 、融合产业实践 、易用易集成三大特点。这里我们使用PaddleX进行图像分类,模型选择Resnet50,训练和模型生成过程如下。
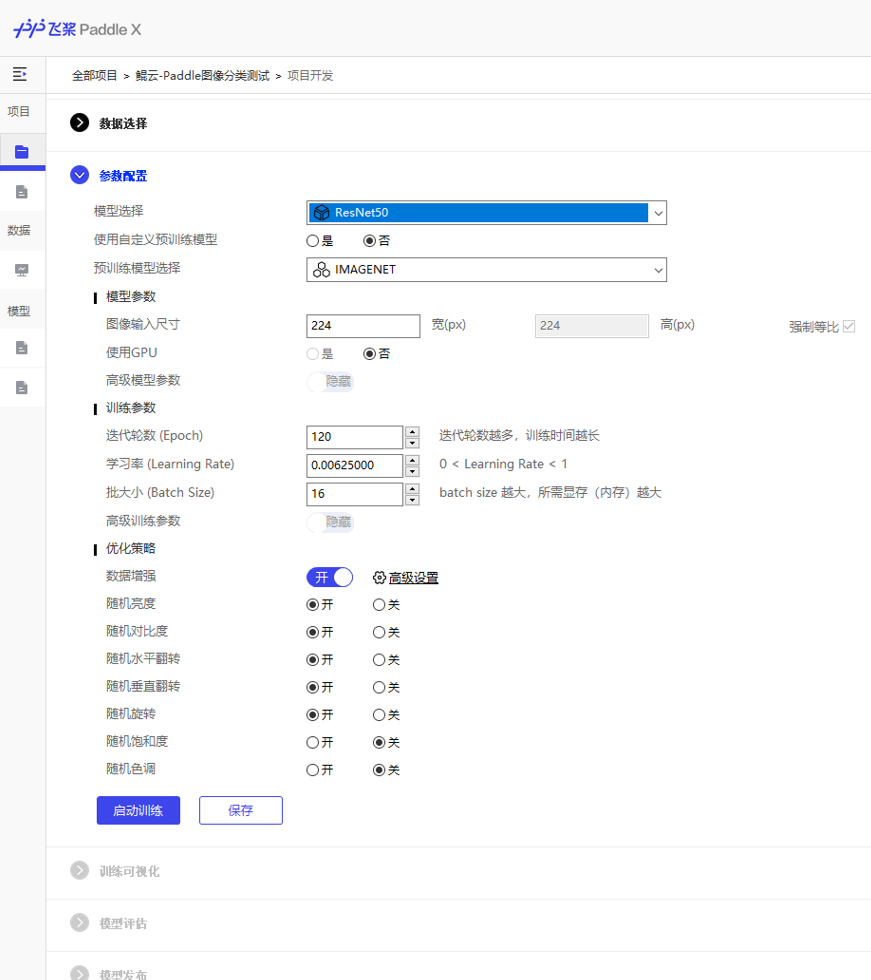
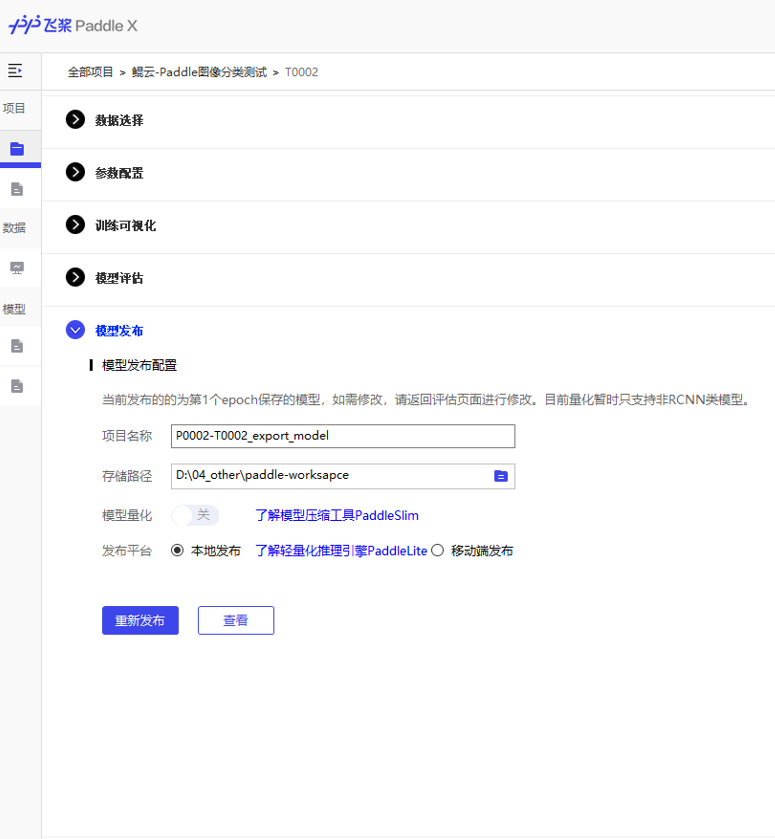
基于以上训练过程,就得到了发布好的模型文件,后面对文件进行转换和部署。
b 模型转换-Paddle2ONNX
百度的Paddle2ONNX支持转换静态图和动态图。我们使用PaddleX保存生成的静态图文件进行转换,后面直接使用Paddle2ONNX工具,对应指令为paddle2onnx。
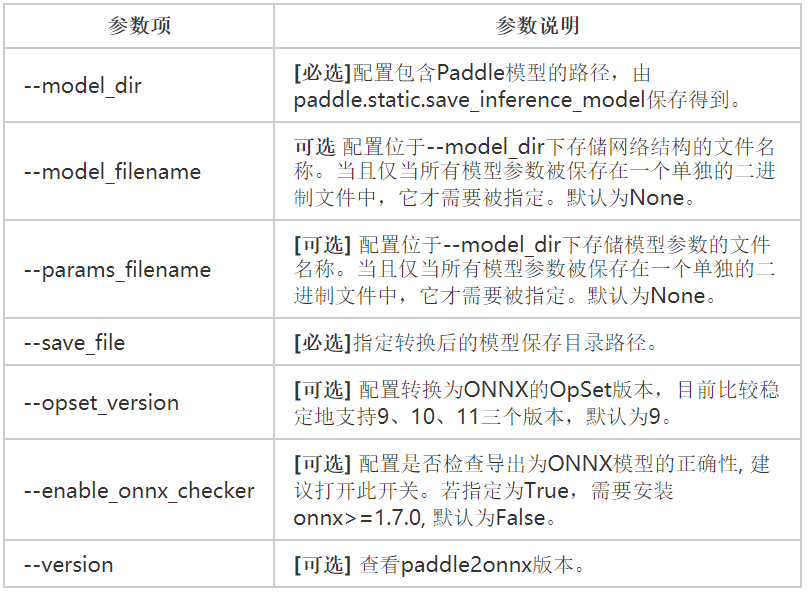
命令行:
paddle2onnx --model_dir ./inference_model/ \
--model_filename '__model__' \
