



 本文详细介绍Pandas库在数据分析中的关键应用,包括数据结构(Series和DataFrame)、数据操作、统计汇总、日期时间处理,以及数据清洗、筛选和转换等实用技巧。通过实例演示如何高效地处理大规模数据,适合数据分析初学者和专业人士。
本文详细介绍Pandas库在数据分析中的关键应用,包括数据结构(Series和DataFrame)、数据操作、统计汇总、日期时间处理,以及数据清洗、筛选和转换等实用技巧。通过实例演示如何高效地处理大规模数据,适合数据分析初学者和专业人士。
Pandas库
-
基于NumPy 的一种工具,为解决数据分析任务而创建的,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
-
基本上你能用Excel或者BI工具进行的数据处理,Pandas也都能实现,而且更快
# 导入pandas库:pip install pandas
import pandas as pd
数据结构:Series、DataFrame
区别
* series,只是一个一维数据结构,它由index和value组成。
* dataframe,是一个二维结构,除了拥有index和value之外,还拥有column。
联系
* dataframe由多个series组成,无论是行还是列,单独拆分出来都是一个series。
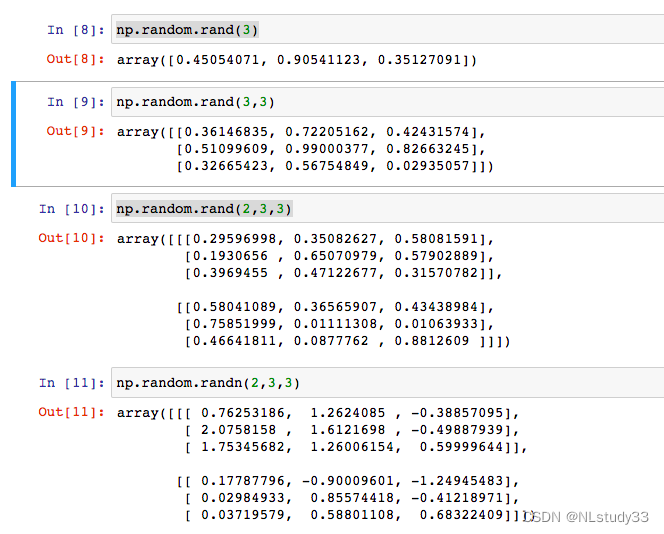
np.random.rand()函数,参数是数组的维度,随机样本取值范围是[0,1),不包括1。
random.randn() 参数是数组的维度,返回一组服从正态分布的随机值
random.randint(low, high=None, size=None, dtype=int)
输入:
low—–为最小值
high—-为最大值
size—–为数组维度大小
dtype—为数据类型,默认的数据类型是np.int。
返回值:
返回随机整数或整型数组,范围区间为[low,high),包含low,不包含high;
high没有填写时,默认生成随机数的范围是[0,low)
# 时间列表,30条,按月变动(间隔30天一个月)
dates = pd.date_range('20210101',periods=30,freq='M')
