




系列文章目录
第一章 Xinference 分布式推理框架的部署
第二章 LLaMA Factory 微调框架的部署
第三章 LLaMA Factory 微调框架数据预处理加载
前言
随着大语言模型(Large Language Models)的快速发展,如何高效地对模型进行微调,已成为模型开发和应用中的重要环节。而在微调过程中,数据预处理与加载是确保模型性能的基础环节。面对庞大且复杂的数据集,合理的预处理策略和高效的数据加载机制,不仅能提高训练效率,还能有效改善模型的泛化能力。
一、数据集简介
1.初始数据集
LLaMA Factory下载完成后,自带部分数据集。路径为下载后的data目录下,如:D:\LLaMA-Factory\data。
对于默认数据集,在启动LLaMA Factory时若提前进入了源代码的根目录,页面即可直接选择。
启动命令如下:
cd /d D:\LLaMA-Factory
set TRANSFORMERS_CACHE=
set HF_HOME=D:\anaconda3\envs\llama-factory\cache
llamafactory-cli webui
页面即可加载到自带的数据集
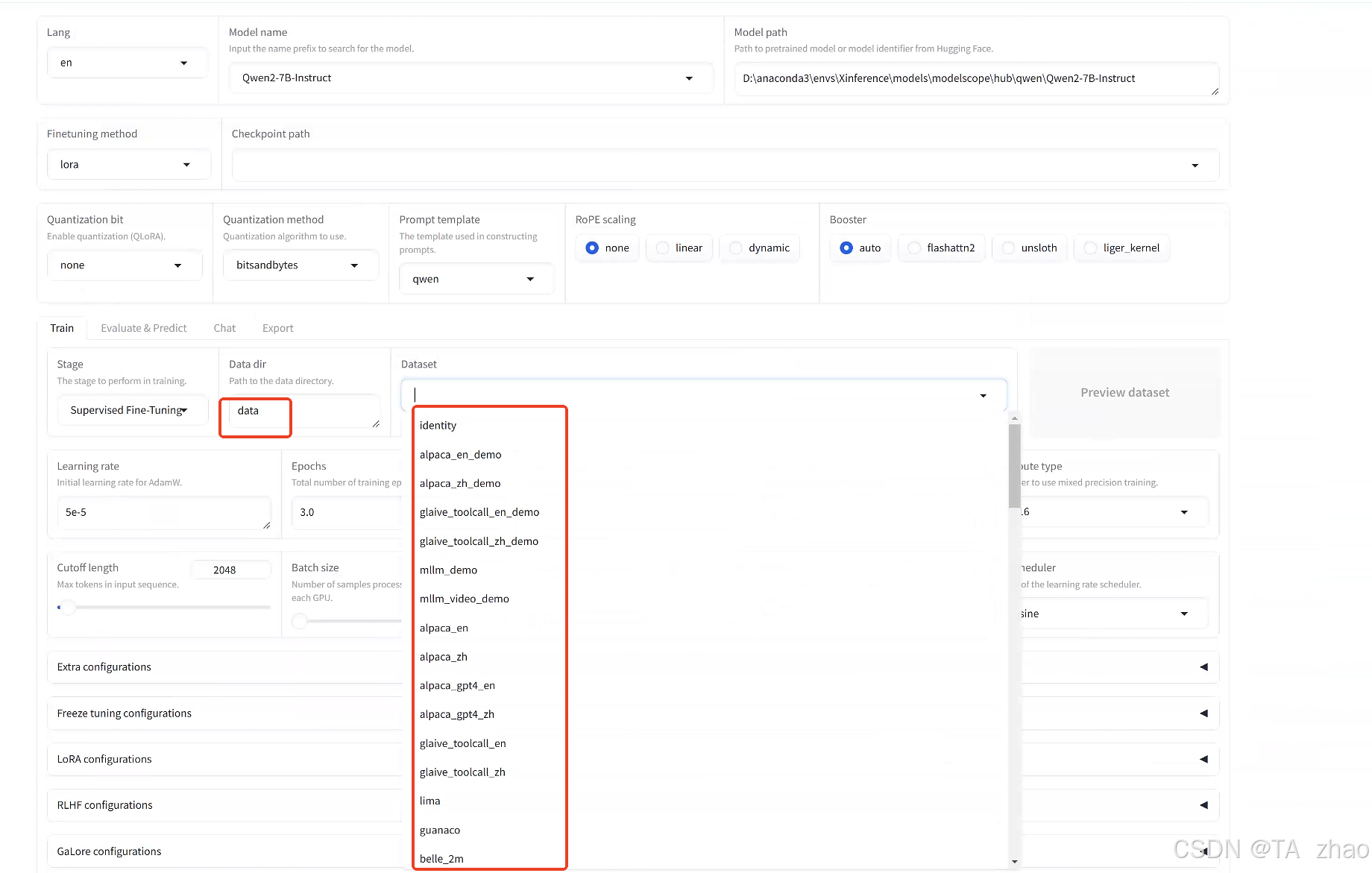
Data dir为存储数据集的目录,Dataset即为自带数据集。
注意:若在anaconda中启动时未进入源码目录,这里的Dataset会为空,加载不到数据集。
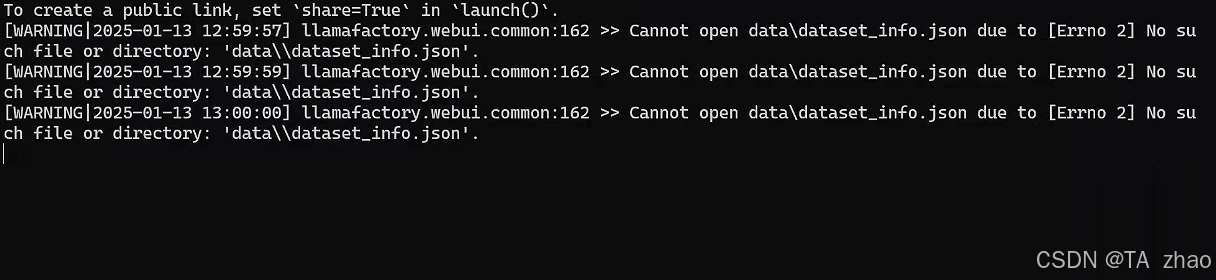
需要指定Data dir目录,如:D:\LLaMA-Factory\data
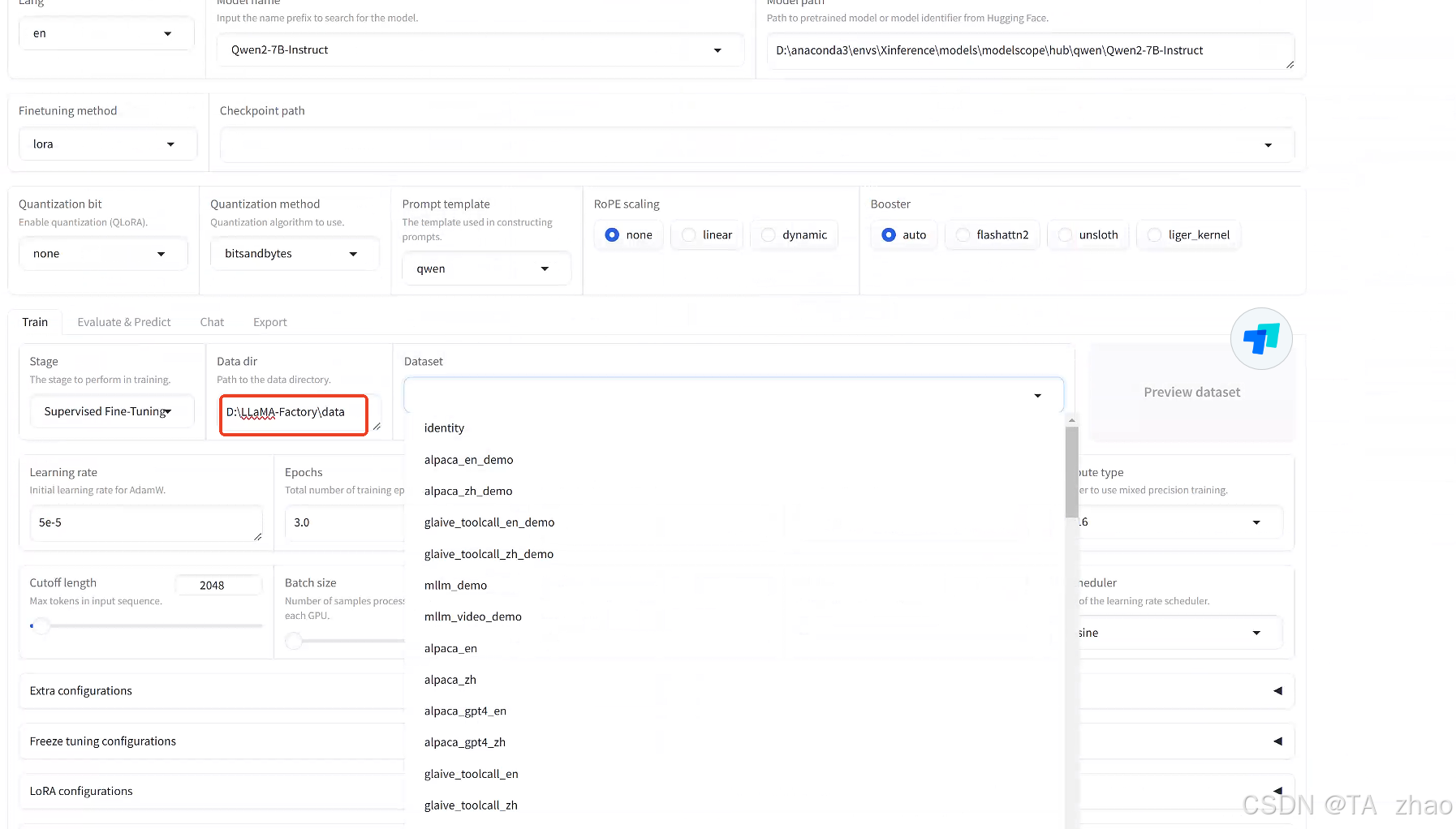
2.自定义数据集
除了使用默认数据集,还可以使用自定义数据集。使用自定义数据集需要在该目录下的dataset_info.json中添加数据集描述,修改 dataset: 数据集名称配置。数据集目前支持 alpaca 和 sharegpt的格式。如下:
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"subset": "数据集子集的名称(可选,默认:None)",
"split": "所使用的数据集切分(可选,默认:train)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"num_samples": "该数据集所使用的样本数量。(可选,默认:None)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)",
"videos": "数据集代表视频输入的表头名称(默认:None)",
"chosen": "数据集代表更优回答的表头名称(默认:None)",
"rejected": "数据集代表更差回答的表头名称(默认:None)",
"kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"
}
}
2.1 Alpaca 格式
指令监督微调数据集
在指令监督微调(Instruction Supervised Fine-tuning)中,数据中的 instruction 列和 input 列的内容会拼接在一起,形成模型需要理解的人类指令;output 列的内容则作为对应的模型回答标签。system 列则包含系统提示词,用于为模型提供全局的上下文引导。
history 列存储了由多个字符串二元组((instruction, response))构成的列表,每个二元组分别表示历史对话中的一轮指令和回答。历史消息中的回答内容不仅为模型提供对上下文的理解能力,还能通过监督学习的方式帮助模型更好地生成符合上下文逻辑的输出。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
与之对应dataset_info.json 中的数据集描述为:
"数据集名称": {
"file_name": "数据集文件名称.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
预训练数据集
在预训练时,只有 text 列中的内容会用于模型学习。
[
{"text": "document"},
{"text": "document"}
]
与之对应dataset_info.json 中的数据集描述为:
"数据集名称": {
"file_name": "数据集文件名称.json",
"columns": {
"prompt": "text"
}
}
偏好数据集
偏好数据集用于奖励模型训练、DPO 训练、ORPO 训练和 SimPO 训练。它需要在 chosen 列中提供优质回答,并在 rejected 列中提供劣质回答。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"chosen": "优质回答(必填)",
"rejected": "劣质回答(必填)"
}
]
对于上述格式的数据,dataset_info.json 中的数据集描述为:
"数据集名称": {
"file_name": "数据集文件名称.json",
"ranking": true,
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}
本篇不包含多模态数据集。
2.2 Sharegpt 格式
指令监督微调数据集
相比 alpaca 格式的数据集,sharegpt 格式支持更多的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
对于上述格式的数据,dataset_info.json 中的数据集描述为:
"数据集名称": {
"file_name": "数据集文件名称.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
预训练数据集
尚不支持,目前仅支持 alpaca 格式的预训练数据集。
偏好数据集
Sharegpt 格式的偏好数据集同样需要在 chosen 列中提供更优的消息,并在 rejected 列中提供更差的消息。
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "gpt",
