



12月8日,智谱AI开源了GLM-4.6V系列多模态大模型。这一发布在技术层面带来两个重要进展:原生多模态工具调用能力和超十万token上下文窗口。

GLM-4.6V包含两个版本。GLM-4.6V主模型采用超百亿总参数,约120亿激活参数的MoE架构,面向云端和高性能集群部署。GLM-4.6V-Flash则是9B参数的轻量版本,针对本地部署和低延迟场景优化,免费提供使用。
从技术角度看,GLM-4.6V的显著特性在于原生Function Calling能力。模型可以直接处理图像、截图作为工具输入参数,无需先转换为文本描述。视觉输出(如图表、网页渲染结果)也能被模型直接解析并整合进推理链路。这打通了从"视觉感知"到"可执行动作"的完整通路,为多模态Agent提供了统一的技术基座。
相比前代GLM-4.5V,新版本在成本控制上也有明显改进。API调用价格降低50%,输入为每百万tokens仅需一元,输出为三元。
技术架构:MoE与视觉编码器
GLM-4.6V继承GLM-4.5V的MoE(Mixture-of-Experts)架构。这种设计允许模型在保持106B总参数规模的情况下,每次推理仅激活12B参数,有效降低计算成本。
在多模态处理层面,模型采用典型的三段式结构。视觉编码器(Vision Encoder)把图像转换为特征表示,这一组件基于深度卷积网络或Transformer架构,处理原始图像并提取视觉语义。MLP适配器(MLP Adapter)作为视觉和语言模态的桥梁,将视觉特征对齐到语言模型的嵌入空间。LLM解码器(LLM Decoder)基于GLM架构,负责理解整合后的多模态信息并生成响应。
GLM-4.6V的上下文窗口在训练阶段扩展至128K tokens。这一指标在实际应用中意味着模型可以处理长文档、多图像输入乃至连续视频流。相比GLM-4.5V,新版本在长上下文理解能力上有进一步提升。模型还支持任意长宽比和达4K分辨率的图像输入,这种灵活性在处理UI截图、文档扫描等非标准尺寸图像时尤为重要。
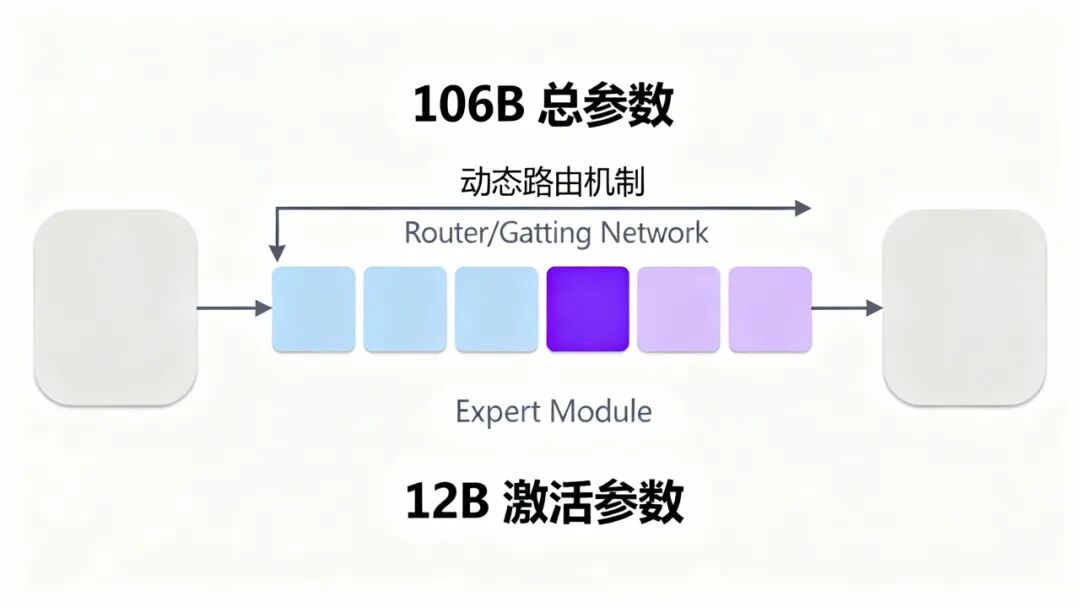
Alt text: MoE混合专家架构示意图,展示106B总参数、12B激活参数的动态路由机制和Expert模块结构
原生工具调用:从感知到执行
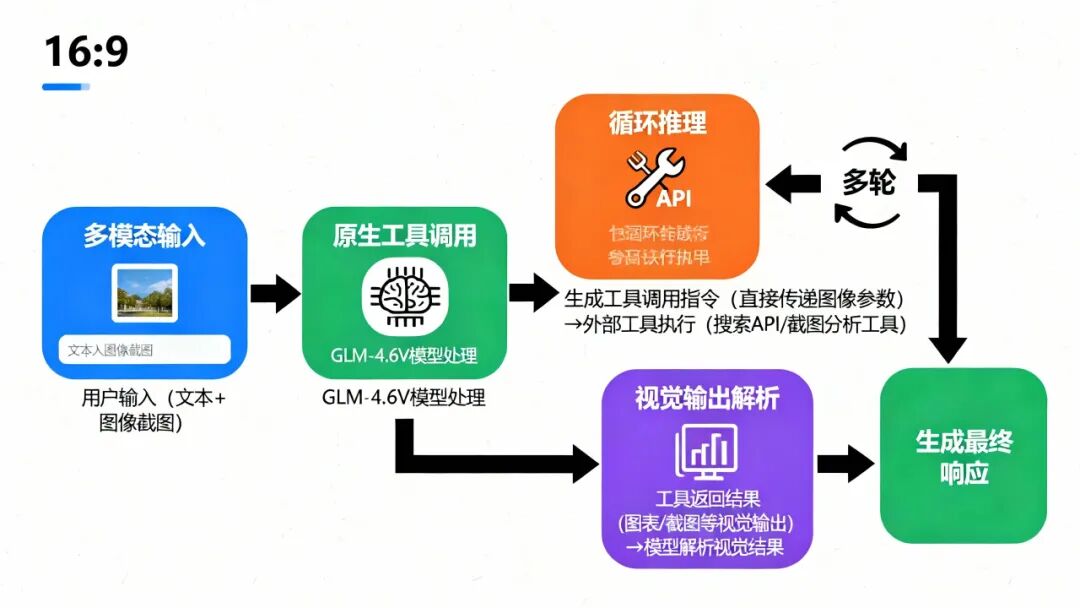
