







CVPR 2022 - Beyond Fixation: Dynamic Window Visual Transformer

- 论文:https://arxiv.org/abs/2203.12856
- 代码:https://github.com/pzhren/DW-ViT
- 动机:将多尺度和分支注意力引入window-based attention。现有窗口注意力仅使用单窗口设定,这可能会限制窗口配置对模型性能影响的上限。作者们由此引入多尺度窗口attention,并对不同尺度的窗口分支加权组合,提升多尺度表征能力。
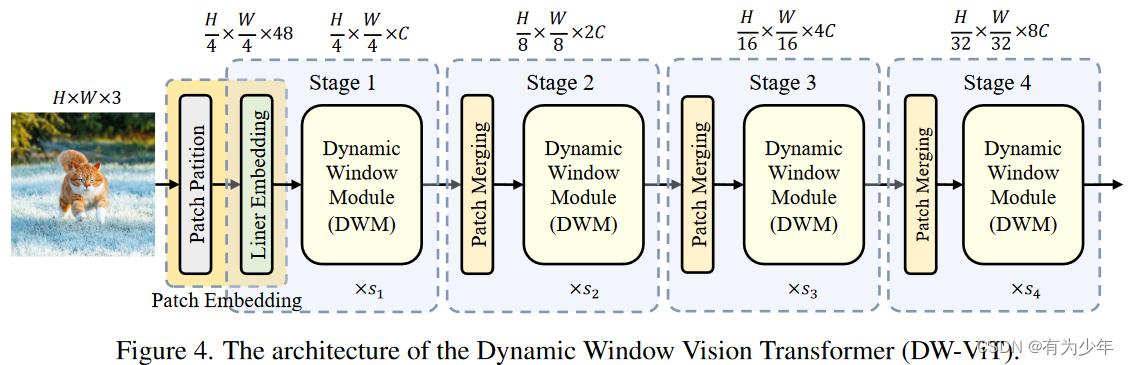
核心内容
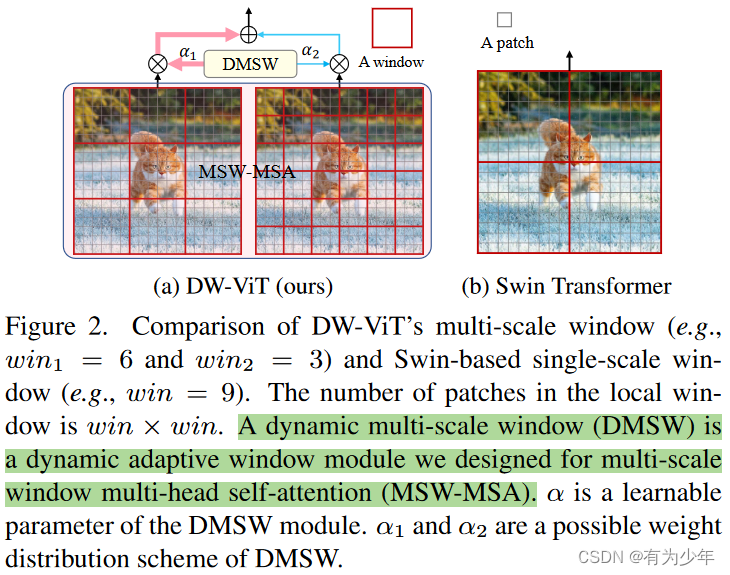
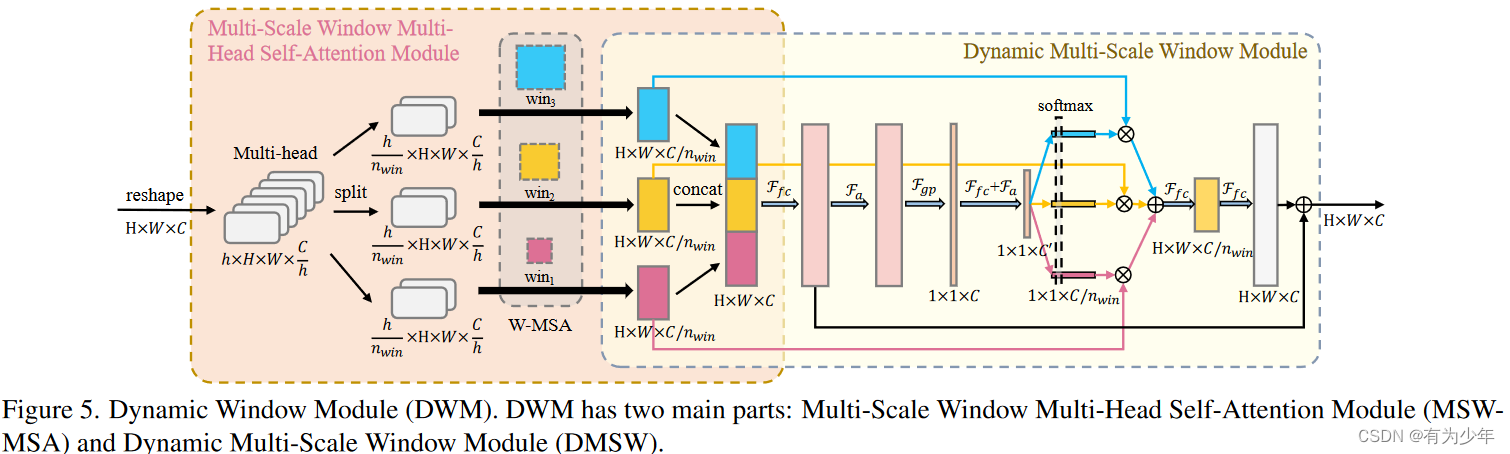
- single-scale window multi-head attention (SSW-MSA) -> dynamic window module (DWM) = multi-scale window multi-head selfattention module+dynamic multi-scale window module。基于此构建的DW-ViT可以动态地改善模型的多尺度信息建模功能,同时确保相对较低的计算复杂性。
- multi-scale window multi-head selfattention module (MSW-MSA) 负责提取多尺度窗口信息:
