




矩阵的SVD分解- Singular Value Decomposition【矩阵的奇异值分解】
优点:适用于任意形状的矩阵,是 特征分解 在任意矩阵上的推广
分解形式
A = U Σ V T A = U\Sigma V^T A=UΣVT
A = [ ∣ ∣ ∣ u ⃗ 1 u ⃗ 2 . . . u ⃗ m ∣ ∣ ∣ ] [ σ 1 σ 2 0 . . . 0 σ r 0 0 ] [ − v ⃗ 1 − − v ⃗ 2 − − v ⃗ n − ] A = \begin{bmatrix} |&|& &| \\ \vec u_1&\vec u_2&...&\vec u_m \\ |&|& &| \end{bmatrix} \begin{bmatrix} \sigma _1&&&& \\ &\sigma _2&&&0 \\ &&...&& \\ 0&&&\sigma _r& \\ &0&&&0 \end{bmatrix}\begin{bmatrix} - & \vec v_1 & - \\ - & \vec v_2 & - \\ \\ - & \vec v_n & - \end{bmatrix} A= ∣u1∣∣u2∣...∣um∣ σ10σ20...σr00 −−−v1v2vn−−−
对于 m ∗ n m*n m∗n的 A A A矩阵,则 U U U是 m ∗ m m*m m∗m的方阵(左奇异矩阵); Σ \Sigma Σ是 m ∗ n m*n m∗n的长方阵(奇异值矩阵); V V V是 n ∗ n n*n n∗n的方阵(右奇异矩阵)V V V是 A T A A^TA ATA的标准化特征向量矩阵,是一个标准正交矩阵, V = V T V = V^{T} V=VT
U U U是 A A A的列空间的一组标准正交基构成的矩阵 U = [ ∣ ∣ ∣ u ⃗ 1 u ⃗ 2 . . . u ⃗ m ∣ ∣ ∣ ] U = \begin{bmatrix} |&|& &| \\ \vec u_1&\vec u_2&...&\vec u_m \\ |&|& &| \end{bmatrix} U= ∣u1∣∣u2∣...∣um∣ 由前 r r r个从大到小排列的奇异值且不为零的奇异值对应的 u ⃗ \vec u u向量从左到右排列构成,根据矩阵的列空间定义 ( r ≤ m ) (r \le m) (r≤m), u ⃗ i = A v ⃗ i σ i σ i ≠ 0 \vec u_i=\frac {A\vec v_i}{\sigma _i} \ \sigma_i \ne 0 ui=σiAvi σi=0;所以当 r < m r \lt m r<m的时候要构造一个 m ∗ m m*m m∗m的方阵 U U U需要补充到 m m m个 u ⃗ \vec u u向量,缺失的 u ⃗ \vec u u向量可以通过 Gram-Schmidt 方法找到 m − r m-r m−r个向量,使得这 m m m个 u ⃗ \vec u u向量两两互相垂直。所以 U U U矩阵也是一个标准正交矩阵。
\,
Σ \Sigma Σ 矩阵是一个 m ∗ n m*n m∗n奇异值矩阵,对角线由从大到小排列的奇异值按从上到小的顺序填充而成,由于 r ≤ m r \le m r≤m,缺失行由零向量填充,其左上角是一个 r ∗ r r*r r∗r对角矩阵
Σ = [ σ 1 σ 2 0 . . . 0 σ r 0 0 ] = [ D 0 0 0 ] \Sigma = \begin{bmatrix} \sigma _1&&&& \\ &\sigma _2&&&0 \\ &&...&& \\ 0&&&\sigma _r& \\ &0&&&0 \end{bmatrix} \ = \begin{bmatrix} D&0 \\ 0&0\end{bmatrix} Σ= σ10σ20...σr00 =[D000]
\,
SVD与特征值分解的联系: A T A = ( U Σ V T ) T ⋅ ( U Σ V T ) = V T Σ 2 V = P D P T A^TA = (U\Sigma V^T)^T \cdot (U\Sigma V^T) = V^T\Sigma^2V = PDP^T ATA=(UΣVT)T⋅(UΣVT)=VTΣ2V=PDPT
证明
对于
A
=
U
Σ
V
T
A = U\Sigma V^T
A=UΣVT
左乘
V
V
V则有
A
V
=
U
Σ
V
T
V
AV = U\Sigma V^TV
AV=UΣVTV,标准正交矩阵中$V^TV = I \rightarrow AV = U\Sigma $ ,该数学形式与方阵特征值分解类似。
∵
v
⃗
i
\because \vec v_i
∵vi 是
A
T
A
A^TA
ATA的标准特征向量 ,
A
V
=
A
[
∣
∣
∣
v
⃗
1
v
⃗
2
.