GLM-4.6V最关键的技术突破在于原生Function Calling能力。这一特性允许模型直接以多模态形式调用外部工具,而无需中间层转换。
具体流程如下。当用户输入包含视觉信息时,模型可以直接把图像当参数扔进工具。比如在调用搜索API时,直接传递截图而非图像描述文本。工具返回的图表、网页截图等视觉结果能被模型直接读取并整合进后续推理。根据中间结果,模型可以决定下一步要调用的工具,形成完整的决策链。
这种能力在多模态Agent应用中尤为关键。以GUI自动化为例,模型接收屏幕截图后,识别界面元素(按钮、输入框、菜单),生成操作指令(点击坐标、输入文本),根据执行结果的截图调整后续动作。
模型还具备前端代码复制能力。给定UI截图,它能生成像素级精准的HTML/CSS代码,并支持基于自然语言指令的视觉编辑。这一特性在Web开发和UI设计场景中有实际应用价值。
性能验证:Benchmark数据解读
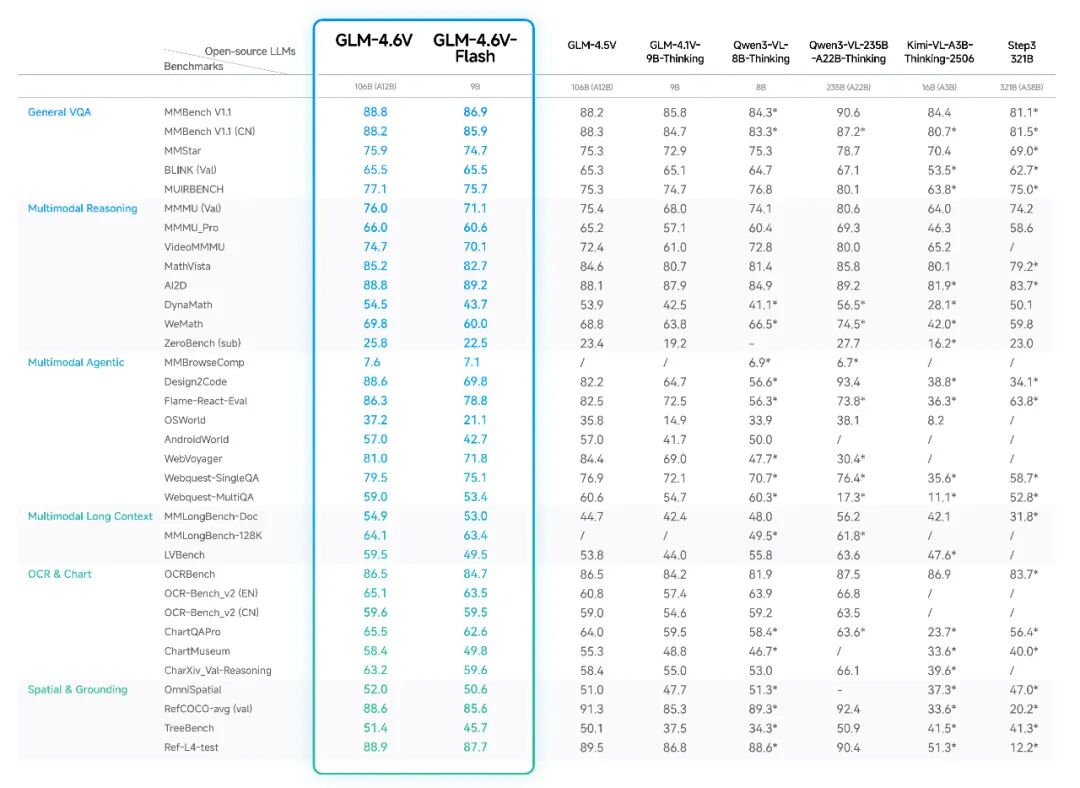
智谱AI声称GLM-4.6V在同等参数规模下在多个benchmark上表现优异。根据官方发布的数据,模型在多个主流多模态评测基准上表现如下:
在视觉理解方面,模型在MMBench、MathVista、OCRBench等benchmark上均有实测数据支撑。这些benchmark覆盖了场景理解、复杂多图分析、空间认知等基础能力。
长上下文处理是GLM-4.6V的关键优势。128K tokens的窗口允许模型同时处理多个图像、长视频或大量文档页面。在实际测试中,模型似乎能够保持对早期输入的记忆并进行跨图像推理。GUI Agent操作能力上,模型支持屏幕阅读、图标识别、桌面操作辅助等任务,智谱提供的桌面助手Demo应用展示了这些能力的实际效果。复杂文档解析是另一个测试重点,模型能够理解混合了文本、图表、公式的研究报告,提取关键信息并回答问题。
官方也承认模型存在一些局限性:纯文本QA能力有待提升,计数准确性和特定人物识别仍有改进空间。这些问题在多模态大模型中较为常见。
在部署方式上,模型支持多种推理框架:
vLLM部署支持tensor-parallel分布式推理,适合高吞吐场景。官方推荐配置为4卡并行,支持原生工具调用和Thinking Mode。
SGLang部署提供更高的推理效率,特别是在视频理解等长上下文场景。官方建议增加SGLANG_VLM_CACHE_SIZE_MB以优化视频处理性能。
