







系列文章目录
第一篇 AI 数据治理:LangChain4J 文本分类器在字段对标中的高级玩法
文章目录
前言
AI 服务的“慢 / 贵 / 不稳定”,往往不是单点问题,而是链路问题:
- Prompt 组装是否过重?
- 工具调用是否抖动?
- LLM 推理是否超时 / 限流?
- Token 是否在某些场景突然暴涨?
✅ 没有可观测,你只能靠猜;有可观测,你能靠数据定位。
本文用一个可运行的 Demo,把一次/api/chat请求拆成清晰的 入口 → 工具 → LLM → 返回,并把 Trace / Metrics / Logs 同时打通。
一、简介
1.1 全链路拓扑
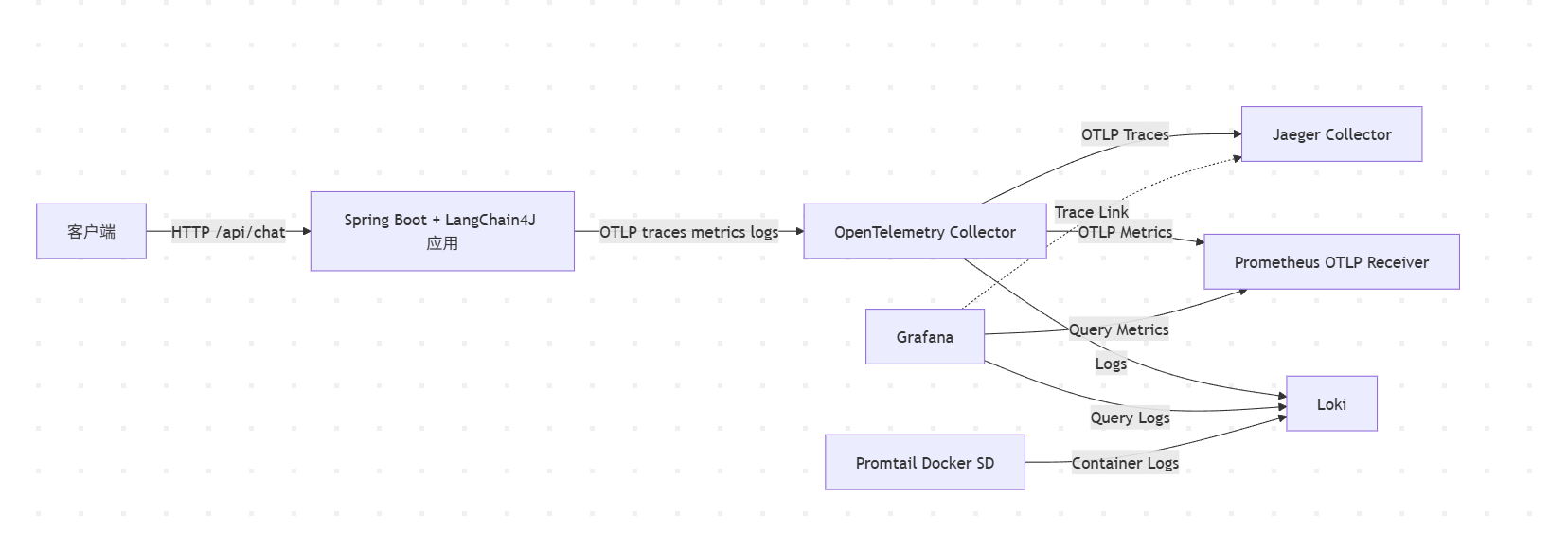
1.2 组件职责
| 组件 | 它负责什么 | 你能得到什么 |
|---|---|---|
| LangChain4J | 调用 OpenAI 兼容模型(DashScope compatible-mode) | LLM 返回内容 + TokenUsage |
| Micrometer Observation | 业务语义埋点、span 分段、上下文传播 | ai.pipeline / ai.tool.* / ai.llm |
| OpenTelemetry + OTLP | 标准化导出协议 | traces / metrics 统一上报 |
| Jaeger | Trace 收集与 UI | span 耗时、错误、上下游关系 |
| Prometheus v3 | OTLP Metrics 接收 | QPS、延迟直方图、Token 分布 |
| Grafana | 统一看板 | Metrics + Logs(可选再接 Trace 数据源) |
| Loki + Promtail | 日志采集与检索 | 结构化日志 + trace 关联排障 |
⚠️ 低基数原则(非常重要)
指标/Span 的标签只用:model / scene / provider / tool 这类有限枚举。
不要把 sessionId / message 当标签,否则会造成指标爆炸、存储膨胀、查询变慢。
-
应用侧(Spring Boot + LangChain4J)
- LangChain4J(OpenAiChatModel):负责调用兼容 OpenAI 协议的大模型(你这里是 DashScope 的 compatible-mode)
- Micrometer Observation / @Observed:在业务代码里做“埋点语义化”,把 AI Pipeline 拆成多个 span
- MeterRegistry(Counter/Timer/Summary):把 LLM 延迟、Token 使用量沉淀为可查询指标
-
Tracing:OpenTelemetry + Jaeger
- spring-boot-starter-opentelemetry:让 Spring Boot 4 一键具备 OTel Tracing 能力(Micrometer Tracing bridge + exporter)
- OTLP Exporter:把 trace 数据通过 OTLP 发给 Jaeger
- Jaeger all-in-one:接收 OTLP 并提供 UI(16686)查看调用链
-
Metrics:Prometheus(OTLP Receiver)+ Grafana
- Prometheus v3 OTLP Receiver:直接接收应用通过 OTLP 推送的 metrics
- Grafana:配置 Prometheus 数据源,做仪表盘与告警
-
Logging:结构化日志 + Loki + Promtail
- ECS 结构化日志:日志字段更适合检索、聚合
- Loki:存日志
- Promtail:采集 Docker 容器日志推送到 Loki
二、代码实践
2.1.应用侧:配置与模型接入
2.1.1 配置属性:Provider & Tools 收口
package org.example.config;
import jakarta.validation.constraints.NotBlank;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.validation.annotation.Validated;
import java.time.Duration;
@Validated
@ConfigurationProperties(prefix = "ai.provider")
