



一、引言
在机器学习的学习与实践过程中,鸢尾花(Iris)分类和波士顿房价(Boston Housing)回归是两个经典案例,常被用于初学者熟悉分类与回归算法。本文将基于 Scikit - learn 库,详细展示如何使用 K 近邻(K - Nearest Neighbors, KNN)算法分别完成这两个任务,涵盖数据集加载、模型训练、评估以及参数优化等环节。
二、鸢尾花分类任务
(一)数据集介绍
鸢尾花数据集是一类多重变量分析的数据集,包含 150 个样本,对应 3 种鸢尾花品种(setosa、versicolor、virginica ),每个样本有 4 个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度 。
(二)代码实现与步骤解析
- 环境准备与数据集加载

这里通过datasets.load_iris()加载数据集,np.random.seed(0)固定随机种子,确保每次运行代码时,数据集划分等随机操作结果一致。
- 数据集探索

通过这些操作,我们能了解数据集的基本结构,比如特征数量、样本数量、类别情况等,为后续建模做准备。
使用train_test_split函数将数据集按 3:7 的比例划分为训练集和测试集,方便后续用训练集训练模型,测试集评估模型。


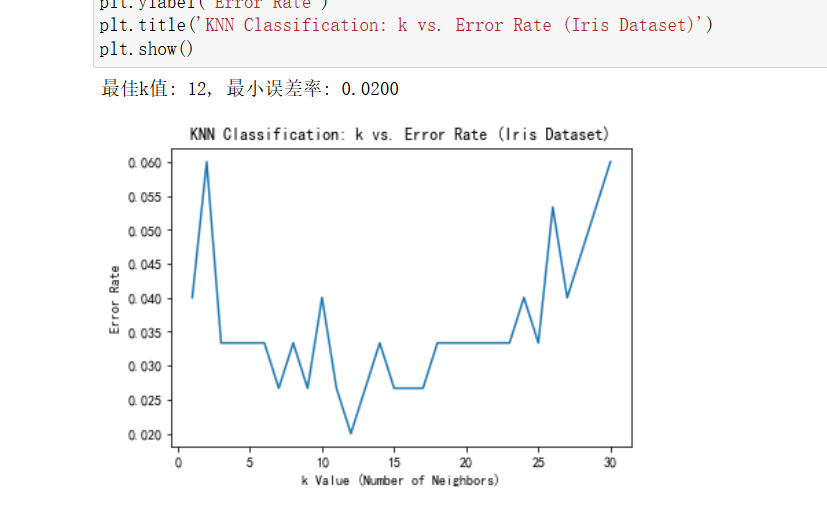
三、波士顿房价回归任务
(一)数据集介绍
波士顿房价数据集包含 506 个样本,13 个特征,目标是预测波士顿地区房屋的 median value(中位数),属于回归任务。特征涉及犯罪率、住宅用地比例、交通便利性等多个方面 。

