



一、创建最新vLLM 实例
登录OneThingAI平台OneThingAI算力云 - 热门GPU算力平台,进入镜像中心,选择vLLM推理引擎,点击创建实例(8卡可跑,更好的体验需要2台H20)

通过【文件管理】查看DeepSeek 相关模型

二、补全DeepSeek V3 0324模型相关配置文件
cd /app/deepseek
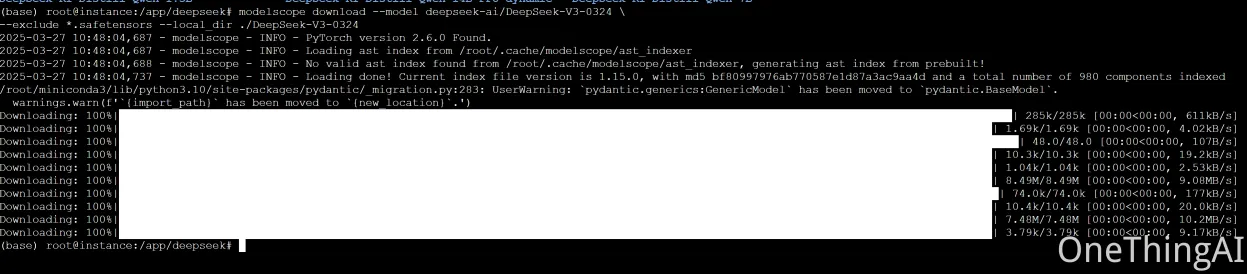
modelscope download --model deepseek-ai/DeepSeek-V3-0324 \
--exclude *.safetensors --local_dir ./DeepSeek-V3-0324结果如图:
三、启动DeepSeek V3 0324
vllm serve /app/deepseek/DeepSeek-V3-0324 --tensor-parallel-size 8 --max-model-len 8192 \
--enable-prefix-caching --trust-remote-code --host 0.0.0.0 --port 6006 --enforce-eager \
--max_num_seqs=16 --gpu_memory_utilization 0.95四、补全 Qwen2.5-VL-32B-Instruct
模型路径:/root/.cache/modelscope/hub/models/Qwen

cd /root/.cache/modelscope/hub/models/Qwen
modelscope download --model Qwen/Qwen2.5-VL-32B-Instruct \
--exclude *.safetensors --local_dir ./Qwen2___5-VL-32B-Instruct
五、启动Qwen2.5-VL-32B-Instruct
vllm serve /root/.cache/modelscope/hub/models/Qwen/Qwen2___5-VL-32B-Instruct --tensor-parallel-size 8\
--max-model-len 128000 --enable-prefix-caching --trust-remote-code --host 0.0.0.0 --port 6006 \
--enforce-eager --gpu_memory_utilization 0.95


















 2462
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