xLLM支持允许模型在国产芯片(如昇腾NPU)上运行,降低部署门槛。
在成本计算方面,GLM-4.6V-Flash的9B参数规模使其能在消费级GPU上运行。一张RTX 4090即可支撑较小批次的推理任务。主模型的106B规模则需要多卡并行,通常需要4张4个80GB显存的GPU。
API服务的定价策略相对亲民。输入1元/百万tokens的价格使其适合大量图像输入的场景。相比闭源竞品,这一价格有明显优势。
开源策略与应用前景
GLM-4.6V的发布在多模态大模型领域具有几个关键意义。
技术层面,原生Function Calling能力为多模态Agent应用提供了更直接的实现路径。相比之前需要将视觉信息转为文本再传递给工具的方案,这种原生支持减少了信息损失并提高了执行效率。
工程层面,9B轻量版本的推出降低了部署门槛。对于需要本地部署或对延迟敏感的场景,这个版本提供了可行的解决方案。
开源策略是另一个重要亮点。完整的权重、代码和文档开放,使得开发者能够深入理解模型实现细节并进行定制化开发。这对于需要在私有环境中部署或针对特定领域微调的团队尤为重要。
在应用场景上,GLM-4.6V适合以下几类任务:
-
多模态搜索与信息提取:利用原生工具调用能力构建图文搜索系统
-
GUI自动化:开发智能桌面助手或软件测试工具
-
文档理解:处理复杂的研究报告、技术文档、财报等
-
代码生成:基于UI截图生成前端代码
需要注意的是,模型仍有一些知名限制,如纯文本推理能力、计数准确性等。在实际应用中需要根据具体任务进行测试验证。
总体而言,GLM-4.6V在多模态工具调用方向做出了实质性突破。对于需要构建多模态Agent或处理复杂视觉任务的团队,这是一个值得关注的开源方案。
社区地址
OpenCSG社区:https://opencsg.com/models/zai-org/GLM-4.6V
hf社区:https://huggingface.co/zai-org/GLM-4.6V
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。
更多推荐





















 980
980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