public record AiProviderProperties(
@NotBlank String baseUrl,
@NotBlank String model,
Duration timeout
) {}
package org.example.config;
import jakarta.validation.constraints.NotBlank;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.validation.annotation.Validated;
@Validated
@ConfigurationProperties(prefix = "ai.tools")
public record AiToolsProperties(@NotBlank String baseUrl) {}
✅ 把模型地址/模型名/超时、工具地址抽成“可运营配置”,后续做多模型路由、灰度策略都不动业务代码。
2.1.2 LangChain4J:OpenAiChatModel(OpenAI 兼容协议)
package org.example.config;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableConfigurationProperties(AiProviderProperties.class)
public class LangChain4jConfig {
@Bean
public ChatModel chatModel(AiProviderProperties props) {
return OpenAiChatModel.builder()
.baseUrl(props.baseUrl())
.apiKey(System.getenv("LANGCHAIN4J_KEY"))
.modelName(props.model())
.timeout(props.timeout())
.build();
}
}
- 作用:对外统一成 ChatModel,业务层只依赖接口
- 可观测收益:后面我们在 ai.llm span 里打上 model/provider 维度,Jaeger 上能按模型过滤,Metrics 也能按 model 分组
2.1.3 工具调用客户端:RestClient Builder 统一配置
package org.example.config;
import org.springframework.boot.restclient.autoconfigure.RestClientBuilderConfigurer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestClient;
@Configuration
public class RestClientConfig {
@Bean
public RestClient.Builder restClientBuilder(RestClientBuilderConfigurer configurer) {
return configurer.configure(RestClient.builder());
}
}
- 作用:让 RestClient 走 Spring Boot 的统一配置(拦截器、超时、观测等)
- 链路价值:工具调用也会在 trace 里形成独立 span(你在业务里进一步手动包了 Observation)
2.1.4 入口 Controller
package org.example.controller;
import jakarta.annotation.Resource;
import org.example.dto.ChatRequest;
import org.example.dto.ChatResponse;
import org.example.service.AiChatService;
import org.springframework.web.bind.annotation.*;
@RestController
public class ChatController {
@Resource
private AiChatService aiChatService;
@PostMapping("/api/chat")
public ChatResponse chat(@RequestBody ChatRequest chatRequest) {