"value": "模型回答"
},
{
"from": "human",
"value": "人类指令"
}
],
"chosen": {
"from": "gpt",
"value": "优质回答"
},
"rejected": {
"from": "gpt",
"value": "劣质回答"
}
}
]
对于上述格式的数据,dataset_info.json 中的数据集描述为:
"数据集名称": {
"file_name": "数据集文件名称.json",
"formatting": "sharegpt",
"ranking": true,
"columns": {
"messages": "conversations",
"chosen": "chosen",
"rejected": "rejected"
}
}
本篇不包含多模态数据集。
二、数据预处理
上述介绍了数据集文本和描述的格式,现在介绍一下数据的获取和数据的处理,使其符合其要求的格式。数据除了直接写相关的数据文件,也可通过对开源数据进行处理来获取。此处从以下地址获取开源数据集。https://modelscope.cn/datasets
此处下载的是法律相关的数据集:
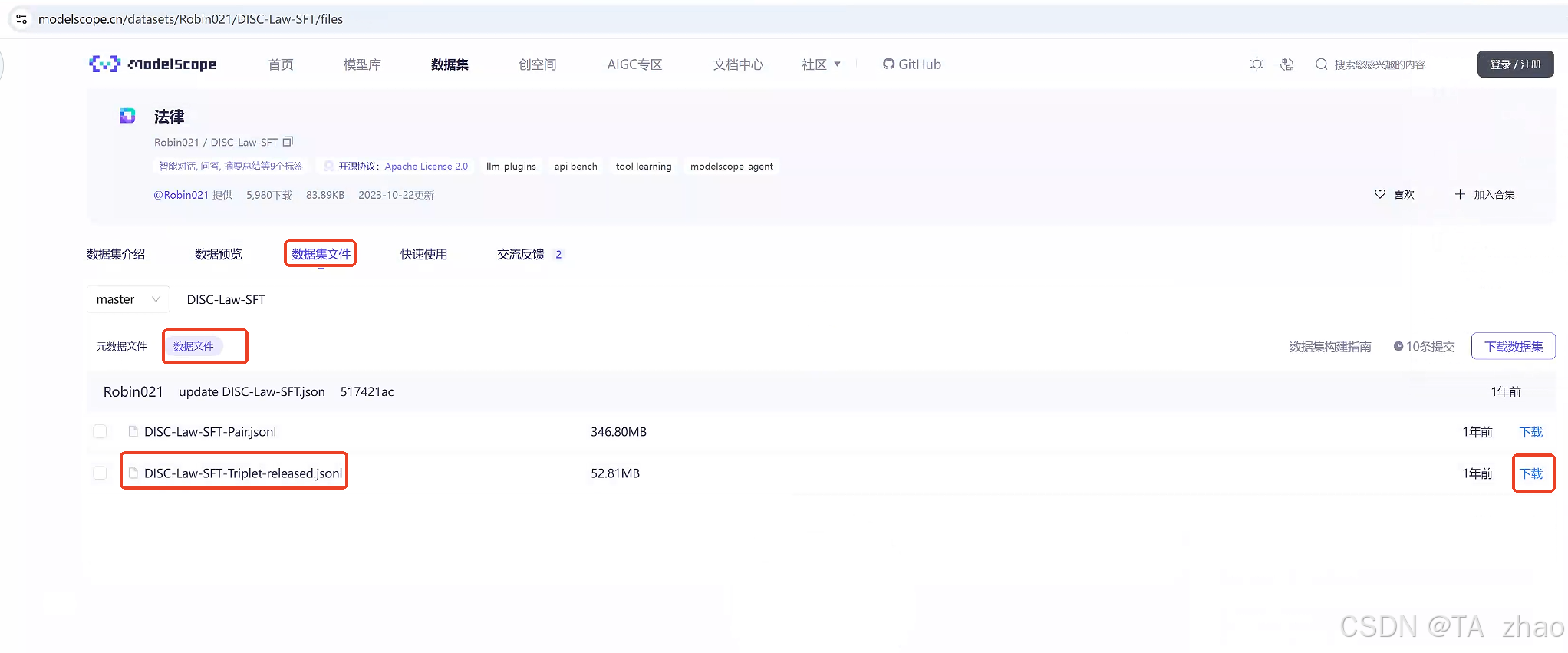
现在的开源数据已经下载完成,现在需要将数据处理为LLaMA Factory所要求的数据格式,现在以Sharegpt 格式的指令监督微调数据集为例,进行数据的处理。数据量过大,可以通过python或者java代码处理源数据文件,此处以python为例,代码可参考如下:
import json
json_data = []
print("-----------------------数据处理开始------------------------")
with open('D:\download\DISC-Law-SFT-Triplet-released.jsonl', 'r', encoding='utf-8') as file:
for line in file:
data = json.loads(line)
json_data.append(data)
template = []
for idx, data in enumerate(json_data[:]):
conversation = [
{
"from": "human",
"value": data["input"]
},
{
"from": "gpt",
"value": data["output"]
}
]
template.append({
"conversions": conversation,
"system": "",
"tools": ""
})
output_file_path = "data/law_data.json"
with open(output_file_path, 'w', encoding='utf-8') as outfile:
json.dump(template, outfile, ensure_ascii=False, indent=2)
print("-----------------------数据处理完成------------------------")
处理完成之后,数据如下:
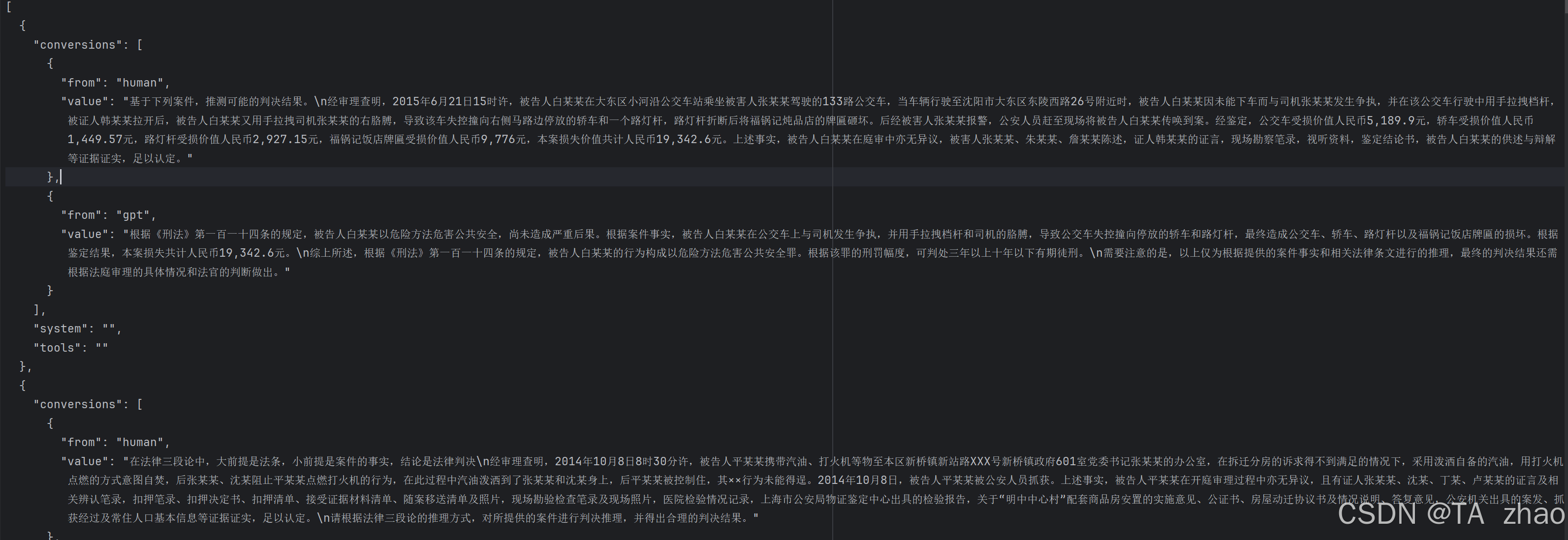
编辑同目录下的dataset_info.json ,增加数据集描述如下:
"lawsjj": {
"file_name": "law_data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
此时刷新LLaMA Factory的页面,即可在数据集下拉列表中看到自定义的数据集:lawsjj。
总结
在大语言模型的微调过程中,数据预处理与加载是一项至关重要的工作,它直接影响模型的训练效率与性能表现。本文浅谈了LLaMA Factory数据预处理与加载机制,下期分享使用LLaMA Factory 针对Xinference 本地模型的微调训练。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