.
.
v
⃗
n
∣
∣
∣
]
=
[
∣
∣
∣
A
v
⃗
1
A
v
⃗
2
.
.
.
A
v
⃗
n
∣
∣
∣
]
AV =A \begin{bmatrix} |&|& &| \\ \vec v_1&\vec v_2&...&\vec v_n \\ |&|& &| \end{bmatrix} = \begin{bmatrix} |&|& &| \\ A\vec v_1&A\vec v_2&...&A\vec v_n \\ |&|& &| \end{bmatrix}
AV=A
∣v1∣∣v2∣...∣vn∣
=
∣Av1∣∣Av2∣...∣Avn∣
又
u
⃗
i
=
A
v
⃗
i
σ
i
\vec u_i = \frac {A\vec v_i}{\sigma _i}
ui=σiAvi,其中
σ
i
=
∥
A
⋅
v
⃗
i
∥
2
=
λ
i
\sigma _i = \sqrt { \|A \cdot \vec v_i\|^{2} } = \sqrt {\lambda _i}
σi=∥A⋅vi∥2=λi,当存在
σ
=
0
→
σ
u
⃗
=
0
\sigma = 0 \rightarrow \sigma \vec u = 0
σ=0→σu=0,从而
A
V
=
[
∣
∣
∣
A
v
⃗
1
A
v
⃗
2
.
.
.
A
v
⃗
n
∣
∣
∣
]
=
[
∣
∣
∣
σ
1
u
⃗
1
σ
2
u
⃗
2
.
.
.
σ
r
u
⃗
r
.
.
.
0
∣
∣
∣
]
AV = \begin{bmatrix} |&|& &| \\ A\vec v_1&A\vec v_2&...&A\vec v_n \\ |&|& &| \end{bmatrix} = \begin{bmatrix} |&|& &| \\ \sigma_1\vec u_1& \sigma_2\vec u_2&...& \sigma_r\vec u_r&...&0 \\ |&|& &| \end{bmatrix}
AV=
∣Av1∣∣Av2∣...∣Avn∣
=
∣σ1u1∣∣σ2u2∣...∣σrur∣...0
U Σ = [ ∣ ∣ ∣ u ⃗ 1 u ⃗ 2 . . . u ⃗ m ∣ ∣ ∣ ] [ σ 1 σ 2 0 . . . 0 σ r 0 0 ] = [ ∣ ∣ ∣ σ 1 u ⃗ 1 σ 2 u ⃗ 2 . . . σ r u ⃗ r . . . 0 ∣ ∣ ∣ ] U\Sigma = \begin{bmatrix} |&|& &| \\ \vec u_1&\vec u_2&...&\vec u_m \\ |&|& &| \end{bmatrix} \begin{bmatrix} \sigma _1&&&& \\ &\sigma _2&&&0 \\ &&...&& \\ 0&&&\sigma _r& \\ &0&&&0 \end{bmatrix} = \begin{bmatrix} |&|& &| \\ \sigma_1\vec u_1& \sigma_2\vec u_2&...& \sigma_r\vec u_r&...&0 \\ |&|& &| \end{bmatrix} UΣ= ∣u1∣∣u2∣...∣um∣ σ10σ20...σr00 = ∣σ1u1∣∣σ2u2∣...∣σrur∣...0
∴ A V = U Σ → A = U Σ V T \therefore AV = U\Sigma \rightarrow A = U\Sigma V^T ∴AV=UΣ→A=UΣVT