return aiChatService.chat(chatRequest);
}
}
DTO
package org.example.dto;
public record ChatRequest(String sessionId, String scene, String message) {}
public record ChatResponse(String sessionId, String answer) {}
2.2 观测核心:Pipeline 分段 Trace + 指标 + Token
2.2.1 下游工具服务(演示依赖 + Trace 透传)
package org.example.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.time.Instant;
import java.util.Map;
@RestController
public class ToolController {
@GetMapping("/api/tools/time")
public Map<String, Object> time() {
return Map.of("now", Instant.now().toString());
}
}
- 作用:模拟一个内部工具/依赖服务(真实项目里可以是:查询配置、查用户画像、查数据库、查规则引擎等)
- 链路价值:你能在 Jaeger 看到 ai.tool.time 的耗时,并判断“慢在工具还是慢在 LLM”
2.2.2 AiChatService:把一次 AI 请求拆成 3 段 Span
✅ 建议命名:
- ai.pipeline:总链路(入口到返回)
- ai.tool.time:工具调用
- ai.llm:模型调用
✅ 指标:
- ai_chat_requests_total:请求量
- ai_llm_latency:LLM 延迟(直方图 + P95/P99)
package org.example.service;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.output.TokenUsage;
import io.micrometer.core.instrument.*;
import io.micrometer.observation.Observation;
import io.micrometer.observation.ObservationRegistry;
import io.micrometer.observation.annotation.Observed;
import jakarta.annotation.Resource;
import org.example.config.AiProviderProperties;
import org.example.config.AiToolsProperties;
import org.example.dto.ChatRequest;
import org.example.dto.ChatResponse;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestClient;
import java.util.Map;
@Service
public class AiChatService {
@Resource private ChatModel chatModel;
@Resource private ObservationRegistry observationRegistry;
private final Counter requests;
private final Timer llmLatency;
private final DistributionSummary promptTokens;
private final DistributionSummary completionTokens;
private final RestClient toolClient;
private final AiProviderProperties props;
public AiChatService(AiProviderProperties props,
AiToolsProperties toolsProperties,
RestClient.Builder restClientBuilder,
MeterRegistry meterRegistry) {
