









CVPR2022 | MPViT: Multi-Path Vision Transformer for Dense Prediction

主要内容
做了点啥
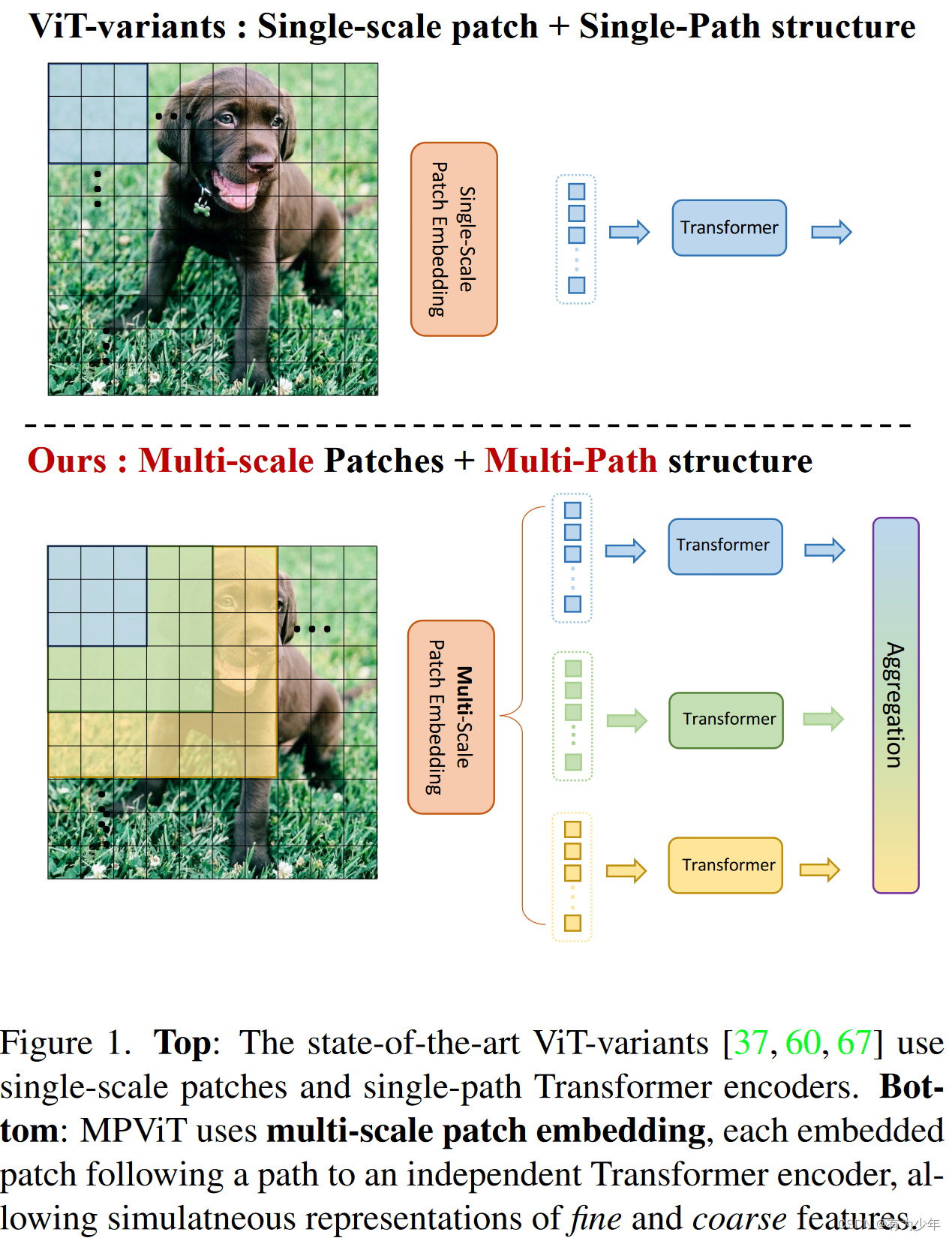
本文重点探究Transformer中的multi-scale patch embedding和multi-path structure scheme的设计。
主要动机
在例如目标检测和分割这样的密集预测任务中,多尺度特征对于判别不同大小的目标或者区域是非常重要的。许多CNN结构中对此都有设计:
- 多粒度卷积核:典型的如Inception Network和VoVNet。可以保证多样的感受野,从而反过来增强检测性能。
- 多尺度特征:典型的如HRNet,通过卷积层,同时集成细粒度和粗粒度的特征。