算法过程
对于任意一个矩阵 A A A,求解 U Σ V T U\Sigma V^T UΣVT
step.1 求解 A T A A^TA ATA的特征值和特征向量;
step.2 对 A T A A^TA ATA的非零特征值 λ \lambda λ 进行开根得到奇异值 σ \sigma σ,顺序填充成 m ∗ n m*n m∗n的奇异值矩阵 Σ \Sigma Σ;
step.3 A T A A^TA ATA的特征向量标准化处理后,这些标准特征向量按从大到小的特征值对应关系按列填充成 n ∗ n n*n n∗n的 V V V,取 V T V^T VT;
step.4 u ⃗ i = A v ⃗ i σ i \vec u_i = \frac {A\vec v_i}{\sigma _i} ui=σiAvi在经过Gram-Schmidt扩展填充成 U U U
SVD应用
1.几何坐标变换
A = U Σ V T A = U\Sigma V^T A=UΣVT 若A是 m ∗ n m*n m∗n的矩阵 A A A将对一个 n n n维向量转换成 m m m维的向量;
V V V是 n n n维空间的一组标准正交基,从而 n n n维空间中的任意向量 x ⃗ \vec x x可以被 V V V中的列向量所组合表示 x ⃗ = k 1 v ⃗ 1 + k 2 v ⃗ 2 + . . . + k n v ⃗ n = V k ⃗ \vec x = k_1\vec v_1 + k_2\vec v_2 + ... + k_n\vec v_n=V\vec k x=k1v1+k2v2+...+knvn=Vk ,这里 V k ⃗ V\vec k Vk中的向量 k ⃗ \vec k k即 V V V坐标系下每个维度上的坐标值。
而
n
n
n维空间的向量
x
⃗
\vec x
x被
A
A
A变换将得到:
A
x
⃗
=
U
Σ
V
T
x
⃗
=
U
Σ
V
T
⋅
V
k
⃗
=
U
Σ
k
⃗
=
U
[
σ
1
k
1
.
.
.
σ
r
k
r
0
]
A\vec x = U\Sigma V^T \vec x = U\Sigma V^T \cdot V\vec k = U\Sigma \vec k = U\begin{bmatrix} \sigma_1k_1 \\ ... \\ \sigma_rk_r \\ 0\end{bmatrix}
Ax=UΣVTx=UΣVT⋅Vk=UΣk=U
σ1k1...σrkr0
在这里变换后表明在
U
U
U坐标系下,原来
V
V
V坐标系下的向量
x
⃗
\vec x
x坐标值将被拉伸
σ
\sigma
σ倍。
2.数据压缩去噪降维
奇异值分解与特征值分解的目的一样,都是提取出一个矩阵最重要的特征。
所有的矩阵都可以进行奇异值分解,但只有方阵才可以进行特征值分解。当所给的矩阵是对称的方阵,,二者的结果是相同的。所以对称矩阵的特征值分解是奇异值分解的一个特例。对于奇异值,它跟特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。所以可以应用最大的k个的奇异值和对应的左右奇异矩阵来近似描述矩阵达到 denoise 的目的。
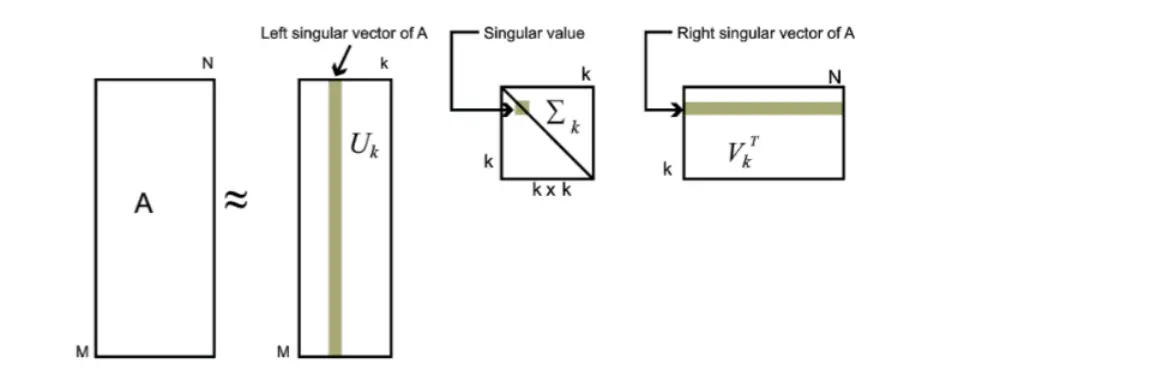
SVD降噪数学展开式
A
=
U
Σ
V
T
A = U\Sigma V^T
A=UΣVT
[
∣
∣
∣
σ
1
u
⃗
1
σ
2
u
⃗
2
.
