



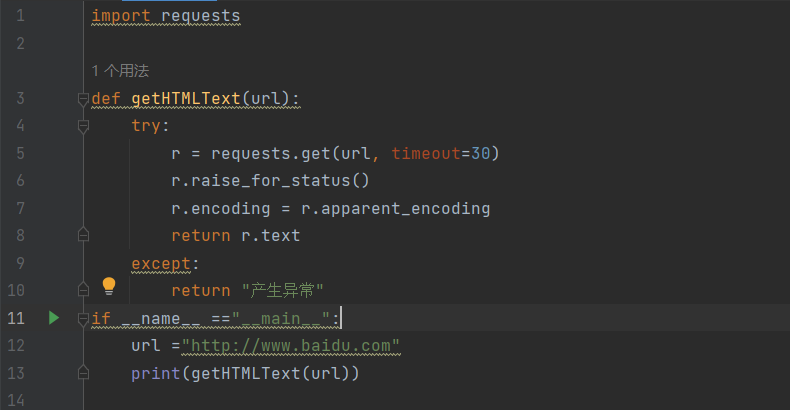
这段代码定义了一个名为getHTMLText的函数,用于从指定 URL 获取 HTML 文本内容。函数尝试 发送 HTTP 请求并处理可能出现的异常,最后返回网页的 HTML 内容或错误提示。主程序中,代码调用这个函数获取百度首页的 HTML 内容并打印输出。
代码结构分析
- 导入模块:导入了
requests库,用于发送 HTTP 请求。 - 定义函数:
getHTMLText(url)函数接收一个 URL 作为参数。 - 异常处理:使用
try-except块捕获并处理可能出现的异常。 - 请求处理:设置超时时间为 30 秒,使用
raise_for_status()检查请求是否成功。 - 编码处理:使用
apparent_encoding确定网页的正确编码。 - 主程序:调用函数并打印结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