this.props = props;
// 内部工具调用(演示 trace 分段)
this.toolClient = restClientBuilder
.baseUrl(System.getProperty("TOOLS_BASE_URL", toolsProperties.baseUrl()))
.build();
// Metrics:请求量
this.requests = Counter.builder("ai_chat_requests_total")
.description("Total AI chat requests")
.tag("model", props.model())
.register(meterRegistry);
// Metrics:LLM 延迟
this.llmLatency = Timer.builder("ai_llm_latency")
.description("LLM call latency")
.tag("model", props.model())
.publishPercentileHistogram()
.register(meterRegistry);
// Metrics:Token
this.promptTokens = DistributionSummary.builder("ai_llm_tokens_prompt")
.description("Prompt tokens")
.tag("model", props.model())
.register(meterRegistry);
this.completionTokens = DistributionSummary.builder("ai_llm_tokens_completion")
.description("Completion tokens")
.tag("model", props.model())
.register(meterRegistry);
}
@Observed(name = "ai.chat", contextualName = "ai-chat")
public ChatResponse chat(ChatRequest req) {
return Observation.createNotStarted("ai.pipeline", observationRegistry)
.lowCardinalityKeyValue("scene", safe(req.scene()))
.lowCardinalityKeyValue("model", props.model())
.observe(() -> {
String prompt =
"你是企业级 Java AI 助手,请用工程化语言回答。\n" +
"当前时间: " + fetchNowFromTool() + "\n" +
"场景: " + safe(req.scene()) + "\n" +
"用户问题: " + safe(req.message()) + "\n";
requests.increment();
String answer = llmLatency.record(() -> invokeModel(prompt));
return new ChatResponse(req.sessionId(), answer);
});
}
private String fetchNowFromTool() {
return Observation.createNotStarted("ai.tool.time", observationRegistry)
.lowCardinalityKeyValue("tool", "time")
.observe(() -> {
Map<?, ?> body = toolClient.get()
.uri("/api/tools/time")
.retrieve()
.body(Map.class);
Object now = (body != null) ? body.get("now") : null;
return now != null ? now.toString() : "unknown";
});
}
private String invokeModel(String prompt) {
return Observation.createNotStarted("ai.llm", observationRegistry)
.lowCardinalityKeyValue("provider", "openai-compatible")