虽然最近的Vision Transformer展现出超过CNN的性能,但是最近的ViT的变体大多数在专注于如何应对自注意力用于高分辨率密集预测任务中面临的平方复杂度,很少有工作关注与如何构建更有效的多尺度表征。虽然CoaT通过co-scale机制,运行跨层Attention,从而表征了粗粒度和细粒度,但是这种机制需要过多的计算和存储负担,因为他需要在基础模型上,额外添加一个跨层注意结构。因此对于ViT变体而言,多尺度特征表征仍然存在提升的空间。
具体做法
这篇文章就专注于如何为密集预测任务用ViT有效表示多尺度特征。
提出的MPViT,模块内部同时嵌入相同长度序列,但是不同序列的patch token各自有着不同的尺度。不同尺度的token通过多路径被独立送到Transformer编码器中,输出特征被集成在一起,从而确保了在相同的特征层中的粗细粒度特征表征。
具体结构
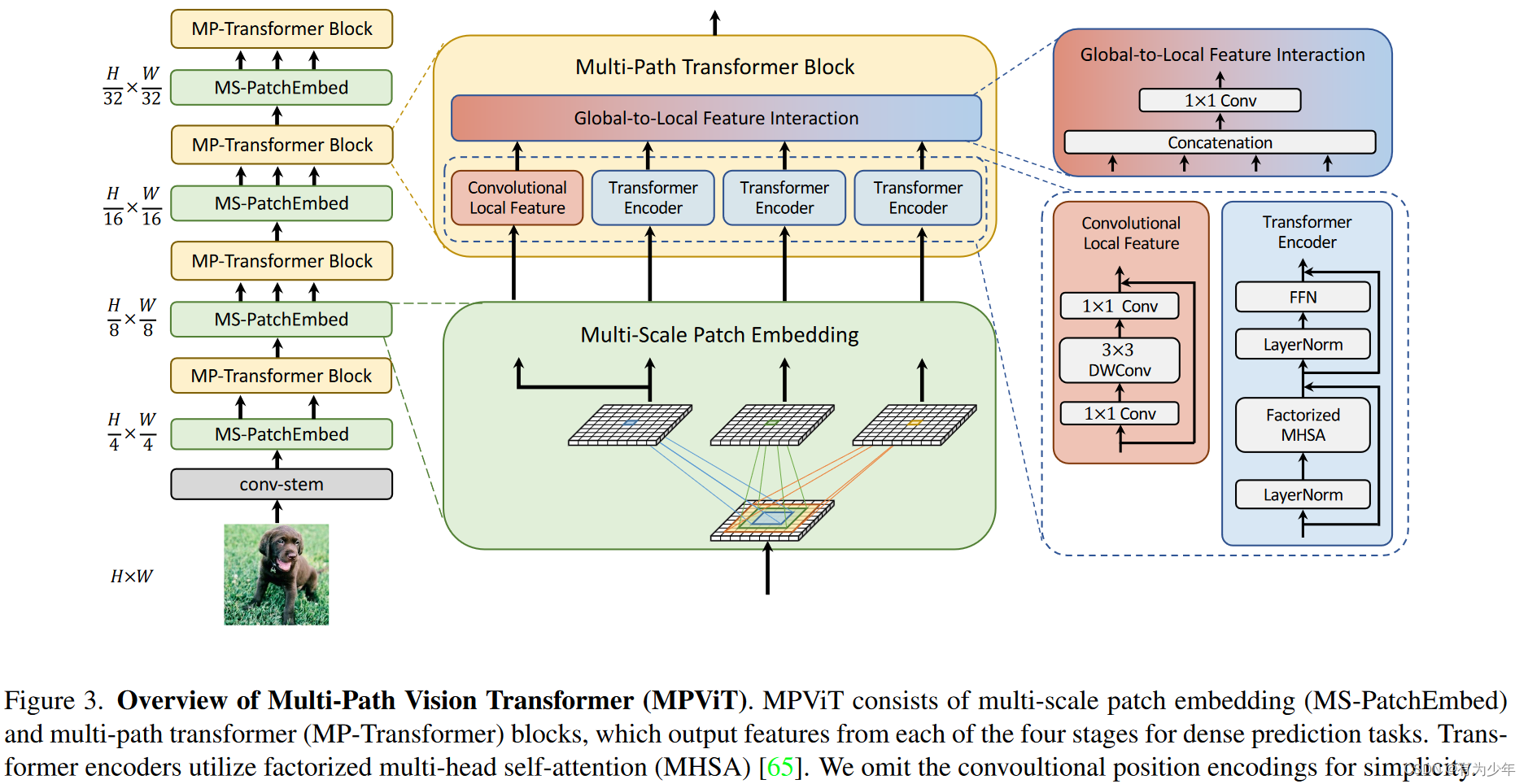