--params_filename '__params__' \
--save_file ./resnet50.onnx \
--opset_version 11\
执行命令生成resnet50.onnx文件。
c 模型转换-onnx2sg
鲲云的RbCompiler 的 ONNX 前端在算子级层面对 ONNX 模型进行解析并转化为 RbRuntime 可以识别的 SG-IR,用户可以ONNX 前端对.onnx 格式的模型直接进行转化操作,对应指令为RbCli onnx。
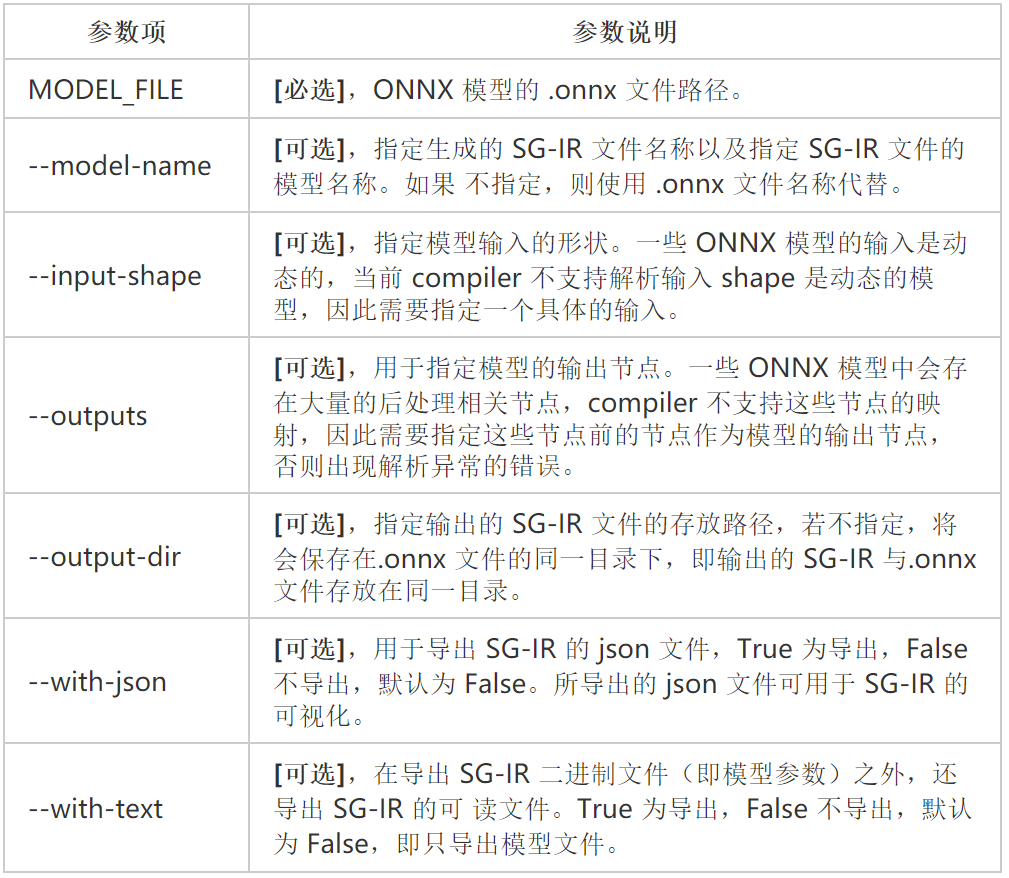
命令行:
RbCli onnx resnet50.onnx
--input-shape 1,3,224,224
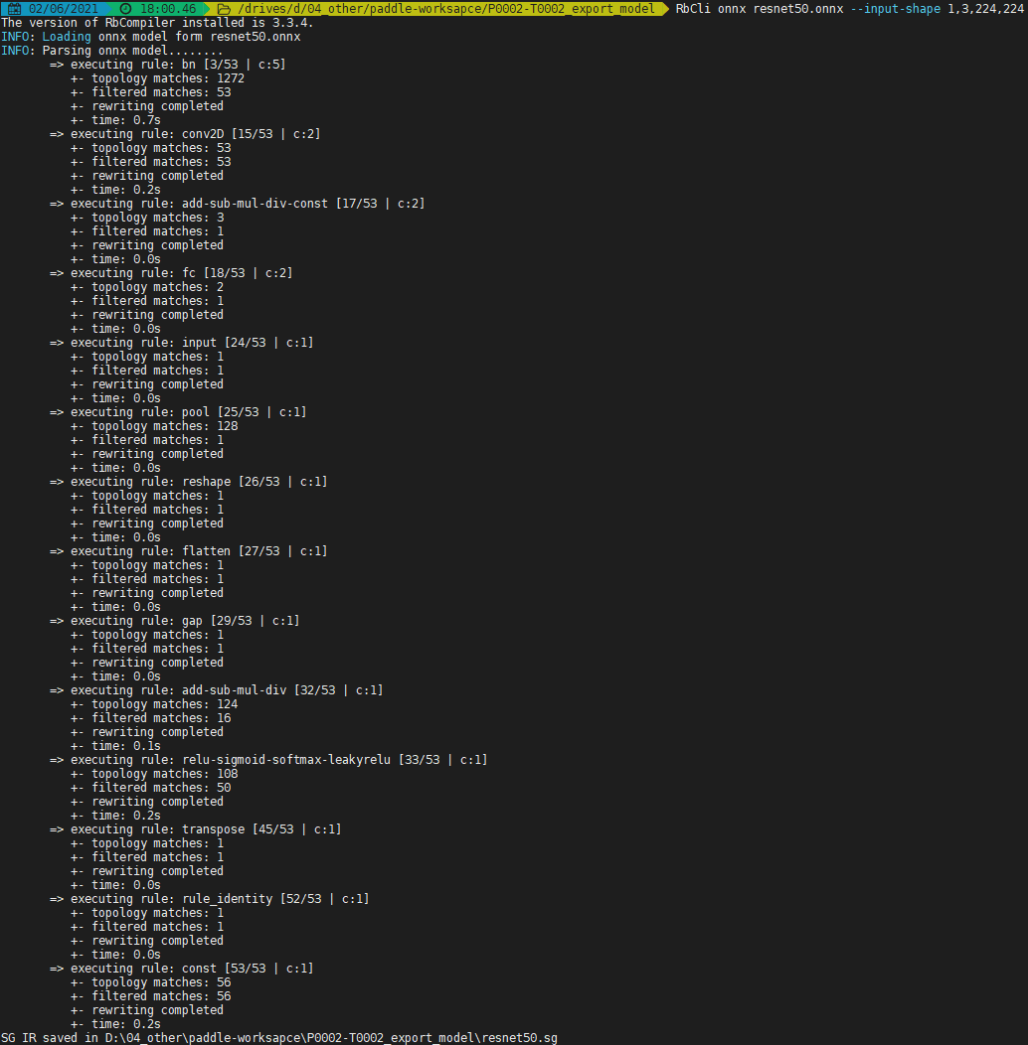
执行命令生成resnet50.sg文件。
d 模型量化
