




1. 感知机的概念与历史
感知机是由美国学者 Frank Rosenblatt 在 1957 年提出的一种人工神经网络模型。
它是最简单的神经网络形式,主要用于二分类任务。
感知机公式:
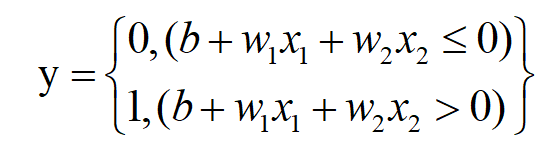
其中:
- w:权重,控制输入信号的重要性
- b:偏置,调整神经元被激活的难易程度
感知机与其他模型的区别:
- 二分类:输出 0 或 1
- 回归:输出实数
- Softmax:输出概率,适用于多分类
2. 感知机的局限性
感知机只能表示线性可分的空间,无法处理异或(XOR)这样的非线性问题。
3. 多层感知机原理
MLP 是最简单的深度神经网络,通过增加隐藏层来解决非线性问题。
基本结构:
- 输入层
- 隐藏层(可多层)
- 输出层
隐藏层大小是超参数,需要根据问题调整。
4. 激活函数
激活函数将输入信号的总和转换为输出信号,增强网络的表示能力。
常见激活函数:
- 阶跃函数:简单但不适合深度学习
- Sigmoid:输出范围 (0, 1)
- Tanh:输出范围 (-1, 1)
- ReLU:(max(0, x),计算简单,广泛使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