- 对attention要计算的特征的头分成nwin组,每组使用一个不同的window scale。
- 每个window scale对应的组独立计算window attention。
- 结果沿着头的维度(或者通道维度)拼接。
- dynamic multi-scale window module (DMSW) 动态增强这些多尺度信息。通过集成每个尺度分支的特征来生成对应的权重。基于这些权重来对不同分支集成加和后,与原各分支输出拼接并线性变换后的结果加和得到最终输出。
- multi-scale window multi-head selfattention module (MSW-MSA) 负责提取多尺度窗口信息:
- 为了跨窗口信息交互,这里延续了Swin的shift的设计,对DWM不同分支按照窗口大小独立应用shift操作。处理后再移动回来。这样改进DWM可以得到dynamic shifted window (DSW)模块。通过交替堆叠DWM和DSW,可以避免信息交换的退化。
- 针对不同大小的窗口内应用独立的相对位置偏置。这会被加到每个头的QK/sqrt(d)上,之后再送入softmax。
局限性
- 虽然性能不错,但是引入了少量额外的参数和计算。
- 就 DWM 的动态窗口机制而言,部分计算预算仍然分配给了次优的可选窗口。 然而,理想的策略是将整个计算预算分配给网络每一层最有潜力的窗口。
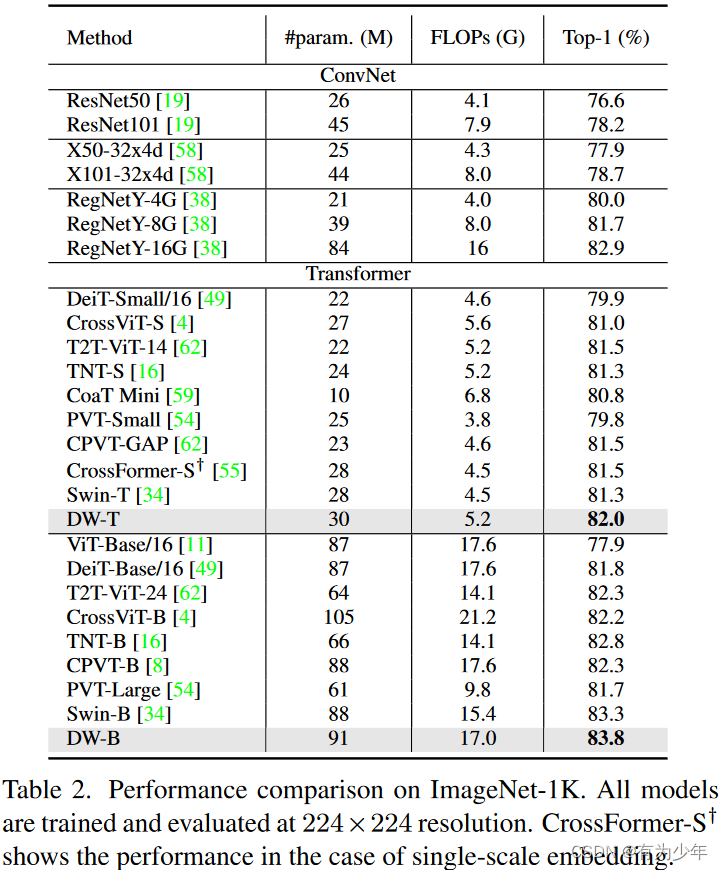
实验结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