RbCompiler 的后端以该 SG-IR 为输入,通过量化操作,生成可以在 CAISA 引擎上运行的 SG-IR,对应指令为RbCli quant。
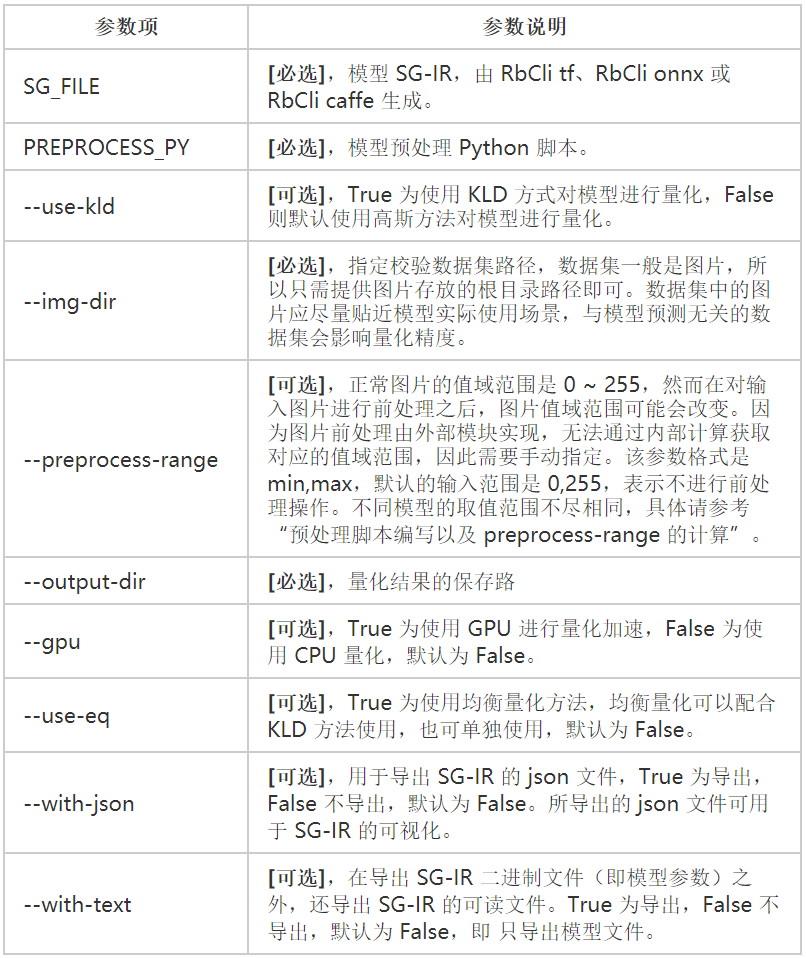
命令行:
RbCli quant resnet50.sg preprocess.py \
--use-kld True \
--preprocess-range -123.0,151.0 \
--img-dir imagenet \
--gpu True\
--export-gpu True \
--output-dir output_quant\
执行命令生成resnet50_8bit.sg文件,得到最终可以运行在鲲云星空加速卡X3上模型文件。
推理测试
RbRuntime 作为 RainBuilder 的后端,配合 RbCompiler 使用,用于加载并运行 RbCompiler 生成的 sg 文件,在加速卡上进行推理计算,返回模型的计算结果。
a 运行DEMO示例