.lowCardinalityKeyValue("model", props.model())
.observe(() -> {
dev.langchain4j.model.chat.response.ChatResponse resp =
chatModel.chat(UserMessage.from(prompt));
TokenUsage usage = resp.tokenUsage();
if (usage != null) {
if (usage.inputTokenCount() != null) promptTokens.record(usage.inputTokenCount());
if (usage.outputTokenCount() != null) completionTokens.record(usage.outputTokenCount());
}
return resp.aiMessage().text();
});
}
private static String safe(String s) {
return (s == null || s.isBlank()) ? "unknown" : s;
}
}
2.3 配置:Tracing / Metrics / Logging
# App
spring.application.name=ai-observability
server.port=8080
# AI Provider
ai.provider.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
ai.provider.model=qwen-long
ai.provider.timeout=10s
ai.tools.base-url=http://localhost:8080
# Actuator
management.endpoints.web.exposure.include=health,info,metrics,loggers,threaddump,httpexchanges
# Tracing(Demo:100% 采样)
management.tracing.sampling.probability=1.0
management.opentelemetry.tracing.export.otlp.endpoint=http://localhost:4318/v1/traces
management.opentelemetry.tracing.export.otlp.transport=http
management.opentelemetry.tracing.export.otlp.timeout=5s
# Metrics(OTLP -> Prometheus OTLP Receiver)
management.otlp.metrics.export.url=http://localhost:9090/api/v1/otlp/v1/metrics
management.otlp.metrics.export.step=10s
# Logging
logging.structured.format.console=ecs
logging.level.org.example=INFO
logging.level.io.opentelemetry.exporter=INFO
logging.level.io.micrometer.tracing=INFO
- Tracing 关键点:OTLP traces 发给 Jaeger 的 4318(HTTP)
- Metrics 关键点:OTLP metrics 直接推给 Prometheus v3 的 OTLP receiver
- Logging 关键点:ECS 结构化日志便于 Loki 检索(后续建议加入 traceId 字段注入)
2.4 观测栈:Docker Compose
2.4.1 docker-compose.yml
services:
prometheus:
image: prom/prometheus:v3.8.0
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-otlp-receiver"
volumes:
- ./observability/prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports:
- "9090:9090"