date2 = pd.date_range('20210101',periods=20,freq='3D') # 间隔3天
# 创建二维表数据,一个dataframe:带时间戳的价格数据
data = pd.DataFrame(np.random.rand(30,3),index=dates,columns=list('ABC'))
# 头部数据,尾部数据
data.head() # 默认是前5行,也可以指定
data.head(2)
# 尾部数据
data.tail()
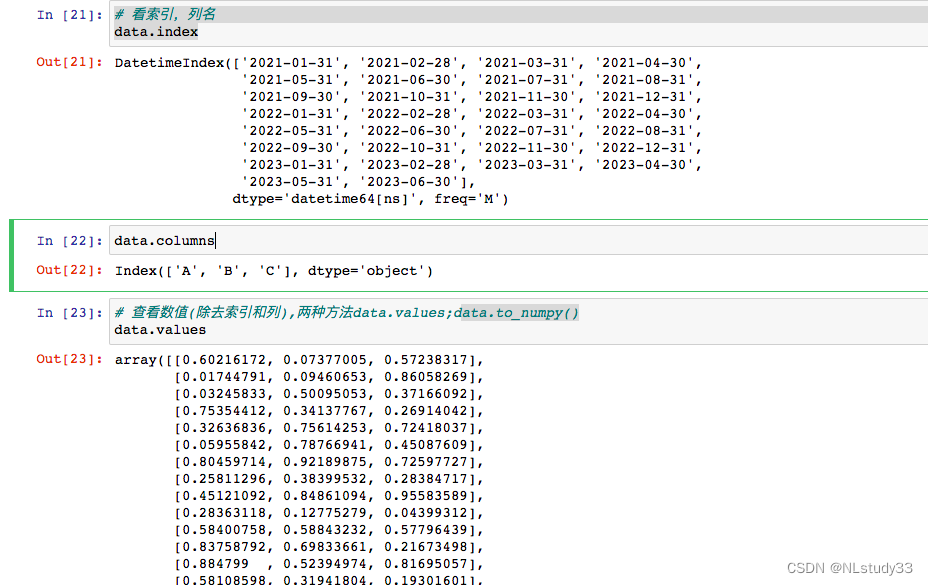
# 查看数值(除去索引和列),两种方法data.values;data.to_numpy()
data.values
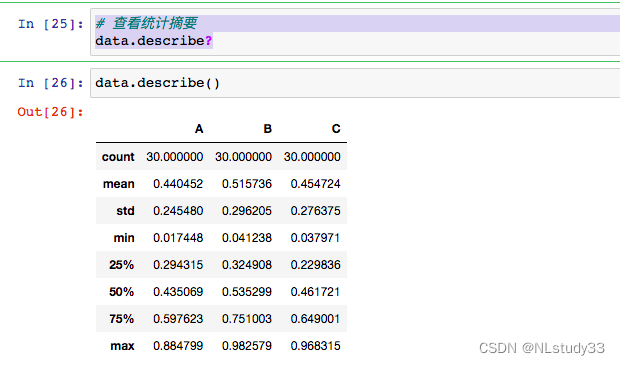
# 查看统计摘要
data.describe()
# 列数据
data['A'] # 单列
data[['A','B']] # 多列
# 行数据,两种方式,data[0:7];data.iloc[0:5];data.loc['20210101':'20211001']
# data.loc[]可以按索引或者列标签筛选
data[0:7] # 使用切片
data.iloc[0:5] # 使用行号
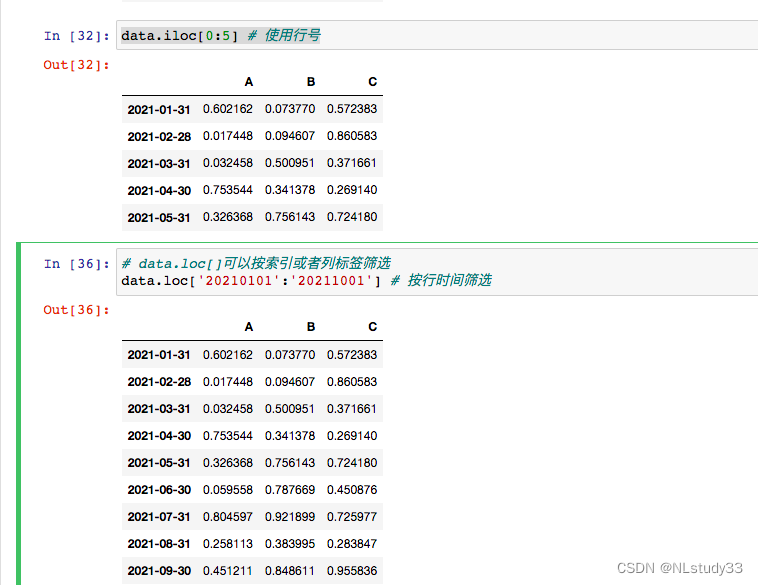
data.loc['20210101':'20211001','A':'B'] # 按行时间筛选+列筛选
data.loc['20210101':'20211001',['A','C']] # 按行时间筛选+列筛选
# 按值筛选
data = round(data,2) # float是很精确的很多位,取小数点后两位,
# 按指定的位数对数值进行四舍五入,语法是ROUND(number, num_digits)
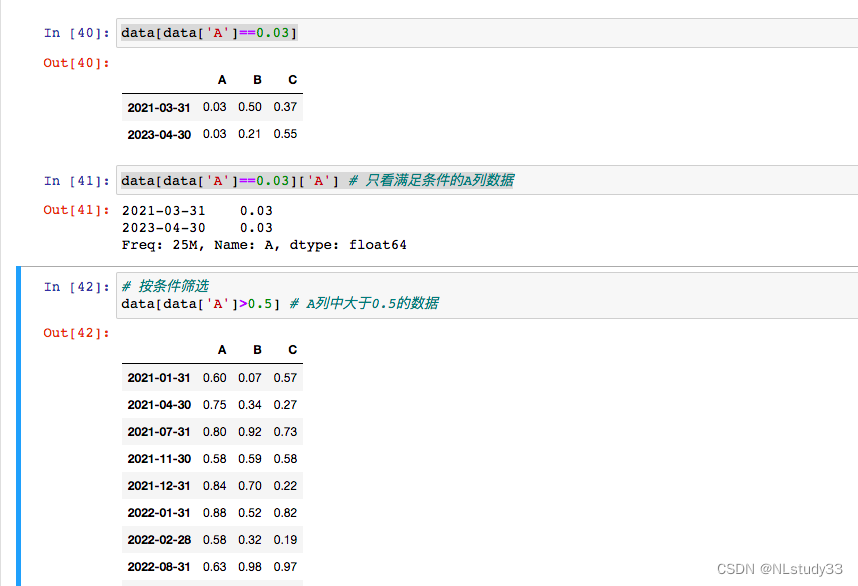
data[data['A']==0.03]
data[data['A']==0.03]['A'] # 只看满足条件的A列数据
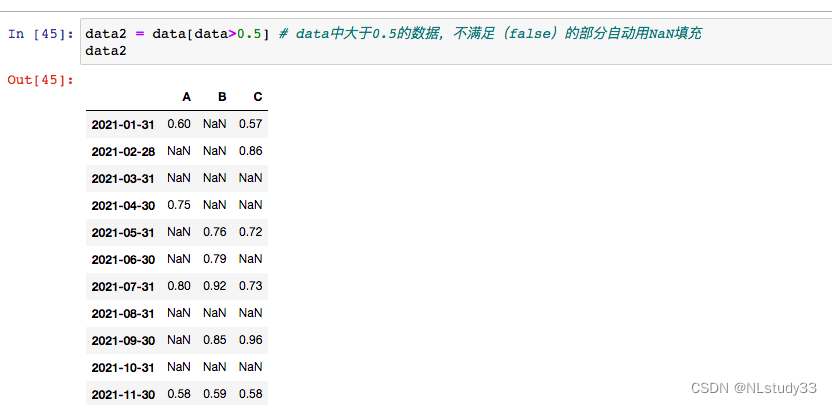 data2 = data[data>0.5] # data中大于0.5的数据,不满足(false)的部分自动用NaN填充
