




转载自微信公众号: 顿见智能
视频可在微信公众号 顿见智能 观看 链接 浙大cad开源从自我中心通过骨骼驱动人体和预测动作及世界状态
1 [开源|从自我中心视角学习驱动人体及预测, ICCV25,浙江大学&香港中文大学&上海交通大学&上海AI Lab ]
EgoAgent: A Joint Predictive Agent Model in Egocentric Worlds
EgoAgent 能够联合学习(i)以自我为中心的观察的视觉表征,(ii)通过骨骼运动进行 3D 人体动作预测,以及(iii)在语义特征空间中预测未来世界状态。我们证明,这三种能力可以通过模仿现实世界中的人类互动和经验来获得。
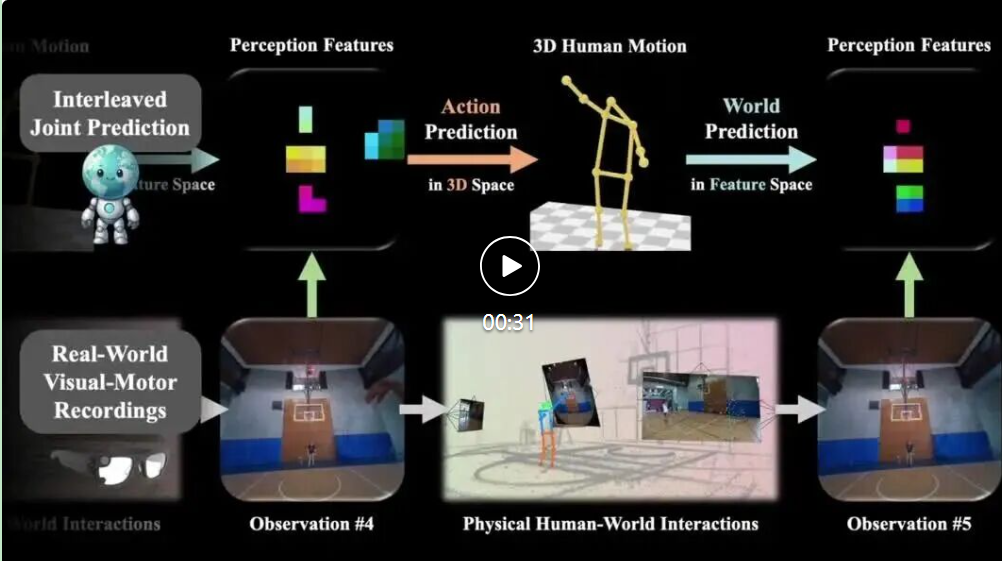
学习一个能够像人类一样行动的代理模型——能够共同感知环境、预测未来并从第一人称视角采取行动——是计算机视觉领域的一项基本挑战。
现有方法通常针对这些能力分别训练模型,但这些模型无法捕捉到它们之间的内在关系,也无法相互学习。受人类通过感知-行动循环进行学习的启发,我们提出了 EgoAgent,这是一个统一的代理模型,可以在单个 Transformer 中同时学习表示、预测和行动。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