- Multi-Scale Patch Embedding:使用卷积来提取不同尺度的重叠patch。
- 输入来自之前阶段的2D特征,送入多个并行的卷积patch嵌入层。
- 由于使用多个不同大小的卷积操作,会导致过多的参数,于是作者们使用连续的3x3卷积来增大感受野,同时确保较少的参数,如果要缩小分辨率的话,这里的第一个卷积可以引入步长2,实际测试中性能也超过了独立的大核卷积,可能是因为其更高的非线性程度。
- 这里实际使用深度分离卷积(3x3+1x1)的形式替换3x3卷积从而降低参数量。
- 所有的卷积都跟着BN和Hardswish。
- 每个卷积patch嵌入中,使用kxk卷积来生成对应着尺度kxk大小的patch。通过更改卷积层的步长和padding,可以调整这一尺度对应的序列的最终长度。即,不同的patch size可能会有相同的输出长度。
- 每个嵌入的特征序列会被分别送入各自的独立Transformer Encoder路径。每个尺度的路径上都有L个encoder(https://github.com/youngwanLEE/MPViT/blob/e2d86e6c465abc4847e601f8a401bdd1692836f7/mpvit.py#L558-L570)。
- 输入来自之前阶段的2D特征,送入多个并行的卷积patch嵌入层。
- Global-to-Local Feature Interaction: Transformer中的self-attention可以捕获长期依赖关系(即全局上下文),但它很可能会忽略每个patch中的结构性信息和局部关系。另外,Transformer受益于形状偏置(Are convolutional neural networks or transformers more like human vision?)。相反,CNN可以利用来自平移不变性的局部连通性,图像中每个Patch在处理时都具有相同的比重。