jaeger:
image: jaegertracing/all-in-one:1.76.0
environment:
COLLECTOR_OTLP_ENABLED: "true"
ports:
- "16686:16686"
- "4317:4317"
- "4318:4318"
loki:
image: grafana/loki:latest
command: ["-config.file=/etc/loki/config.yml"]
volumes:
- ./observability/loki-config.yml:/etc/loki/config.yml:ro
ports:
- "3100:3100"
grafana:
image: grafana/grafana:latest
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: admin
volumes:
- ./observability/grafana/provisioning:/etc/grafana/provisioning:ro
ports:
- "3001:3000"
depends_on:
- prometheus
- loki
- jaeger
访问入口:
- Grafana:http://localhost:3001(admin/admin)
- Jaeger:http://localhost:16686
- Prometheus:http://localhost:9090
- Loki:http://localhost:3100
2.4.2 Grafana 数据源(datasources.yml)
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:9090
isDefault: true
- name: Loki
type: loki
access: proxy
url: http://loki:3100
作用:Grafana 开箱即用:指标看 Prometheus、日志看 Loki
2.5 验证
- 启动观测栈
docker compose up -d - 启动应用
- 发起请求
- 检查结果
-
Jaeger:http://localhost:16686。service 选 ai-observability,能看到 ai.pipeline / ai.tool.time / ai.llm 等 span(并且 HTTP 调用链路会串起来)
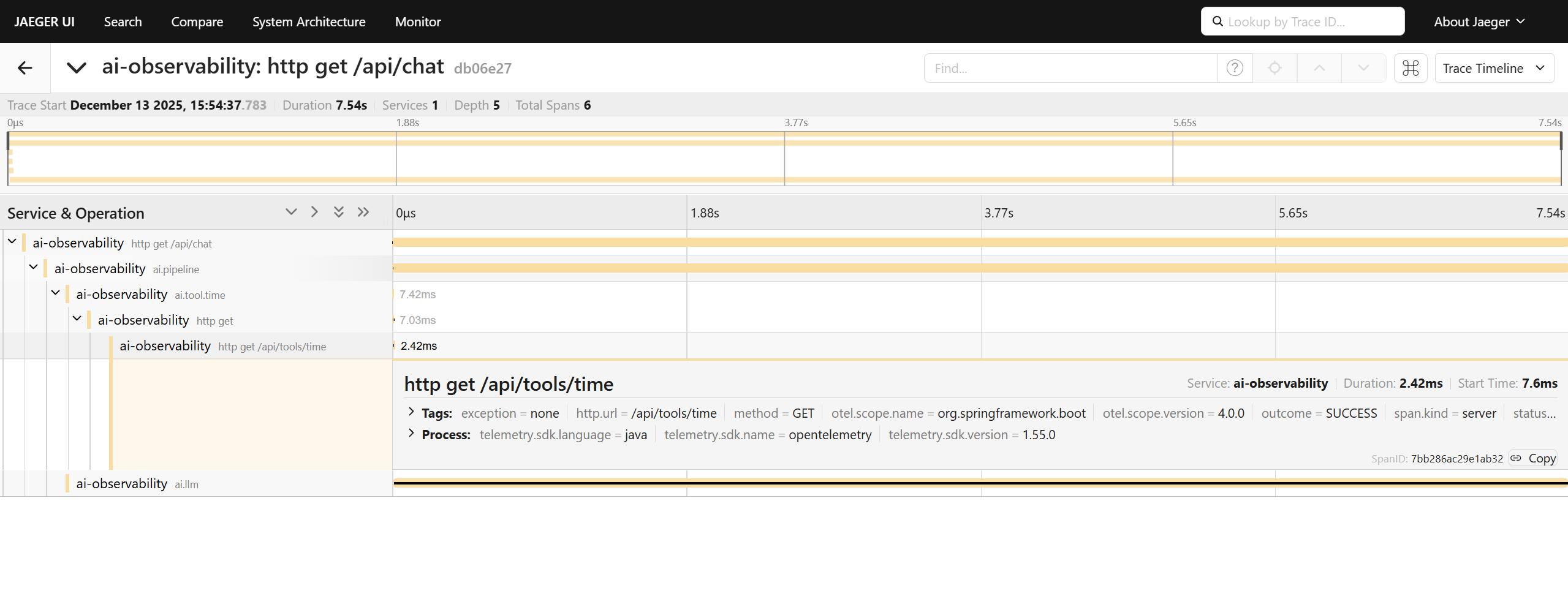
-
Prometheus:http://localhost:9090。查询:ai_chat_requests_total、ai_llm_latency_seconds_count 等(OTLP 推进来的指标)
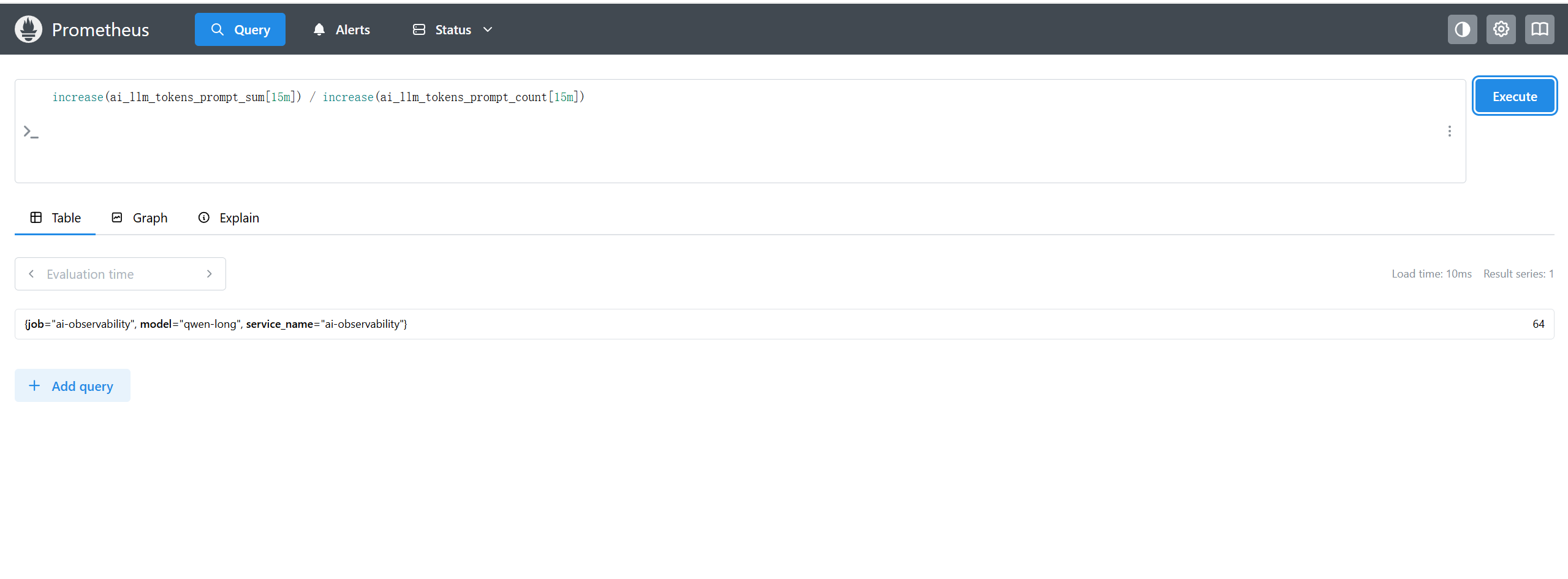
-
Grafana:http://localhost:3000(admin/admin)Explore → Prometheus / Loki 可直接查
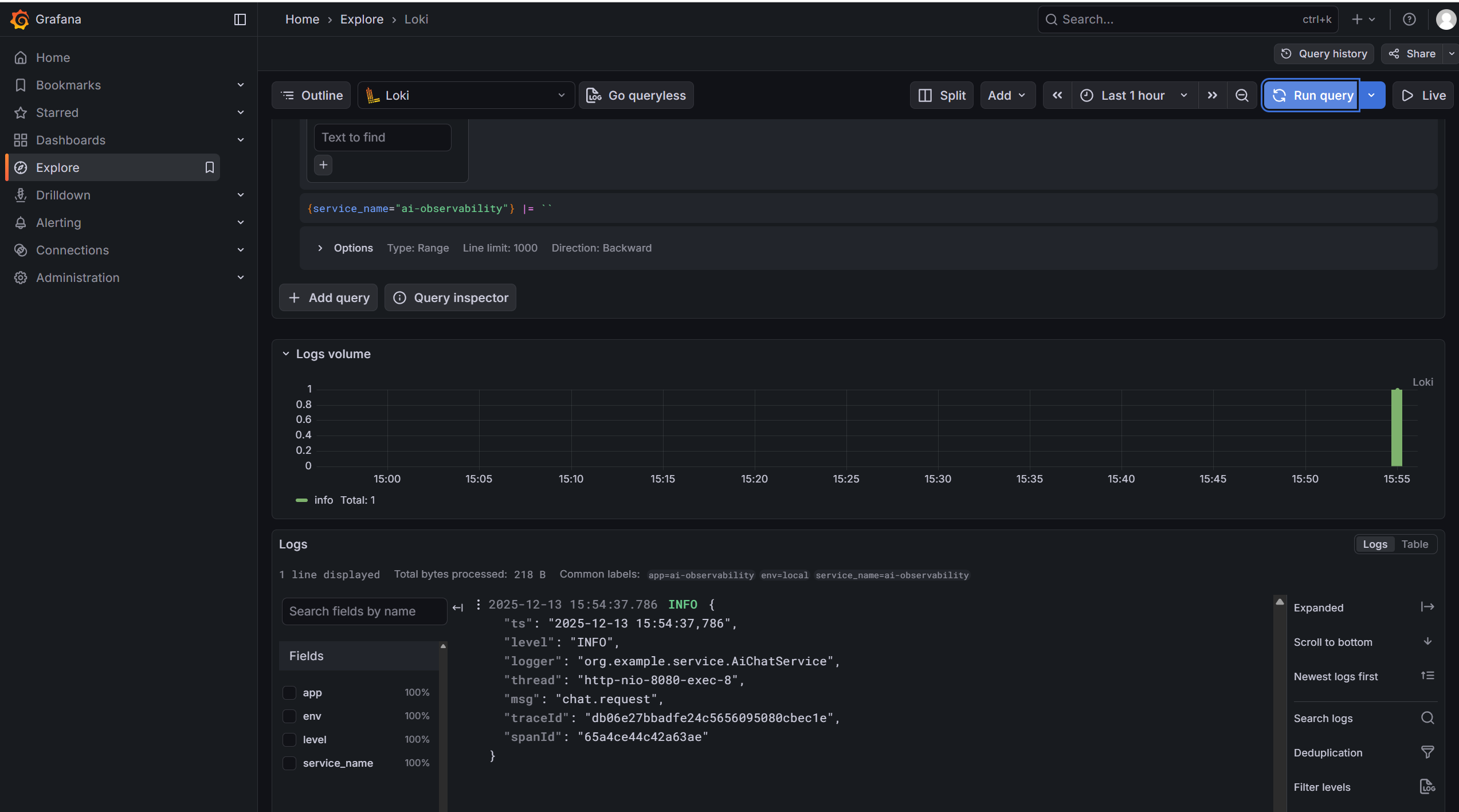
-
2.6 Grafana 查询语句示例(PromQL + LogQL)
说明(Prometheus 指标命名规律)
- Micrometer 的 Timer 通常会导出为
*_seconds_bucket / *_seconds_sum / *_seconds_count(开启直方图时)- Counter 一般保持原名(如
ai_chat_requests_total)- DistributionSummary 通常为
*_sum / *_count / *_max如果你的指标名不完全一致:在 Grafana Explore → Metrics 里先搜索
ai_,再按实际指标名替换。
2.6.1 Prometheus(PromQL)示例
1)AI 请求 QPS(每秒请求数)
sum by (model) (rate(ai_chat_requests_total[5m]))
2)AI 请求在 1 分钟窗口的请求量(更直观)
sum by (model) (increase(ai_chat_requests_total[1m]))
3)LLM 平均耗时(近 5 分钟)
sum by (model) (rate(ai_llm_latency_seconds_sum[5m]))
/
