






 本文讨论了一道关于求职者与企业匹配的问题,涉及n家公司和q个求职者,每家公司有m个工作,对IQ、EQ、AQ有最低要求。通过查分和三维前缀和技巧,实现在线查询每名求职者能获得offer的公司数量。算法复杂度优化至O(min(m,c)nm+c3+q),并提供了C++代码实现。
本文讨论了一道关于求职者与企业匹配的问题,涉及n家公司和q个求职者,每家公司有m个工作,对IQ、EQ、AQ有最低要求。通过查分和三维前缀和技巧,实现在线查询每名求职者能获得offer的公司数量。算法复杂度优化至O(min(m,c)nm+c3+q),并提供了C++代码实现。
原题链接
题目大意
有
n
n
n 家公司,第
i
i
i 家公司有
m
i
m_i
mi 个工作,每个工作对
I
Q
/
E
Q
/
A
Q
IQ / EQ / AQ
IQ/EQ/AQ 三项属性各有下限要求。如果对于某个求职者,其满足一家公司的任意一项工作的三维属性要求,则公司会给其发offer 。
有
q
q
q 个求职者,对于每个求职者,求有多少家公司会发offer 。
询问强制在线。
1
≤
n
≤
1
0
6
1 \leq n \leq 10^6
1≤n≤106
1
≤
q
≤
2
×
1
0
6
1 \leq q \leq 2 \times 10^6
1≤q≤2×106
1
≤
m
i
≤
1
0
6
,
∑
m
i
≤
1
0
6
1 \leq m_i \leq 10^6,\sum m_i \leq 10^6
1≤mi≤106,∑mi≤106
1
≤
a
i
,
b
i
,
c
i
≤
400
1 \leq a_i,b_i,c_i \leq 400
1≤ai,bi,ci≤400
题解
分析
题目要求强制在线,
q
q
q 的范围在
2
×
1
0
6
2 \times 10^6
2×106 的范围内,即
l
o
g
n
logn
logn 的范围,我们考虑提前把表打好输出。已知如果这个属性满足某个公司,则大于它的属性必然都满足该公司,只需考虑额外的即可,具有单调性,所以我们可以用 查分 解决这个问题。
拆解
单独对于一个公司,考虑不同属性的要求:
若只考虑一个属性,则易得,只需要看最小的即可,放查分上可以把满足的标记
1
1
1,不满足的标记
0
0
0 ,跑前缀和即可;
若只考虑两个属性,则易得,工作中两个维度均大于某个要求的将不作任何贡献(如图中灰色部分)
,同样的,我们把满足条件的节点扣
1
1
1 ,将肯定不做出贡献的扣
0
0
0 。
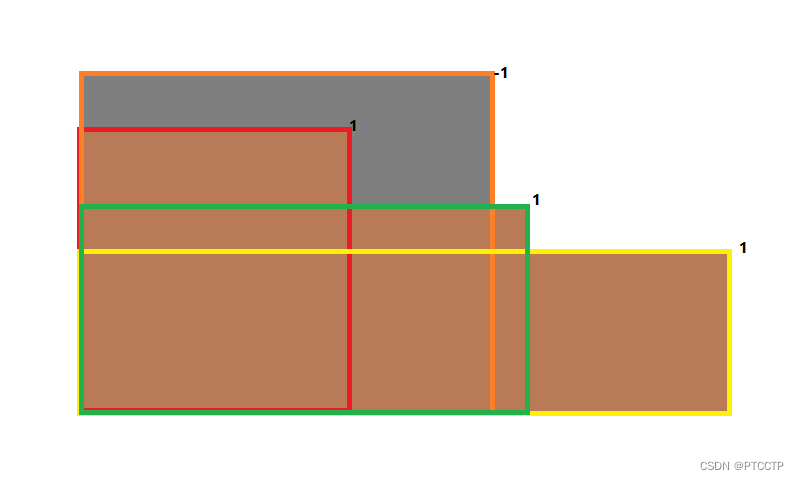
先将工作按某一维度排序,然后跑二位前缀和即可;
解题
将上述方法推展到三维,容易想到,我们可以枚举第三种维度的可能,一层层分开,由题可得,分得的最多层数为
m
i
n
(
m
,
c
)
min(m,c)
min(m,c) 然后跑一次二维,按照之前的方法打上标记,最后跑三维前缀和即可。注意,只有一份工作的第三维度小于当前第三维的值的时候才能做出贡献,每层做完之后要消除对后面的影响。这样的复杂度刚好卡过题目的要求,约为
O
(
m
i
n
(
m
,
c
)
n
m
+
c
3
+
q
)
O(min(m,c)nm+c^3+q)
O(min(m,c)nm+c3+q)。
我们一拍脑袋,发现可以做出贡献的图像中只会加入一次某工作,最多会删除一次,所以我们可以维护对加入某工作的影响,用
s
e
t
set
set 来保存,这样我们的复杂度就可以变成
O
(
l
o
g
m
×
n
m
+
c
3
+
q
)
O(log m \times nm+c^3+q)
O(logm×nm+c3+q) 有一定的时间剩余不那么危险。
参考代码
#include<bits/stdc++.h>
#define ll long long
#include <random>
using namespace std;
template<class T>inline void read(T&x)
{
x=0;
char c=getchar(),last=' ';
while(!isdigit(c))
last=c,c=getchar();
while(isdigit(c))