.
.
σ
r
u
⃗
r
.
.
.
0
∣
∣
∣
]
[
−
v
⃗
1
−
−
v
⃗
2
−
−
v
⃗
n
−
]
=
σ
1
u
⃗
1
v
⃗
1
T
+
σ
2
u
⃗
2
v
⃗
2
T
+
.
.
.
+
σ
r
u
⃗
r
v
⃗
r
T
+
0
+
.
.
.
0
\begin{bmatrix} |&|& &| \\ \sigma_1\vec u_1& \sigma_2\vec u_2&...& \sigma_r\vec u_r&...&0 \\ |&|& &| \end{bmatrix} \begin{bmatrix} - & \vec v_1 & - \\ - & \vec v_2 & - \\ \\ - & \vec v_n & - \end{bmatrix} = \sigma_1 \vec u_1 \vec v_1^T + \sigma_2 \vec u_2 \vec v_2^T +...+\sigma_r \vec u_r \vec v_r^T + 0 +...0
∣σ1u1∣∣σ2u2∣...∣σrur∣...0
−−−v1v2vn−−−
=σ1u1v1T+σ2u2v2T+...+σrurvrT+0+...0
从而 A A A 矩阵被表示为系列由 σ i u ⃗ i v ⃗ i T \sigma _i \vec u_i \vec v_i^T σiuiviT组成的 m ∗ n m*n m∗n矩阵的加和的结果,奇异值 σ \sigma σ在这里成为子矩阵 u ⃗ v ⃗ T \vec u \vec v^T uvT的权重( w e i g h t weight weight 权值),其中第一个 σ 1 \sigma _1 σ1权值最大,次之 σ 2 \sigma _2 σ2,以此类推。所以可知小奇异值对应的子矩阵对 A A A矩阵的影响是很小的,舍去这些小奇异值对应的子矩阵可以做到对 A A A矩阵的压缩、降噪。
3、SVD 与 PCA 降维的联系
PCA降维 主要针对协方差矩阵 X T X X^TX XTX 进行特征分解,找到最大的 d d d 个特征值对应的特征向量作为基向量,对 X X X 进行投影达到降维的目的 X l o w d i m = X ⋅ P X_{lowdim} = X\cdot P Xlowdim=X⋅P。 SVD 则是针对 X X X进行奇异值分解,算的是 X T X X^TX XTX 的特征值和特征向量,从求解上来说SVD与PCA等价,但是SVD 算法求解矩阵 X T X X^TX XTX 的特征向量时相比暴力特征值分解有更高效的计算策略(如幂迭代法求矩阵特征值),当找到了前 d d d 个奇异值对应的右奇异矩阵 V T V^T VT,对 X X X 进行投影达到降维的目的 X l o w d i m = X ⋅ ( V T ) T X_{lowdim} = X \cdot (V^T)^T Xlowdim=X⋅(VT)T,正因如此SVD的这种高效性所,一般PCA算法常用 SVD 求解特征向量。
1.1 矩阵降维之矩阵分解 PCA与SVD - 知乎 (zhihu.com)
【机器学习】这次终于彻底理解了奇异值分解(SVD)原理及应用_风度78的博客-优快云博客



















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