sum by (model) (rate(ai_llm_latency_seconds_count[5m]))
4)LLM 调用次数(用 Timer 的 count)
sum by (model) (rate(ai_llm_latency_seconds_count[5m]))
5)Prompt Token 平均值(近 5 分钟)
sum by (model) (rate(ai_llm_tokens_prompt_sum[5m]))
/
sum by (model) (rate(ai_llm_tokens_prompt_count[5m]))
6)Completion Token 平均值(近 5 分钟)
sum by (model) (rate(ai_llm_tokens_completion_sum[5m]))
/
sum by (model) (rate(ai_llm_tokens_completion_count[5m]))
7)Prompt Token 峰值(近 15 分钟)
max_over_time(ai_llm_tokens_prompt_max[15m])
8)接口层:/api/chat 的 HTTP QPS(Spring 默认指标)
sum(rate(http_server_requests_seconds_count{uri=“/api/chat”}[5m]))
9)接口层:/api/chat 的 P95 延迟(Spring 默认指标)
histogram_quantile(
0.95,
sum by (le) (rate(http_server_requests_seconds_bucket{uri=“/api/chat”}[5m]))
2.6.2 Loki(LogQL)示例
启用了 logging.structured.format.console=ecs,日志通常为 JSON。
常见玩法:先用 | json 解析字段,再进行过滤/聚合。
ECS 中 trace 字段常见为 trace.id(有的链路会变成 trace_id),以你的实际字段为准。
- 查看应用日志(按容器名筛选):{container=~“.ai-observability.”}
- 只看 ERROR:{container=~“.ai-observability.”} | json | level=“ERROR”
- 按关键字检索(例如 ai.llm):{container=~“.ai-observability.”} |= “ai.llm”
- 按 traceId 串起来看(ECS 常见 trace.id):{container=~“.ai-observability.”} | json | trace.id=“YOUR_TRACE_ID”
如果你的字段是 trace_id:{container=~“.ai-observability.”} | json | trace_id=“YOUR_TRACE_ID” - 5 分钟内 ERROR 数量(用于图表):sum(count_over_time({container=~“.ai-observability.”} | json | level=“ERROR”[5m]))
- 按异常关键词统计(例:timeout)
sum(count_over_time({container=~“.ai-observability.”} |= “timeout”[5m]))
总结
这套方案的关键不是“把 OTel 跑起来”,而是把 AI 请求变成 可解释、可量化、可追踪 的流水线:
- Tracing:把一次 AI 请求拆成 pipeline → tool → llm,定位瓶颈不用猜
- Metrics:用 Timer + Counter + Token Summary 把性能与成本沉淀为数据资产
- Logging:结构化日志进入 Loki,为排障提供“证据链”
下一步升级
-
RAG:新增 ai.rag.retrieve / ai.rerank span,定位检索与重排耗时
-
Memory:新增 ai.memory.read / ai.memory.write span,观察命中率与冷启动成本
-
错误分层:对超时、限流、5xx、解析失败打不同 error event,做告警与归因
-
成本面板:按 model/scene 聚合 token,做 TOP 场景与阈值告警(P95 + token 双维)

















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









