



在网络爬虫开发中,合规爬取与高效数据存储是两个核心环节。本文将详细解析 Robots 协议的核心内容、爬取风险及合规策略,同时深入讲解 TXT 与 CSV 文件存储的实现方法,助你轻松掌握静态网页爬取的数据处理流程。
一. 为什么需要 Robots 协议?
网络爬虫在带来便利的同时,也可能引发三大问题:
性能骚扰:爬虫可能给 Web 服务器带来远超人类访问的资源开销,影响服务器正常运行
法律风险:服务器数据有明确产权归属,未经授权的商业使用可能触犯法律
隐私泄露:部分爬虫可能突破简单访问控制,获取受保护的个人隐私数据
二.Robots 协议的核心规则
Robots 协议(全称网络爬虫排除标准)是网站与爬虫之间的 "约定",通过根目录下的robots.txt文件实现,核心要求包括:
- 必须放置在站点根目录,文件名必须为小写的
robots.txt - 基本语法由
User-agent(爬虫名称)和Disallow(禁止访问路径)组成 - 支持
*通配符(代表所有爬虫)和Allow指令(允许访问路径) -
三.合规爬取建议
- 商业用途爬虫必须严格遵守 Robots 协议
- 大规模爬取需控制访问频率,模拟人类浏览行为
- 敏感数据(如用户信息)严禁爬取和商用
- 可通过网站根目录或百度资源平台(Robots_robots文件检测工具_站长工具_网站支持_百度搜索资源平台)查询目标站点的 Robots 协议
- 四.案例分析:
- 1.txt储存
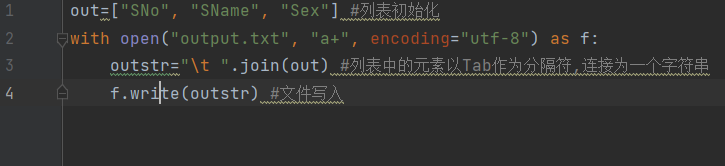
- 2.cvs读取
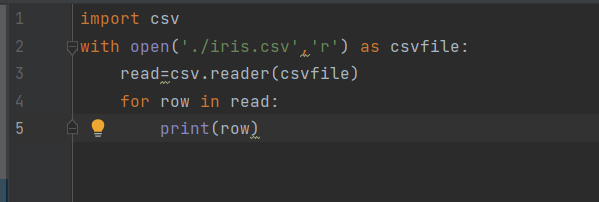
- 3.cvs写入:
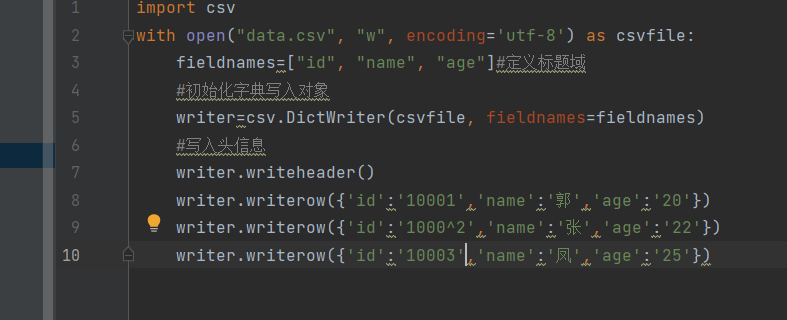
- 运行结果:
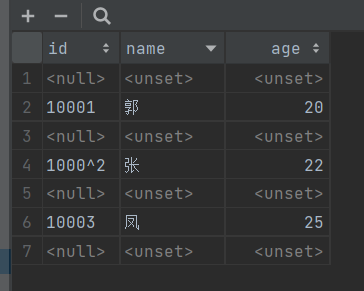
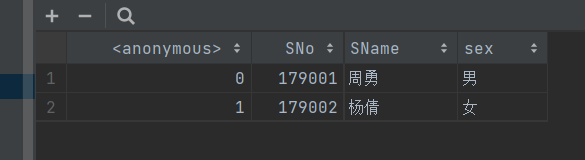
- 络爬虫的核心不仅是技术实现,更包括对合规性的把握。遵守 Robots 协议、尊重数据产权,是每个开发者的基本准则。同时,选择合适的数据存储方式,能大幅提高后续数据处理的效率。

















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