这种归纳偏置鼓励CNN在对视觉对象进行分类时,相比形状,对纹理有更强的依赖性。于是MPViT中就以一种相互补充的形式组合了CNN的局部连通性和Transformer的全局上下文。
- 在每个阶段中,在多路径Transformer之外,还会引入一个独立的depthwise residual bottleneck block(1x1+3x3+1x1)来整合局部信息。
- 卷积输出与各个Transformer输出结果沿通道拼接后送入独立的1x1结构生成最终输出。输出通道数等于下一阶段的多尺度patch嵌入层的通道数。
实验细节
模型结构
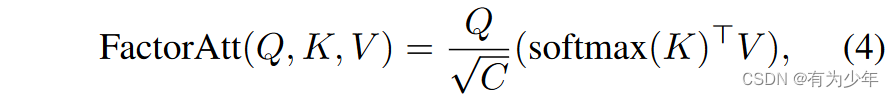
- 使用的Transformer encoder都是来自于CoaT中的具有线性复杂度的Factorized Self Attention。这种结构的计算复杂度是通道数量的平方倍,与序列长度和堆叠层数呈线性关系。
- stem中:两个步长为2的3x3卷积,输出特征下采样4倍。每个卷积后跟一个BN和Hardswish。
- 后续每个stage中,都会堆叠提出的多尺度patch嵌入和多路径Transformer块。
- 结尾使用全局平均池化后接全连接层。
- 在第一个attention阶段,路径数量为2,后续阶段中,路径数量为3。
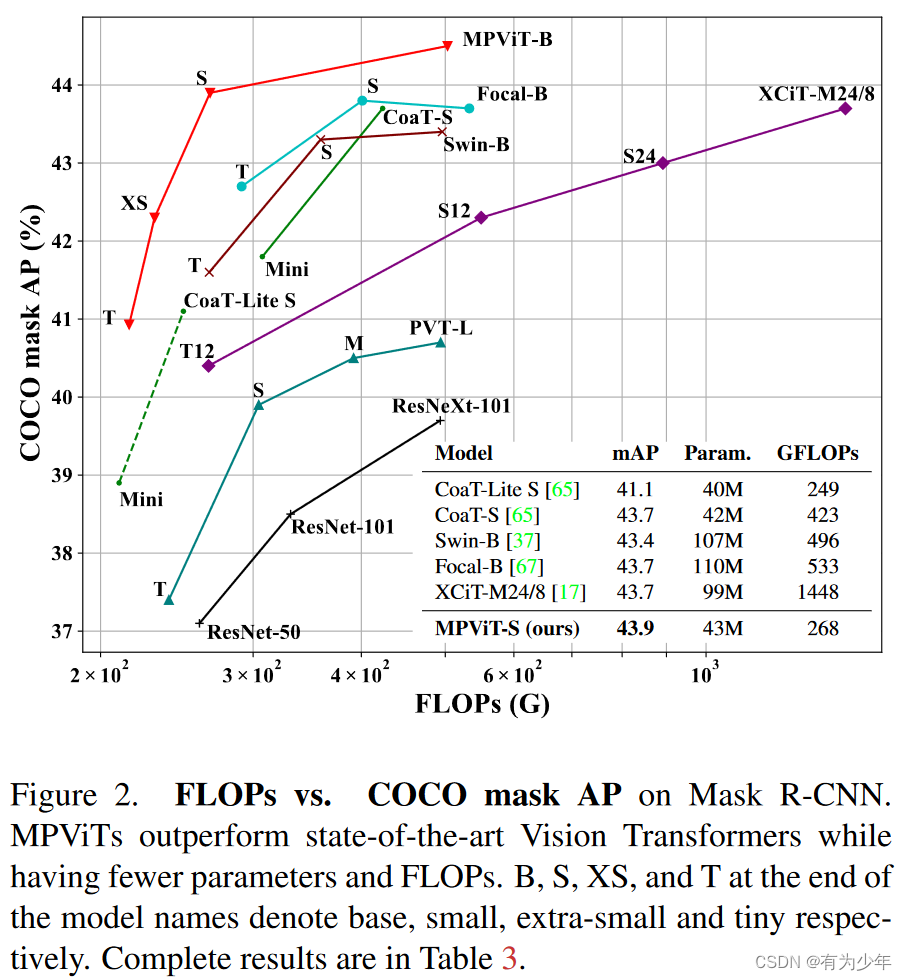
对比实验
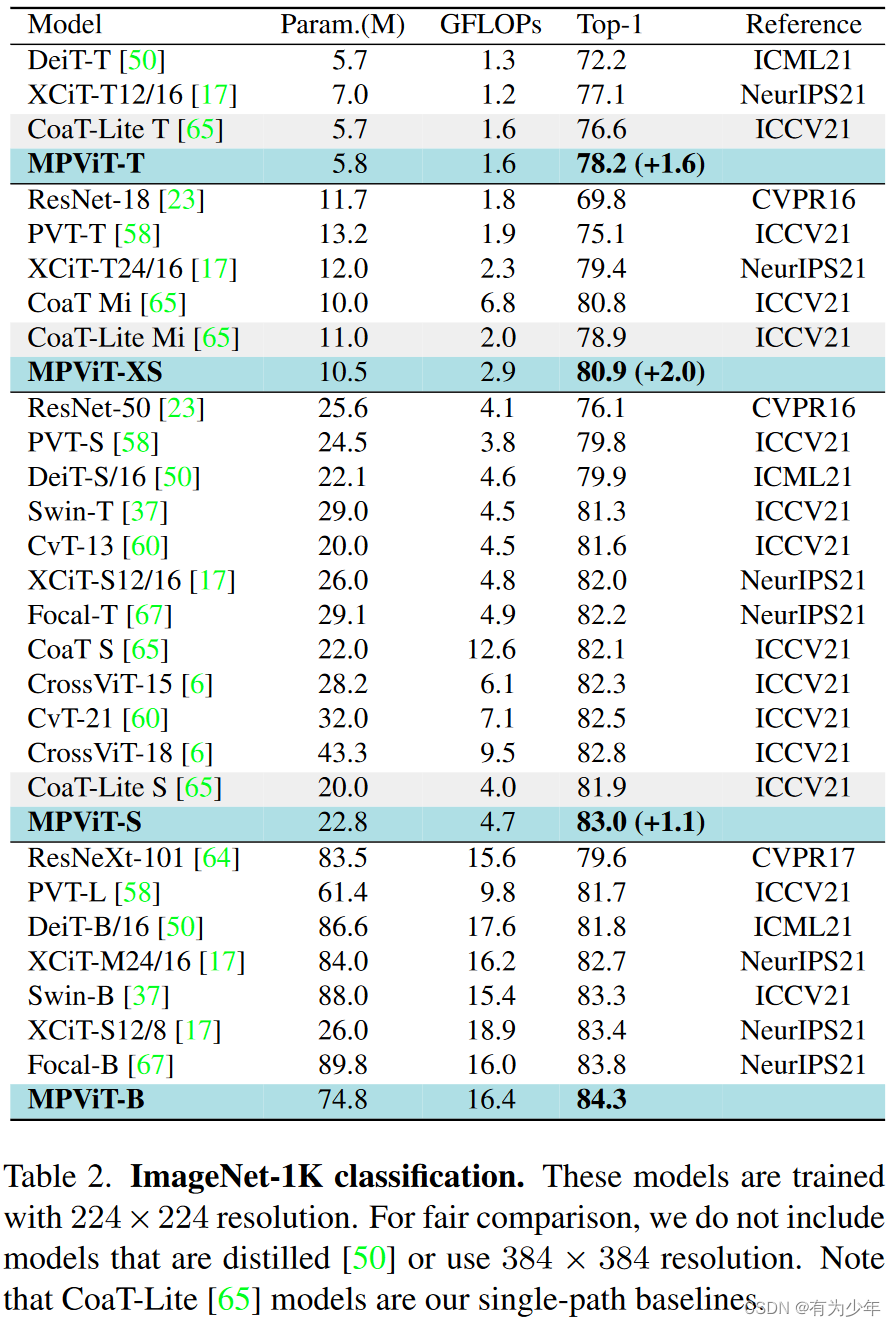
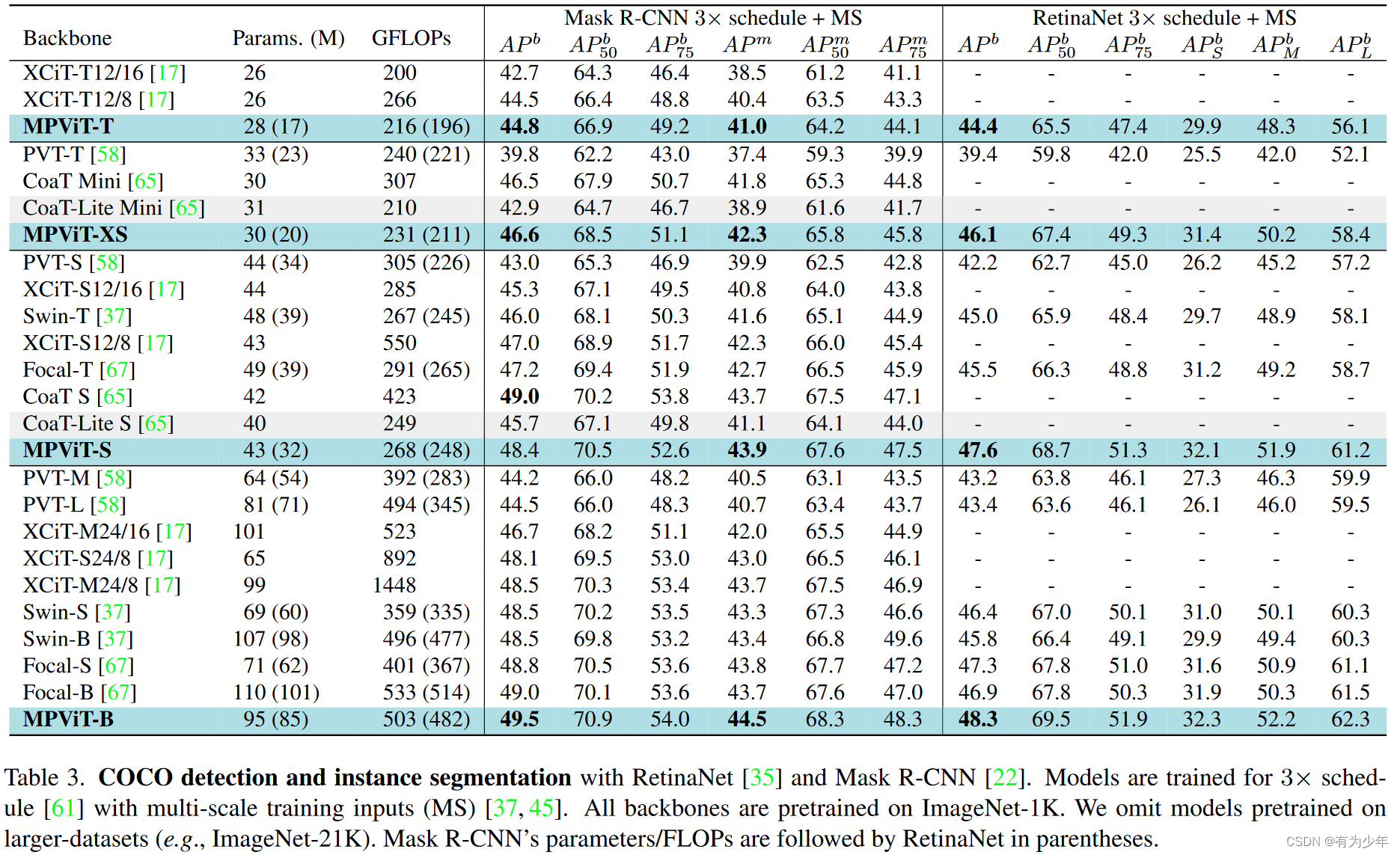
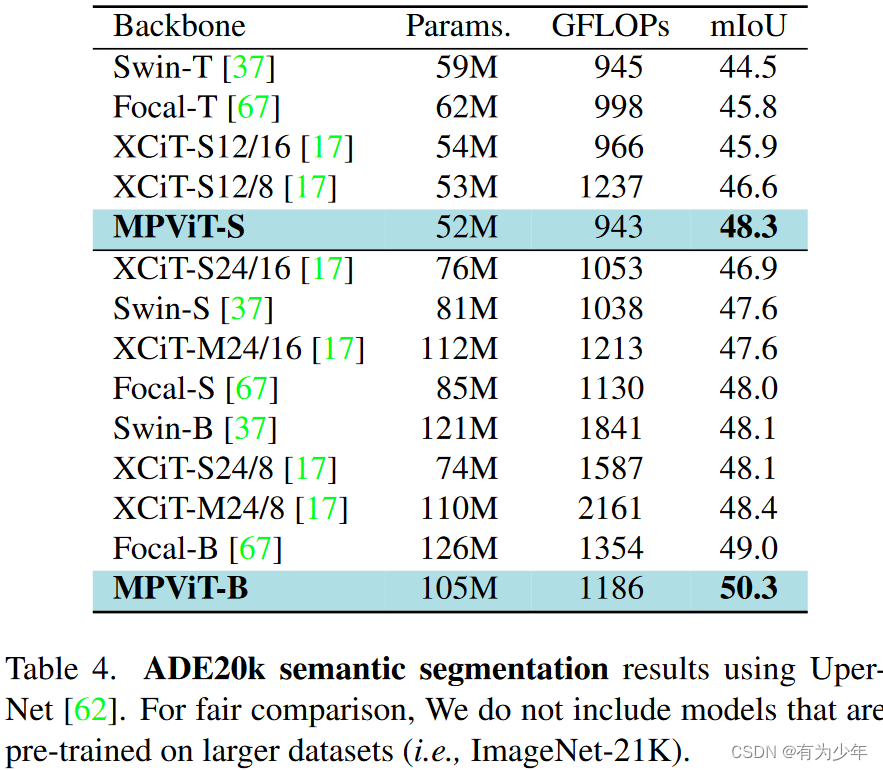
消融实验
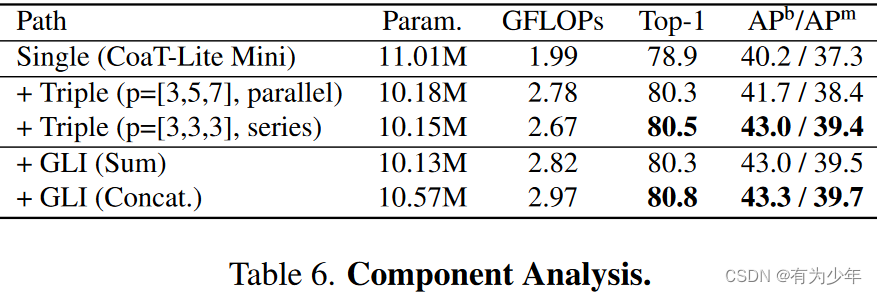
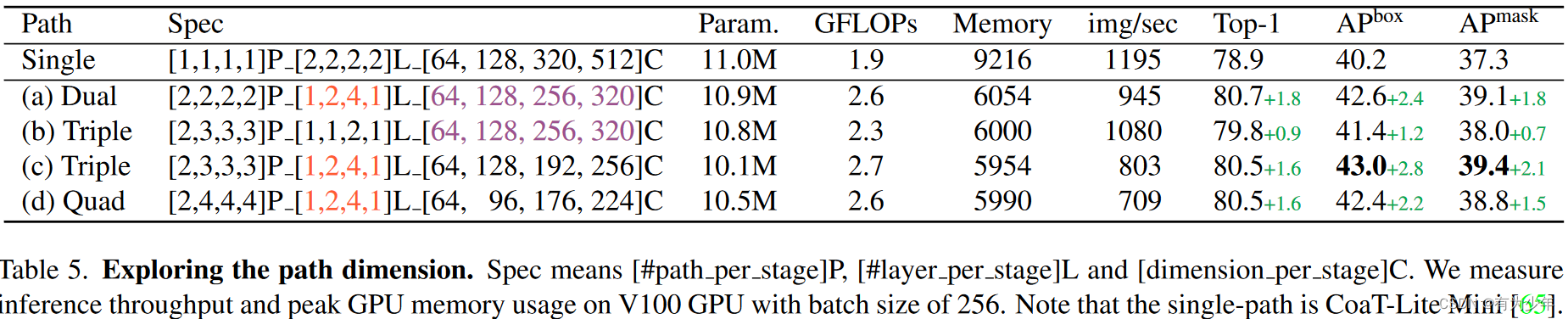 表5中的结果反映出来三个方面的内容:
表5中的结果反映出来三个方面的内容:
- 层(即更深)的数量比嵌入尺寸(即更宽)更重要,这意味着在性能方面,较深,更薄的结构更好。
- 多粒度token嵌入和多路径结构可以为目标价检测器提供更丰富的特征表示。
- 在相同的模型大小和FLOPs的约束下,三路径结构是最佳选择。

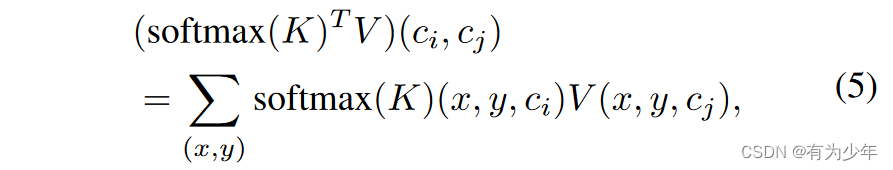
由于使用了来自CoaT中的factorized self-attention,所以在可视化注意力图的时候,作者们使用的是对softmax(K)沿着通道维度的平均。因为在这个注意力形式中,softmax(K)相当于可以看做是V每个空间位置上通道级别的一种空间注意力。

















 9887
9887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