data2 = data[data>0.5] # data中大于0.5的数据,不满足(false)的部分自动用NaN填充
# 去缺失值 (场景,去除包含null的行,都不考虑)
data2.dropna()
# 去除重复值
data.drop_duplicates()
-
去除完全重复的行数据 data.drop_duplicates(inplace=True)
-
去除某几列重复的行数据
data.drop_duplicates(subset=['A','B'],keep='first',inplace=True) subset: 列名,可选,默认为None
keep: {‘first’, ‘last’, False}, 默认值 ‘first’
first: 保留第一次出现的重复行,删除后面的重复行。
last: 删除重复项,除了最后一次出现。
False: 删除所有重复项。
inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。(inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。)
# 转置,排序
data.T
data.sort_values(by='C') # C列升序
data.sort_values(by='B',ascending=False) # B列降序
data.sort_index(ascending=False) # 默认按index排序,降序
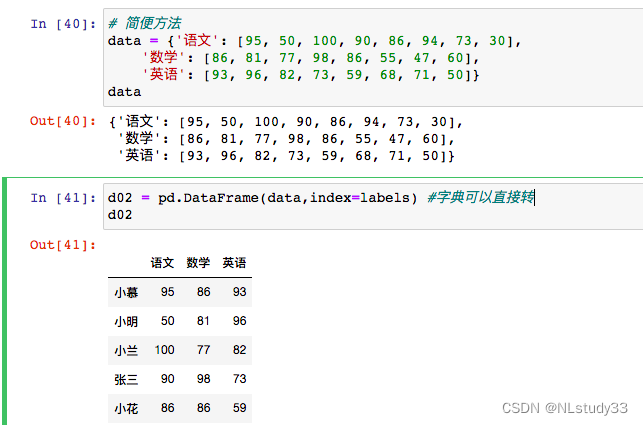
- d02 = pd.DataFrame(data,index=labels)
- 各科成绩都大于60的数据(必须去重)
- score_qualified = d02[d02>60].dropna()
- 每科的平均分数
- d02.mean()
- 每个学生的总成绩,axis=1,按行计算
- d02[‘总分’]=d02.sum(axis=1)
- d02.sort_values(by=‘总分’,ascending=False)

















 8804
8804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