import numpy as np
import pyRbRuntime
# 生成随机输入
# Generate random input data
data = np.random.randint(0, 1, (1,3,224,224)).astype(np.float32)
# 初始化网络
# Init network
net = pyRbRuntime.Network(
sg_file="resnet50_8bit.sg",
dp=[pyRbRuntime.CAISA],
thread_num=1)
# 执行推演并返回结果
# Conduct Inference and get result
output = net.Run(data)
b 速度测试
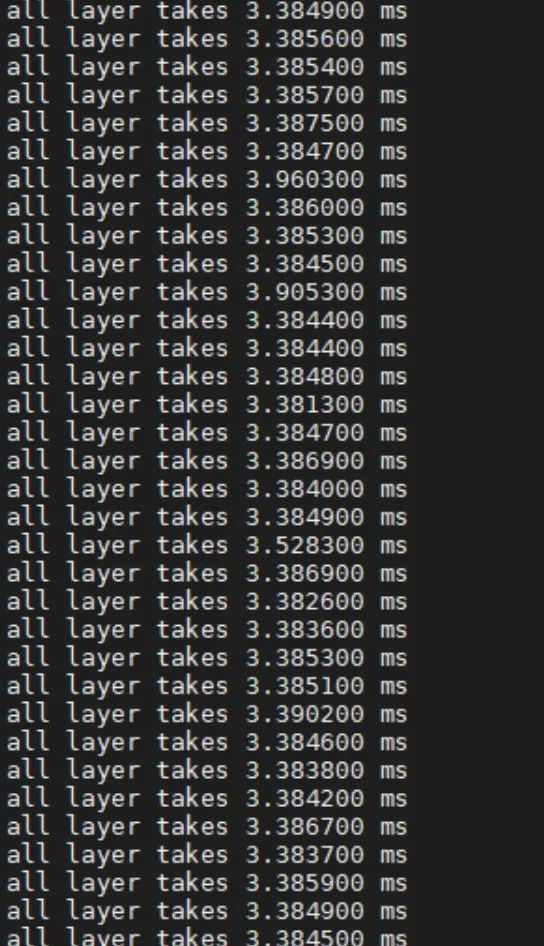
测试环境:联想扬天M400s Intel i5-9400 & 鲲云星空加速卡X3。
在图片测试集上测试输入Batch=4,resnet50的延时为3.38ms,吞吐为1181.68fps。
总结
飞桨深度学习平台提供了快速有效搭建训练深度学习模型的方案,并透过Paddle2ONNX模块与鲲云的星空X3加速卡完成了简单快速的适配,在精度保证的情况下提供了非常优异的性能时延表现,且还有进一步优化的空间。欢迎所有开发者参照本篇分享,实操测试软硬强强结合带来的优异性能。
如在使用过程中有问题,可加入飞桨推理部署交流群进行交流:959308808。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能完备、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END



















 1842
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