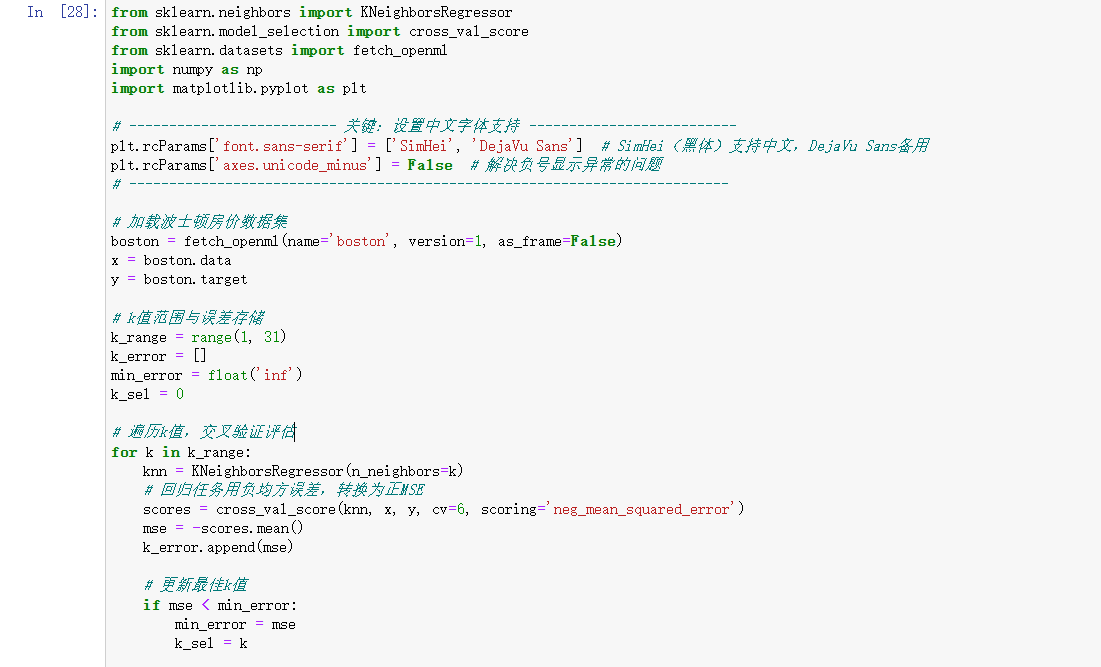

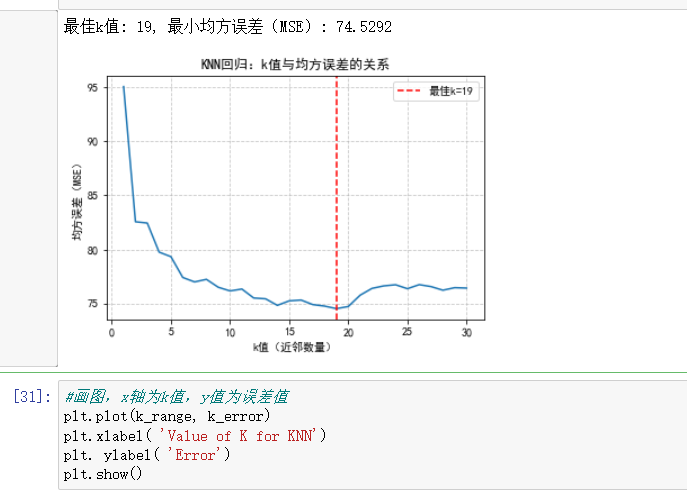
from sklearn.neighbors import KNeighborsRegressor 和from sklearn.neighbors import KNeighborsClassifier区别:
-
用途不同
KNeighborsRegressor:用于回归任务,预测连续型数值(如房价、温度、销售额等)KNeighborsClassifier:用于分类任务,预测离散型类别(如是否患病、图片类别、垃圾邮件判断等)
-
预测原理不同
KNeighborsRegressor:- 找到测试样本的 k 个最近邻
- 对这 k 个邻居的目标值取平均值作为预测结果
KNeighborsClassifier:- 找到测试样本的 k 个最近邻
- 对这 k 个邻居的类别进行投票,得票最多的类别作为预测结果
- (可选)也可通过
weights参数实现加权投票
-
输出结果不同
KNeighborsRegressor的predict()返回连续的数值KNeighborsClassifier的predict()返回离散的类别标签,此外还有predict_proba()方法返回每个类别的概率
四、总结
本文围绕 Scikit - learn 库,详细展示了使用 KNN 算法解决鸢尾花分类和波士顿房价回归问题的完整流程,包括数据集加载、探索、划分、模型训练、预测、评估以及关键参数(K 值)的优化。通过这两个经典案例,能帮助初学者深入理解分类与回归任务的基本流程,以及 KNN 算法在不同任务中的应用方式。同时,也体现了分类和回归任务在数据集结构、模型评估指标等方面的差异,为后续学习更复杂的机器学习算法和项目实践奠定基础。 你可根据实际需求,进一步调整模型参数、尝试其他算法,持续探索机器学习的魅力。

















 8717
8717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