x=x*10+c-'0',c=getchar();
x=last=='-'?-x:x;
}
const int N=1e6+5,M=405;
const int mod=998244353;
int g[405][405][405];
int n,q,seed;
ll ans=0;
pair<int,pair<int,int>>f[N];
set<pair<int,int> > s;
int ksm(int a,int b) //快速幂
{
int ret=1;
while(b)
{
if(b&1)
ret=1ll*ret*a%mod;
a=1ll*a*a%mod;
b>>=1;
}
return ret;
}
pair<int,int> Pre(pair<int,int> a)
{
auto it=s.lower_bound(a);
it--;
return *it;
}
pair<int,int> Next(pair<int,int> a)
{
auto it=s.upper_bound(a);
return *it;
}
void add(int a,pair<int,int> b,int c) //更新影响
{
g[a][b.first][b.second]+=c;
g[a][Next(b).first][b.second]-=c;
}
int main()
{
read(n);
read(q);
for(int i=1;i<=n;i++)
{
int m;
read(m);
for(int j=1;j<=m;j++)
{
read(f[j].first);
read(f[j].second.first);
read(f[j].second.second);
}
sort(f+1,f+m+1);
s.clear();
s.insert(make_pair(401,0));
s.insert(make_pair(0,401));
for(int j=1;j<=m;j++)
{
auto x=f[j].second;
auto it=s.upper_bound(x);
it--;
if(it->second<=x.second) //无贡献部分
continue;
add(f[j].first,*it,-1);
s.insert(x);
add(f[j].first,Pre(x),1);
while(Next(x).second>=x.second) //维护错判的部分
{
add(f[j].first,Next(x),-1);
s.erase(Next(x));
}
add(f[j].first,x,1);
}
}
for(int i=1;i<M;i++) //三维前缀和
for(int j=0;j<M;j++)
for(int k=0;k<M;k++)
g[i][j][k]+=g[i-1][j][k];
for(int i=0;i<M;i++)
for(int j=1;j<M;j++)
for(int k=0;k<M;k++)
g[i][j][k]+=g[i][j-1][k];
for(int i=0;i<M;i++)
for(int j=0;j<M;j++)
for(int k=1;k<M;k++)
g[i][j][k]+=g[i][j][k-1];
read(seed);
std::mt19937 rng(seed);
std::uniform_int_distribution<> u(1,400);
int lastans=0;
for (int i=1;i<=q;i++)
{
int IQ=(u(rng)^lastans)%400+1;
int EQ=(u(rng)^lastans)%400+1;
int AQ=(u(rng)^lastans)%400+1;
lastans=g[IQ][EQ][AQ];
ans=(ans+1ll*ksm(seed,q-i)*lastans%mod)%mod;
}
printf("%lld",ans);
}

















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









