







 超级会员免费看
超级会员免费看
系列文章目录
第一篇 AI 数据治理:LangChain4J 文本分类器在字段对标中的高级玩法
第二篇 LangChain4J + OpenTelemetry:AI 调用全链路可观测方案
第三篇 企业级 Neo4j GraphRAG:向量检索 + 图谱扩散怎么融合?Neo4j GraphRAG 给你答案
第四篇 多模型路由 + Resilience4j 熔断降级,Java 大模型服务的降级与兜底体系
第五篇「企业级智能体」LangChain4j Multi-Agent:角色分离 + 协同编排实战
第六篇 LangChain4j + MCP:从工具协议到生产级 Agent
第七篇 企业级 Prompt 管理中心:实验分流 + 曝光埋点 + 可回溯,版本化/AB/DSL/可观测全齐
文章目录
- 系列文章目录
- 前言:为什么只做向量 RAG 不够用?
- 一、GraphRAG 的核心设计
- 二、代码实践
-
- 2.1 模型接入:Embedding + Chat(LangChain4jConfig)
- 2.2 Neo4j Driver 与 RAG 参数(Neo4jConfig + RagProperties)
- 2.3 GraphRAG 问答入口:/api/rag/ask(RagController)
- 2.4 实体词表自增长:/api/entity/discover + /api/entity/upsert
- 2.5 Dto
- 2.6 融合检索核心:GraphRagService(Vector + Graph + Fusion)
- 2.5 启动初始化:Schema 自修复 + Seed + Ingest(GraphRagApplication)
- 三、配置与示例数据
- 总结
前言:为什么只做向量 RAG 不够用?
很多团队的 RAG 都止步于:切 Chunk → 向量化 → TopK 相似度召回 → 拼上下文 → 让 LLM 回答。这条链路上线很快,但实际落地后经常遇到三个硬问题:
命中不稳定:问题表达一变,向量召回就漂;尤其是术语、代码 token、配置项这类文本。
解释性弱:为什么命中这段?为什么没命中那段?很难从“纯相似度”讲清楚。
词表维护成本高:新术语、新函数、新产品名层出不穷,靠人手补“实体/别名”永远慢半拍。
所以我做了一个工程化的 GraphRAG :
向量检索 + 图检索融合(Fusion),并且提供一条非常关键的闭环:实体自动发现 → 自动入库 → 立即生效。
一、GraphRAG 的核心设计
✅ GraphRAG 全链路 Mermaid 架构图(流程图)
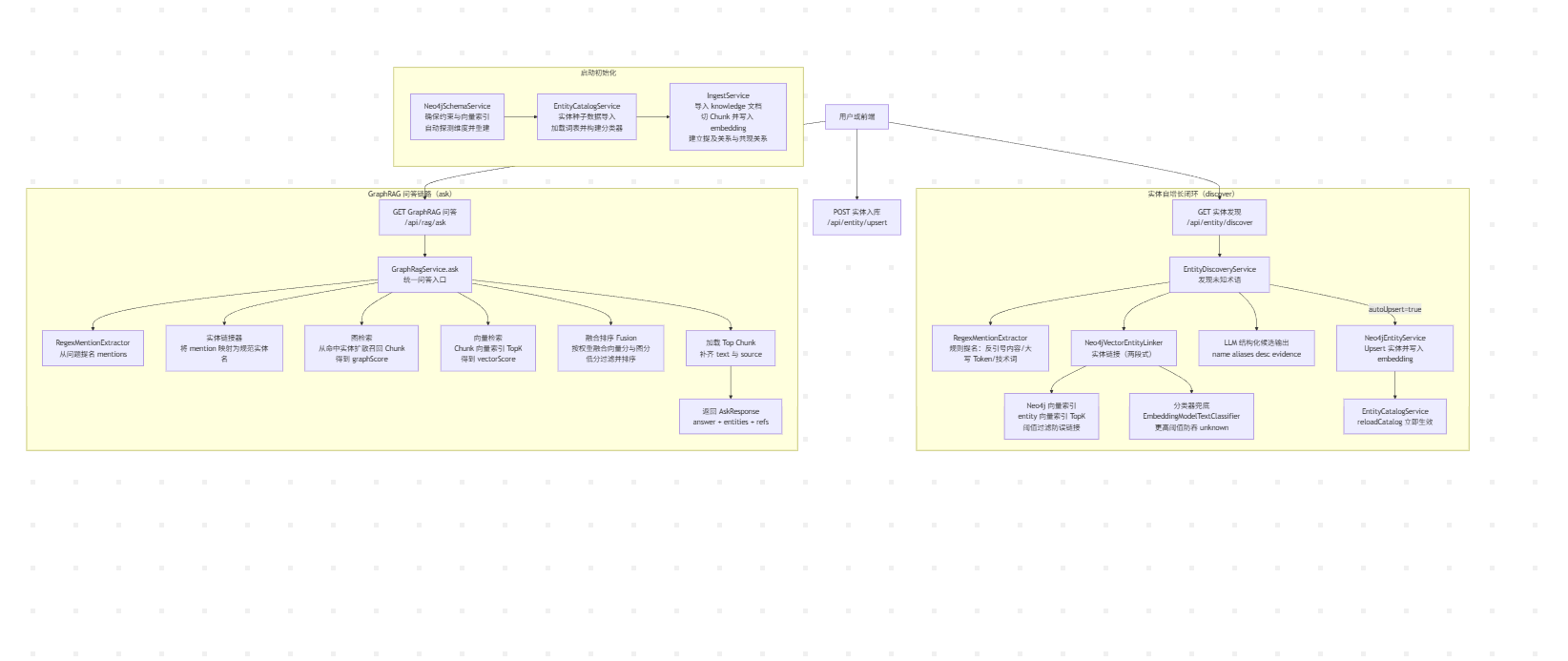
整体链路:
-
实体提取/实体链接:
- 从用户问题中提取

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









